 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurrent Limitations in Cyberbullying Detection: on Evaluation Criteria, Reproducibility, and Data Scarcity
Oct 25, 2019

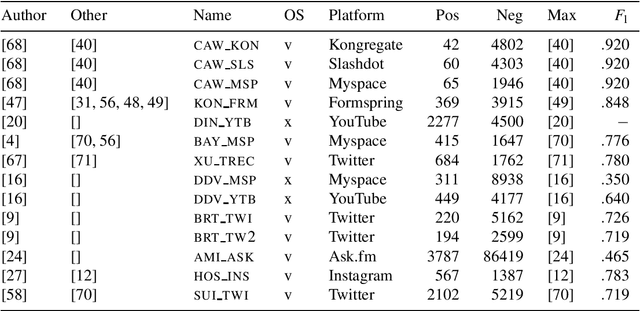
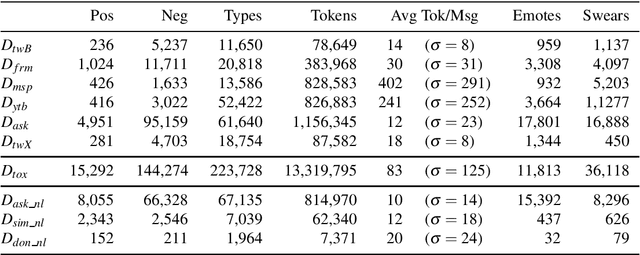
The detection of online cyberbullying has seen an increase in societal importance, popularity in research, and available open data. Nevertheless, while computational power and affordability of resources continue to increase, the access restrictions on high-quality data limit the applicability of state-of-the-art techniques. Consequently, much of the recent research uses small, heterogeneous datasets, without a thorough evaluation of applicability. In this paper, we further illustrate these issues, as we (i) evaluate many publicly available resources for this task and demonstrate difficulties with data collection. These predominantly yield small datasets that fail to capture the required complex social dynamics and impede direct comparison of progress. We (ii) conduct an extensive set of experiments that indicate a general lack of cross-domain generalization of classifiers trained on these sources, and openly provide this framework to replicate and extend our evaluation criteria. Finally, we (iii) present an effective crowdsourcing method: simulating real-life bullying scenarios in a lab setting generates plausible data that can be effectively used to enrich real data. This largely circumvents the restrictions on data that can be collected, and increases classifier performance. We believe these contributions can aid in improving the empirical practices of future research in the field.
A weakly supervised sequence tagging and grammar induction approach to semantic frame slot filling
Jun 15, 2019
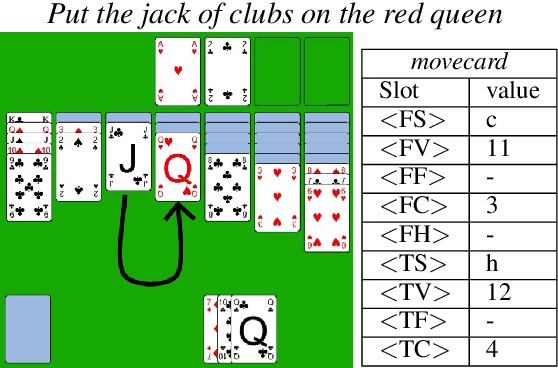
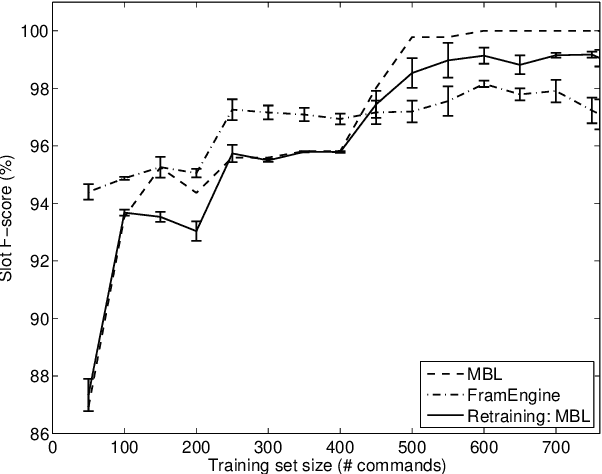
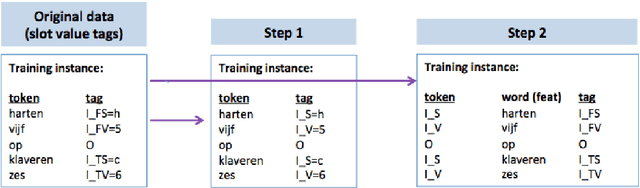
This paper describes continuing work on semantic frame slot filling for a command and control task using a weakly-supervised approach. We investigate the advantages of using retraining techniques that take the output of a hierarchical hidden markov model as input to two inductive approaches: (1) discriminative sequence labelers based on conditional random fields and memory-based learning and (2) probabilistic context-free grammar induction. Experimental results show that this setup can significantly improve F-scores without the need for additional information sources. Furthermore, qualitative analysis shows that the weakly supervised technique is able to automatically induce an easily interpretable and syntactically appropriate grammar for the domain and task at hand.
