 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CARFAC v2 Cochlear Model in Matlab, NumPy, and JAX
Apr 26, 2024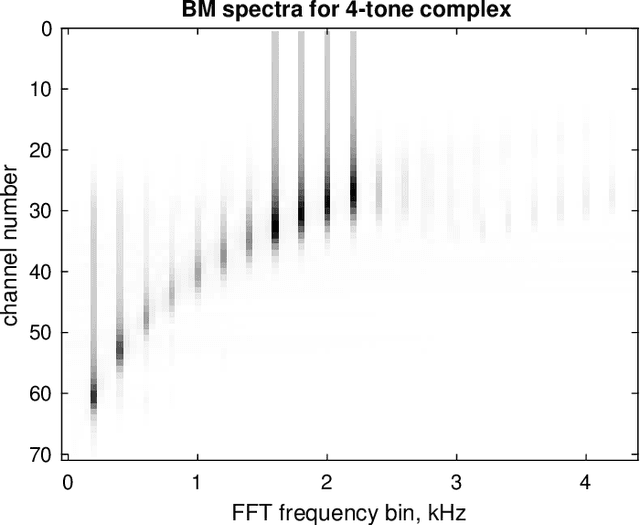

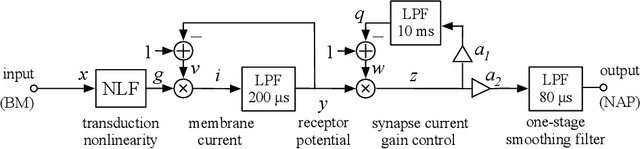
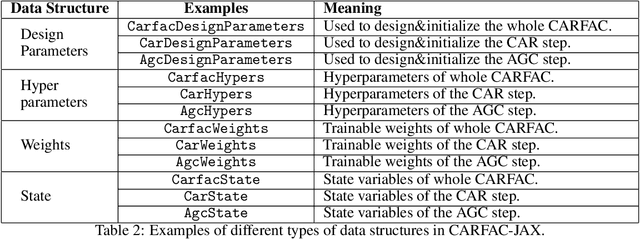
The open-source CARFAC (Cascade of Asymmetric Resonators with Fast-Acting Compression) cochlear model is upgraded to version 2, with improvements to the Matlab implementation, and with new Python/NumPy and JAX implementations -- but C++ version changes are still pending. One change addresses the DC (direct current, or zero frequency) quadratic distortion anomaly previously reported; another reduces the neural synchrony at high frequencies; the others have little or no noticeable effect in the default configuration. A new feature allows modeling a reduction of cochlear amplifier function, as a step toward a differentiable parameterized model of hearing impairment. In addition, the integration into the Auditory Model Toolbox (AMT) has been extensively improved, as the prior integration had bugs that made it unsuitable for including CARFAC in multi-model comparisons.
Disentangling speech from surroundings in a neural audio codec
Mar 29, 2022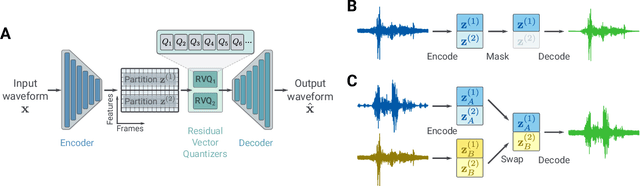
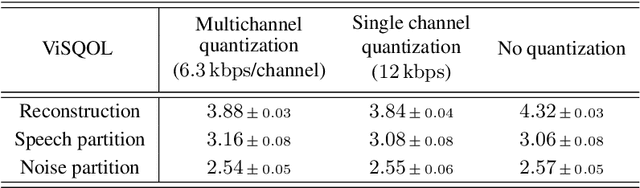
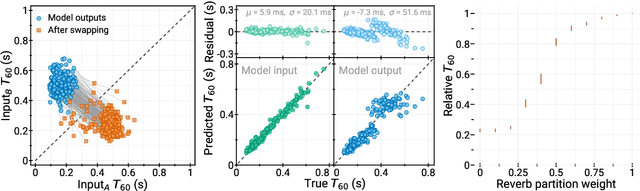
We present a method to separate speech signals from noisy environments in the compressed domain of a neural audio codec. We introduce a new training procedure that allows our model to produce structured encodings of audio waveforms given by embedding vectors, where one part of the embedding vector represents the speech signal, and the rest represents the environment. We achieve this by partitioning the embeddings of different input waveforms and training the model to faithfully reconstruct audio from mixed partitions, thereby ensuring each partition encodes a separate audio attribute. As use cases, we demonstrate the separation of speech from background noise or from reverberation characteristics. Our method also allows for targeted adjustments of the audio output characteristics.
