 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting from Strings: Language Model Embeddings for Bayesian Optimization
Oct 15, 2024


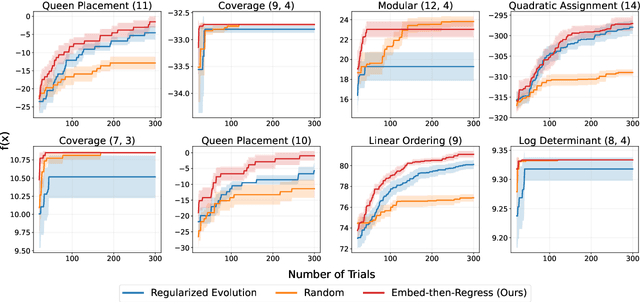
Bayesian Optimization is ubiquitous in the field of experimental design and blackbox optimization for improving search efficiency, but has been traditionally restricted to regression models which are only applicable to fixed search spaces and tabular input features. We propose Embed-then-Regress, a paradigm for applying in-context regression over string inputs, through the use of string embedding capabilities of pretrained language models. By expressing all inputs as strings, we are able to perform general-purpose regression for Bayesian Optimization over various domains including synthetic, combinatorial, and hyperparameter optimization, obtaining comparable results to state-of-the-art Gaussian Process-based algorithms. Code can be found at https://github.com/google-research/optformer/tree/main/optformer/embed_then_regress.
The Vizier Gaussian Process Bandit Algorithm
Aug 21, 2024Google Vizier has performed millions of optimizations and accelerated numerous research and production systems at Google, demonstrating the success of Bayesian optimization as a large-scale service. Over multiple years, its algorithm has been improved considerably, through the collective experiences of numerous research efforts and user feedback. In this technical report, we discuss the implementation details and design choices of the current default algorithm provided by Open Source Vizier. Our experiments on standardized benchmarks reveal its robustness and versatility against well-established industry baselines on multiple practical modes.
OmniPred: Language Models as Universal Regressors
Mar 04, 2024Over the broad landscape of experimental design, regression has been a powerful tool to accurately predict the outcome metrics of a system or model given a set of parameters, but has been traditionally restricted to methods which are only applicable to a specific task. In this paper, we propose OmniPred, a framework for training language models as universal end-to-end regressors over $(x,y)$ evaluation data from diverse real world experiments. Using data sourced from Google Vizier, one of the largest blackbox optimization databases in the world, our extensive experiments demonstrate that through only textual representations of mathematical parameters and values, language models are capable of very precise numerical regression, and if given the opportunity to train over multiple tasks, can significantly outperform traditional regression models.
Open Source Vizier: Distributed Infrastructure and API for Reliable and Flexible Blackbox Optimization
Jul 27, 2022
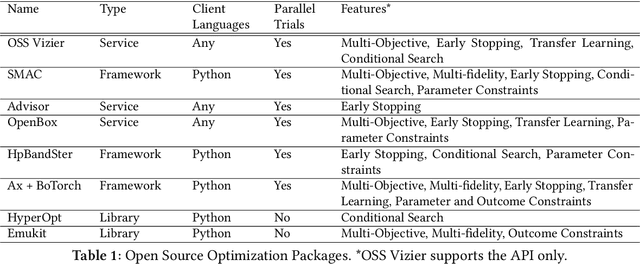

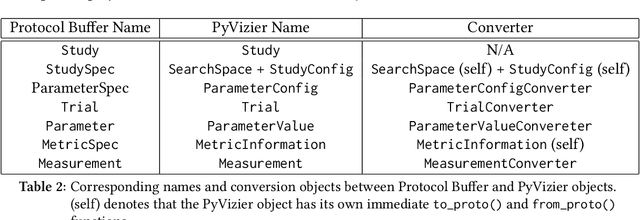
Vizier is the de-facto blackbox and hyperparameter optimization service across Google, having optimized some of Google's largest products and research efforts. To operate at the scale of tuning thousands of users' critical systems, Google Vizier solved key design challenges in providing multiple different features, while remaining fully fault-tolerant. In this paper, we introduce Open Source (OSS) Vizier, a standalone Python-based interface for blackbox optimization and research, based on the Google-internal Vizier infrastructure and framework. OSS Vizier provides an API capable of defining and solving a wide variety of optimization problems, including multi-metric, early stopping, transfer learning, and conditional search. Furthermore, it is designed to be a distributed system that assures reliability, and allows multiple parallel evaluations of the user's objective function. The flexible RPC-based infrastructure allows users to access OSS Vizier from binaries written in any language. OSS Vizier also provides a back-end ("Pythia") API that gives algorithm authors a way to interface new algorithms with the core OSS Vizier system. OSS Vizier is available at https://github.com/google/vizier.