Effective weakly supervised semantic frame induction using expression sharing in hierarchical hidden Markov models
Jan 30, 2019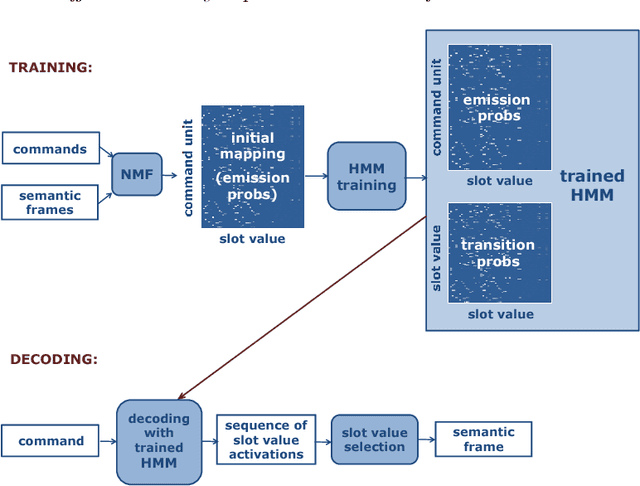
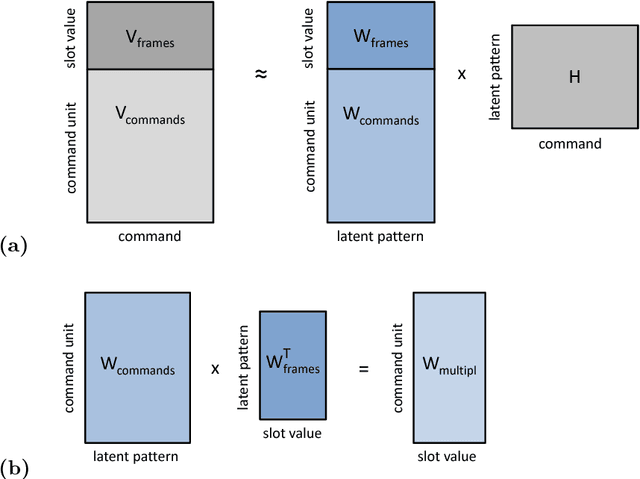
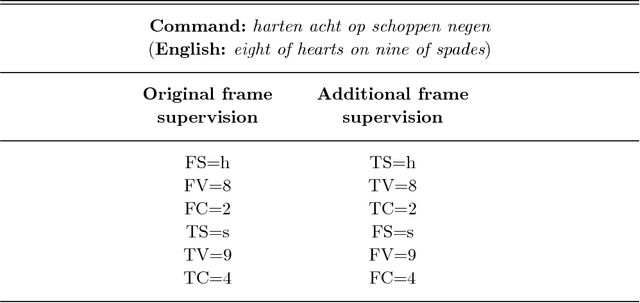
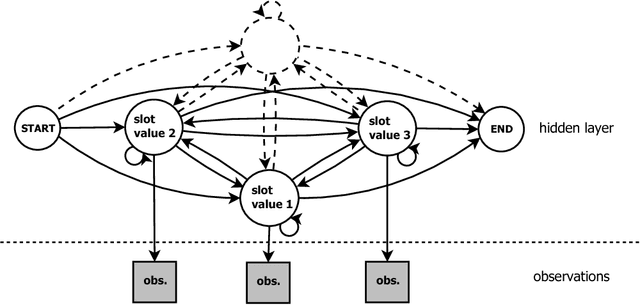
We present a framework for the induction of semantic frames from utterances in the context of an adaptive command-and-control interface. The system is trained on an individual user's utterances and the corresponding semantic frames representing controls. During training, no prior information on the alignment between utterance segments and frame slots and values is available. In addition, semantic frames in the training data can contain information that is not expressed in the utterances. To tackle this weakly supervised classification task, we propose a framework based on Hidden Markov Models (HMMs). Structural modifications, resulting in a hierarchical HMM, and an extension called expression sharing are introduced to minimize the amount of training time and effort required for the user. The dataset used for the present study is PATCOR, which contains commands uttered in the context of a vocally guided card game, Patience. Experiments were carried out on orthographic and phonetic transcriptions of commands, segmented on different levels of n-gram granularity. The experimental results show positive effects of all the studied system extensions, with some effect differences between the different input representations. Moreover, evaluation experiments on held-out data with the optimal system configuration show that the extended system is able to achieve high accuracies with relatively small amounts of training data.