Multi-Channel Speech Denoising for Machine Ears
Feb 17, 2022
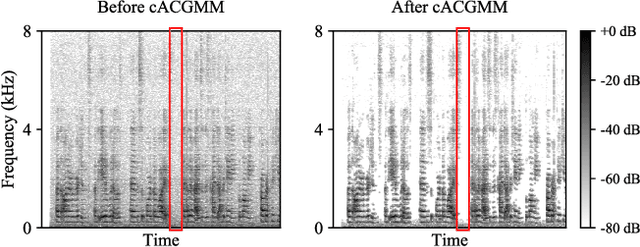


This work describes a speech denoising system for machine ears that aims to improve speech intelligibility and the overall listening experience in noisy environments. We recorded approximately 100 hours of audio data with reverberation and moderate environmental noise using a pair of microphone arrays placed around each of the two ears and then mixed sound recordings to simulate adverse acoustic scenes. Then, we trained a multi-channel speech denoising network (MCSDN) on the mixture of recordings. To improve the training, we employ an unsupervised method, complex angular central Gaussian mixture model (cACGMM), to acquire cleaner speech from noisy recordings to serve as the learning target. We propose a MCSDN-Beamforming-MCSDN framework in the inference stage. The results of the subjective evaluation show that the cACGMM improves the training data, resulting in better noise reduction and user preference, and the entire system improves the intelligibility and listening experience in noisy situations.
Neural Architecture Search for Energy Efficient Always-on Audio Models
Feb 09, 2022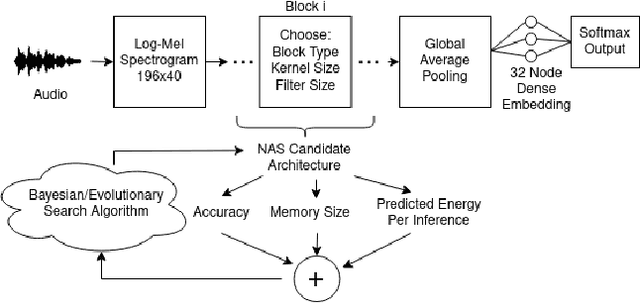
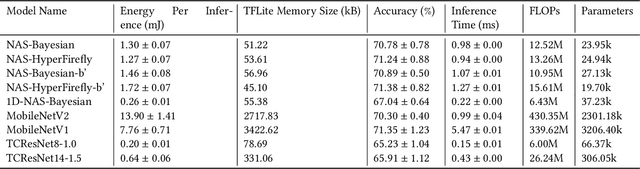
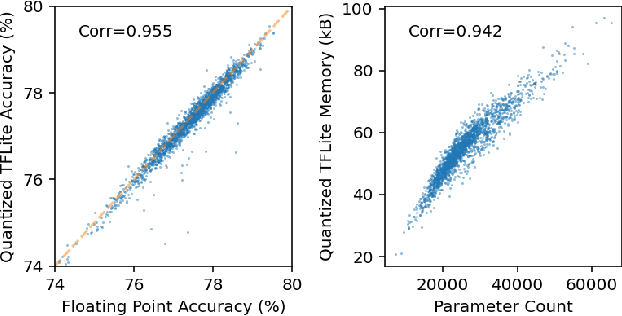
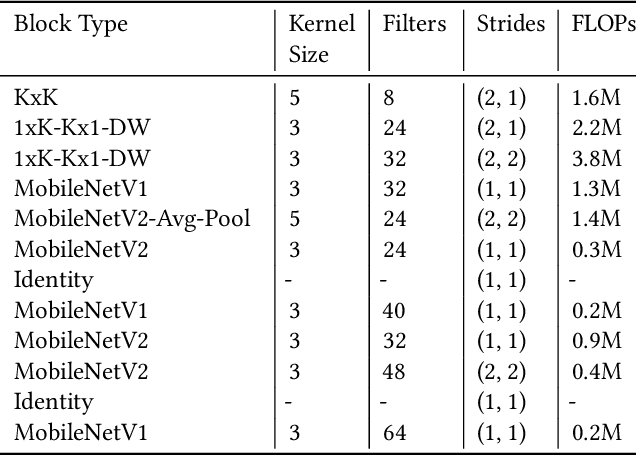