Towards Learning Universal Hyperparameter Optimizers with Transformers
May 26, 2022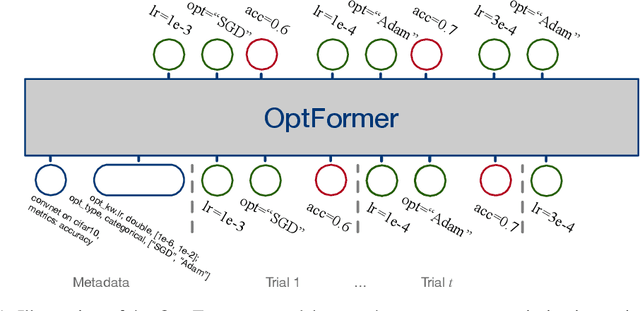


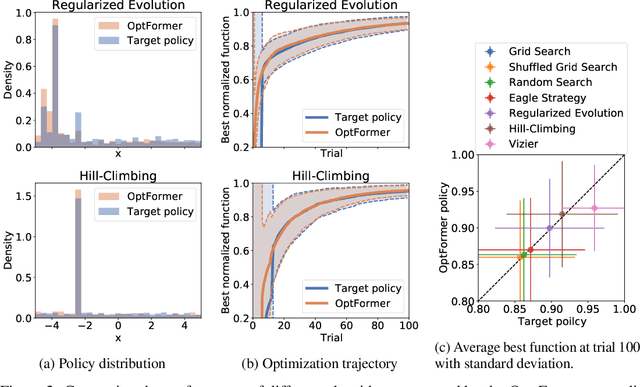
Meta-learning hyperparameter optimization (HPO) algorithms from prior experiments is a promising approach to improve optimization efficiency over objective functions from a similar distribution. However, existing methods are restricted to learning from experiments sharing the same set of hyperparameters. In this paper, we introduce the OptFormer, the first text-based Transformer HPO framework that provides a universal end-to-end interface for jointly learning policy and function prediction when trained on vast tuning data from the wild. Our extensive experiments demonstrate that the OptFormer can imitate at least 7 different HPO algorithms, which can be further improved via its function uncertainty estimates. Compared to a Gaussian Process, the OptFormer also learns a robust prior distribution for hyperparameter response functions, and can thereby provide more accurate and better calibrated predictions. This work paves the path to future extensions for training a Transformer-based model as a general HPO optimizer.
Neural Architecture Search for Energy Efficient Always-on Audio Models
Feb 09, 2022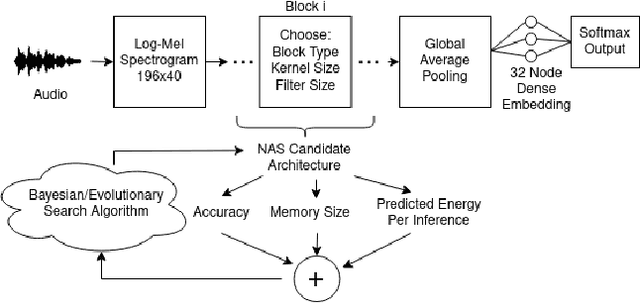
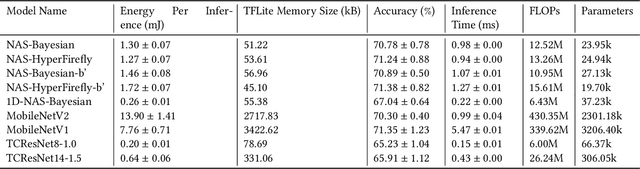
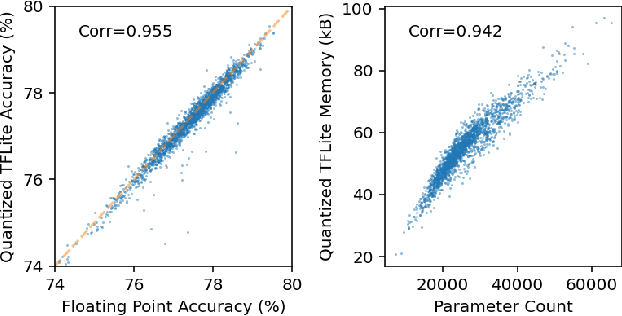
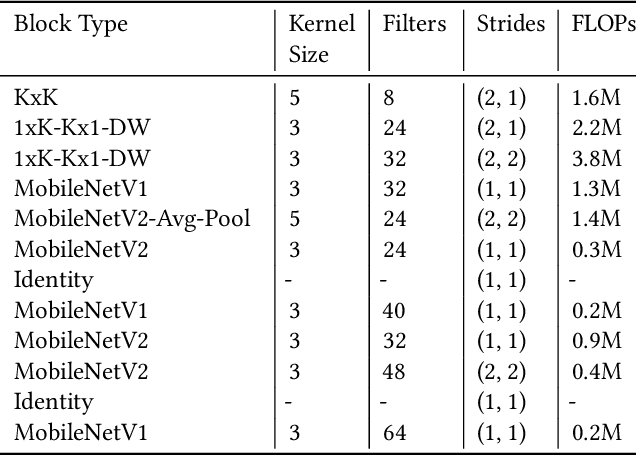
