 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective weakly supervised semantic frame induction using expression sharing in hierarchical hidden Markov models
Jan 30, 2019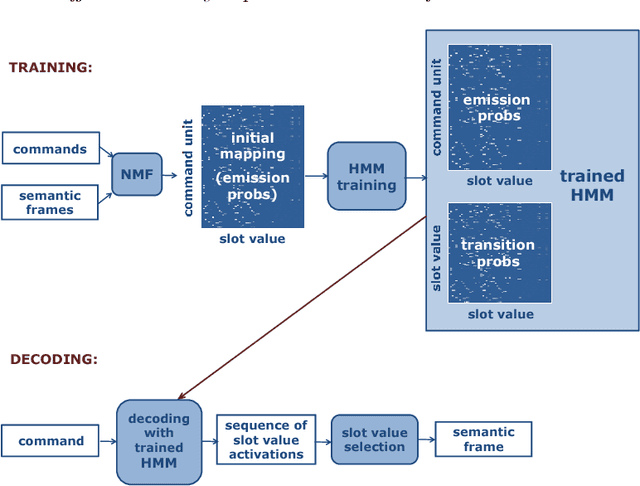
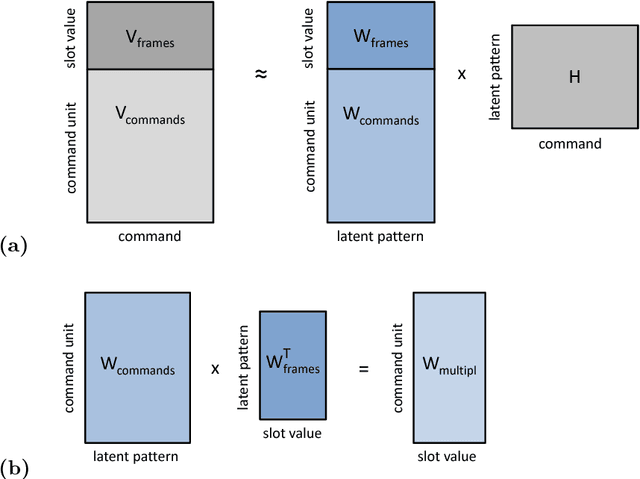
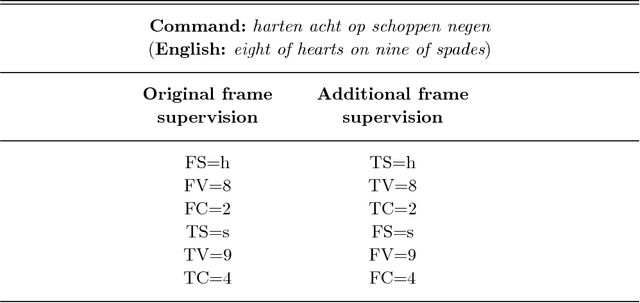
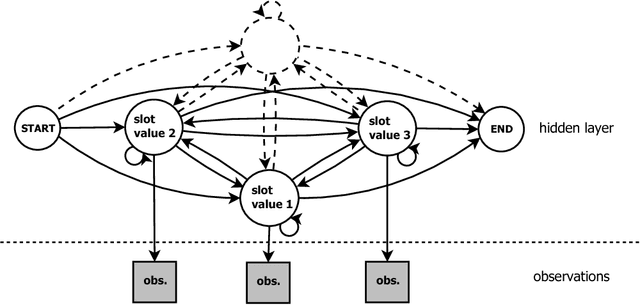
We present a framework for the induction of semantic frames from utterances in the context of an adaptive command-and-control interface. The system is trained on an individual user's utterances and the corresponding semantic frames representing controls. During training, no prior information on the alignment between utterance segments and frame slots and values is available. In addition, semantic frames in the training data can contain information that is not expressed in the utterances. To tackle this weakly supervised classification task, we propose a framework based on Hidden Markov Models (HMMs). Structural modifications, resulting in a hierarchical HMM, and an extension called expression sharing are introduced to minimize the amount of training time and effort required for the user. The dataset used for the present study is PATCOR, which contains commands uttered in the context of a vocally guided card game, Patience. Experiments were carried out on orthographic and phonetic transcriptions of commands, segmented on different levels of n-gram granularity. The experimental results show positive effects of all the studied system extensions, with some effect differences between the different input representations. Moreover, evaluation experiments on held-out data with the optimal system configuration show that the extended system is able to achieve high accuracies with relatively small amounts of training data.
CNN Architectures for Large-Scale Audio Classification
Jan 10, 2017
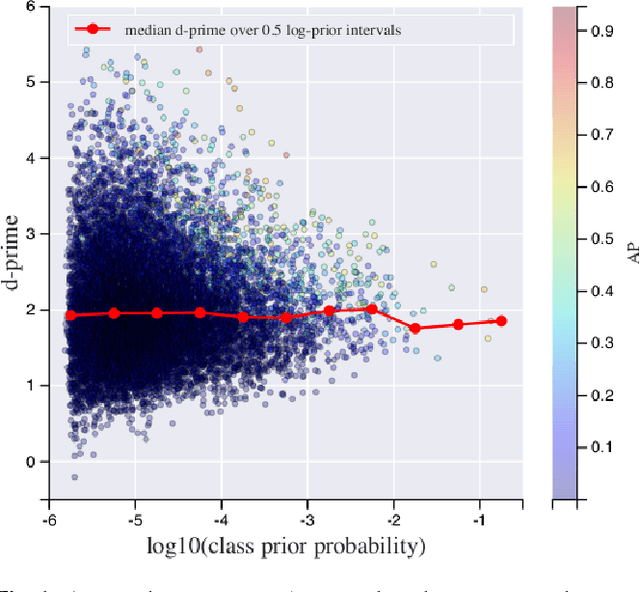
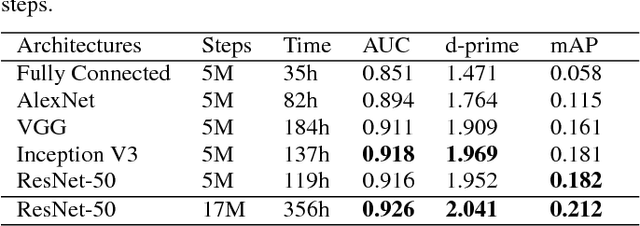
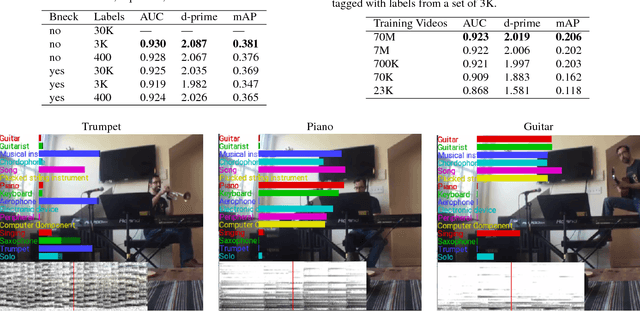
Convolutional Neural Networks (CNNs) have proven very effective in image classification and show promise for audio. We use various CNN architectures to classify the soundtracks of a dataset of 70M training videos (5.24 million hours) with 30,871 video-level labels. We examine fully connected Deep Neural Networks (DNNs), AlexNet [1], VGG [2], Inception [3], and ResNet [4]. We investigate varying the size of both training set and label vocabulary, finding that analogs of the CNNs used in image classification do well on our audio classification task, and larger training and label sets help up to a point. A model using embeddings from these classifiers does much better than raw features on the Audio Set [5] Acoustic Event Detection (AED) classification task.