Mobile and edge computing devices for always-on audio classification require energy-efficient neural network architectures. We present a neural architecture search (NAS) that optimizes accuracy, energy efficiency and memory usage. The search is run on Vizier, a black-box optimization service. We present a search strategy that uses both Bayesian and regularized evolutionary search with particle swarms, and employs early-stopping to reduce the computational burden. The search returns architectures for a sound-event classification dataset based upon AudioSet with similar accuracy to MobileNetV1/V2 implementations but with an order of magnitude less energy per inference and a much smaller memory footprint.
Putting a Face to the Voice: Fusing Audio and Visual Signals Across a Video to Determine Speakers
May 31, 2017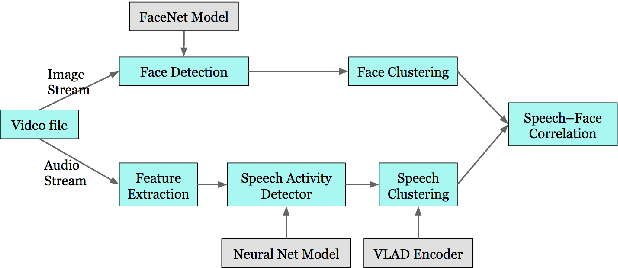
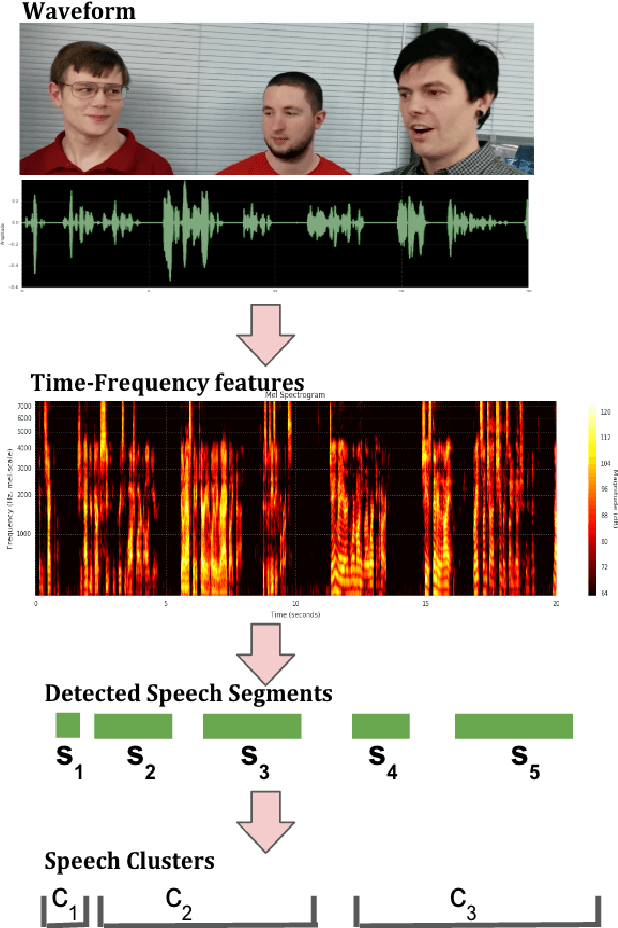
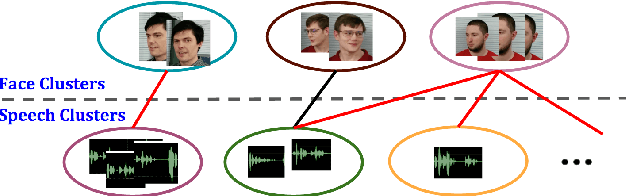
In this paper, we present a system that associates faces with voices in a video by fusing information from the audio and visual signals. The thesis underlying our work is that an extremely simple approach to generating (weak) speech clusters can be combined with visual signals to effectively associate faces and voices by aggregating statistics across a video. This approach does not need any training data specific to this task