Mobile and edge computing devices for always-on audio classification require energy-efficient neural network architectures. We present a neural architecture search (NAS) that optimizes accuracy, energy efficiency and memory usage. The search is run on Vizier, a black-box optimization service. We present a search strategy that uses both Bayesian and regularized evolutionary search with particle swarms, and employs early-stopping to reduce the computational burden. The search returns architectures for a sound-event classification dataset based upon AudioSet with similar accuracy to MobileNetV1/V2 implementations but with an order of magnitude less energy per inference and a much smaller memory footprint.
A Generalized Framework for Population Based Training
Feb 05, 2019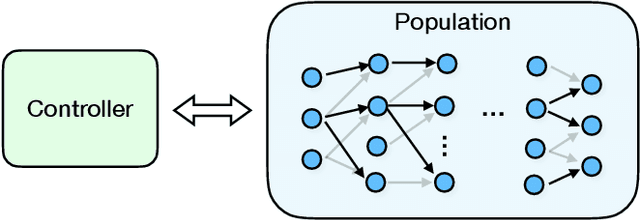
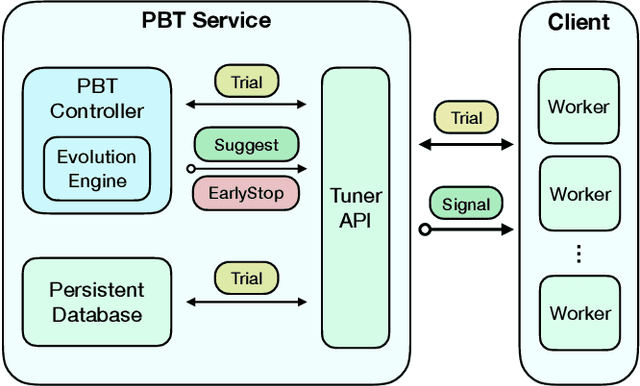

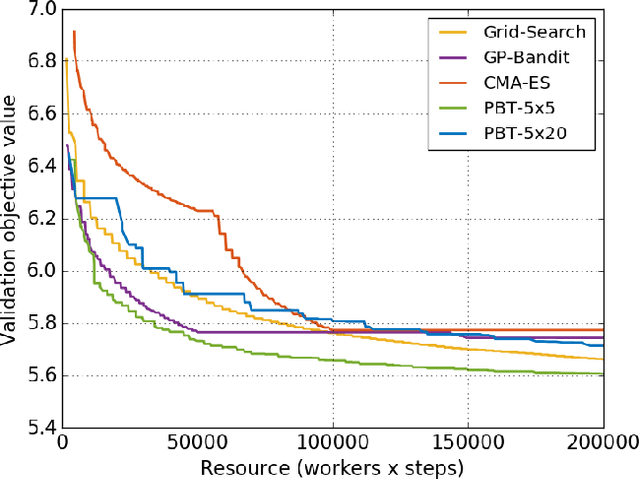
Population Based Training (PBT) is a recent approach that jointly optimizes neural network weights and hyperparameters which periodically copies weights of the best performers and mutates hyperparameters during training. Previous PBT implementations have been synchronized glass-box systems. We propose a general, black-box PBT framework that distributes many asynchronous "trials" (a small number of training steps with warm-starting) across a cluster, coordinated by the PBT controller. The black-box design does not make assumptions on model architectures, loss functions or training procedures. Our system supports dynamic hyperparameter schedules to optimize both differentiable and non-differentiable metrics. We apply our system to train a state-of-the-art WaveNet generative model for human voice synthesis. We show that our PBT system achieves better accuracy, less sensitivity and faster convergence compared to existing methods, given the same computational resource.