and leverages the natural coherence of information in the audio and visual streams. It is particularly applicable to tracking speakers in videos on the web where a priori information about the environment (e.g., number of speakers, spatial signals for beamforming) is not available. We performed experiments on a real-world dataset using this analysis framework to determine the speaker in a video. Given a ground truth labeling determined by human rater consensus, our approach had ~71% accuracy.
CNN Architectures for Large-Scale Audio Classification
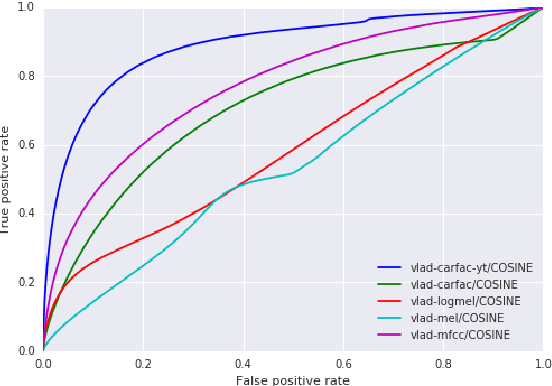
Jan 10, 2017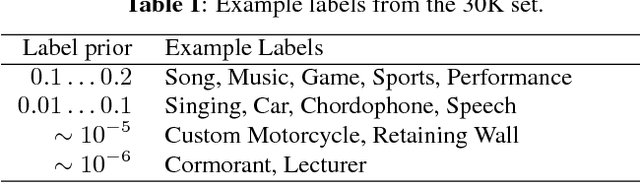
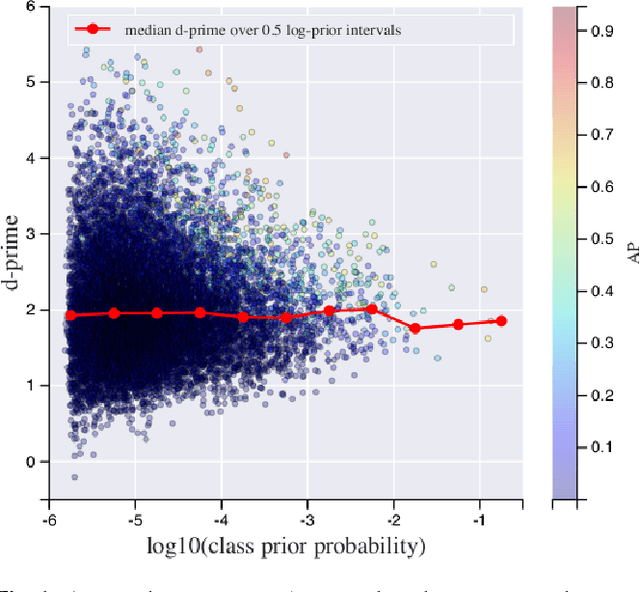
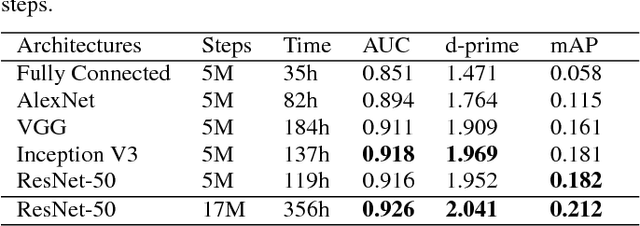
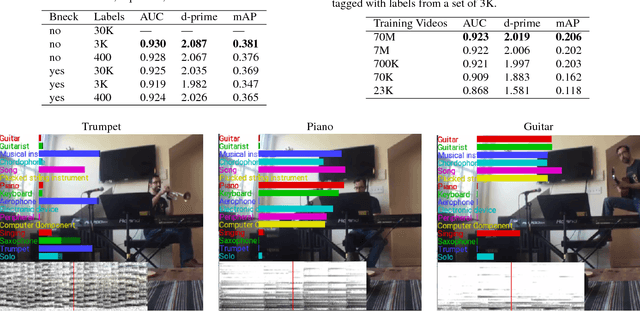
Convolutional Neural Networks (CNNs) have proven very effective in image classification and show promise for audio. We use various CNN architectures to classify the soundtracks of a dataset of 70M training videos (5.24 million hours) with 30,871 video-level labels. We examine fully connected Deep Neural Networks (DNNs), AlexNet [1], VGG [2], Inception [3], and ResNet [4]. We investigate varying the size of both training set and label vocabulary, finding that analogs of the CNNs used in image classification do well on our audio classification task, and larger training and label sets help up to a point. A model using embeddings from these classifiers does much better than raw features on the Audio Set [5] Acoustic Event Detection (AED) classification task.
Collaborative Filtering and the Missing at Random Assumption
Jun 20, 2012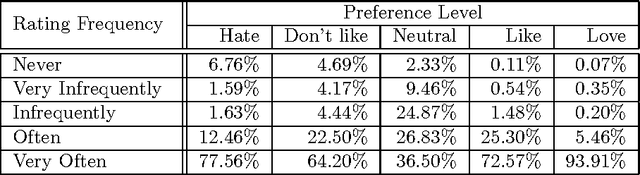
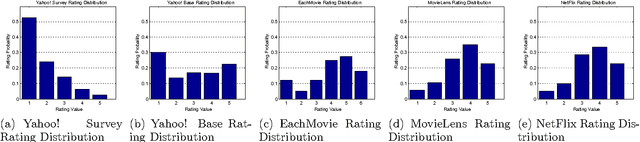
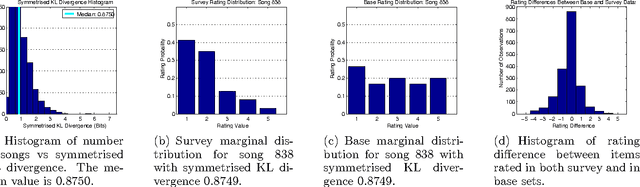

Rating prediction is an important application, and a popular research topic in collaborative filtering. However, both the validity of learning algorithms, and the validity of standard testing procedures rest on the assumption that missing ratings are missing at random (MAR). In this paper we present the results of a user study in which we collect a random sample of ratings from current users of an online radio service. An analysis of the rating data collected in the study shows that the sample of random ratings has markedly different properties than ratings of user-selected songs. When asked to report on their own rating behaviour, a large number of users indicate they believe their opinion of a song does affect whether they choose to rate that song, a violation of the MAR condition. Finally, we present experimental results showing that incorporating an explicit model of the missing data mechanism can lead to significant improvements in prediction performance on the random sample of ratings.