Multilingual Cross-domain Perspectives on Online Hate Speech
Sep 11, 2018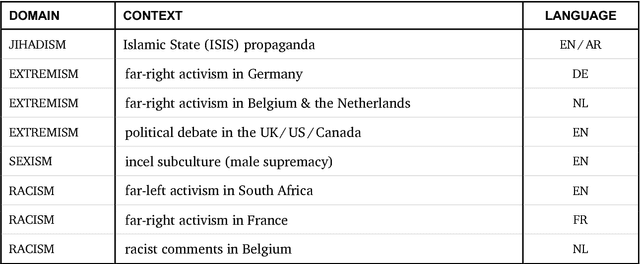

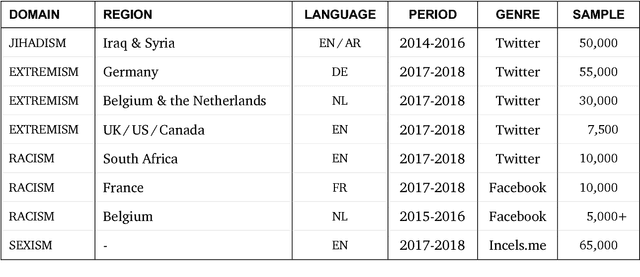
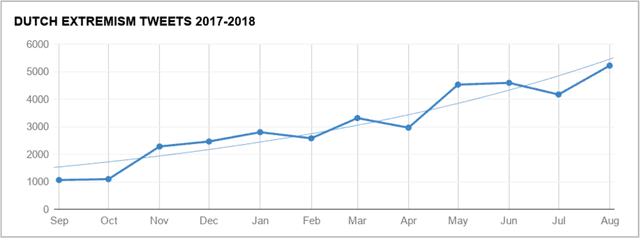
In this report, we present a study of eight corpora of online hate speech, by demonstrating the NLP techniques that we used to collect and analyze the jihadist, extremist, racist, and sexist content. Analysis of the multilingual corpora shows that the different contexts share certain characteristics in their hateful rhetoric. To expose the main features, we have focused on text classification, text profiling, keyword and collocation extraction, along with manual annotation and qualitative study.
* 24 pages
Automatic Detection of Online Jihadist Hate Speech
Mar 13, 2018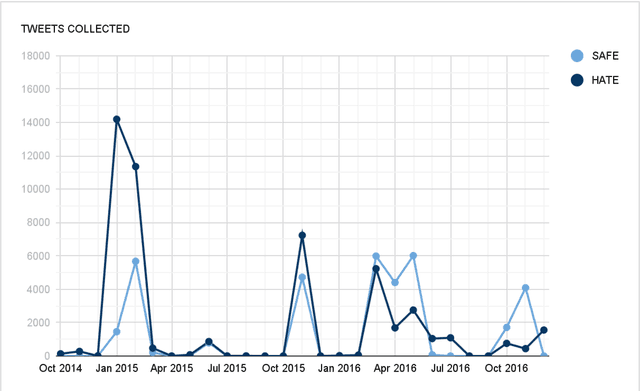
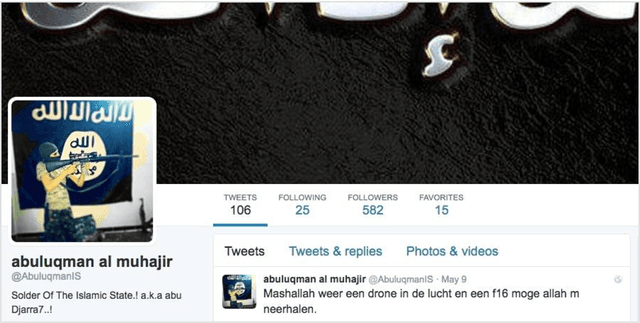
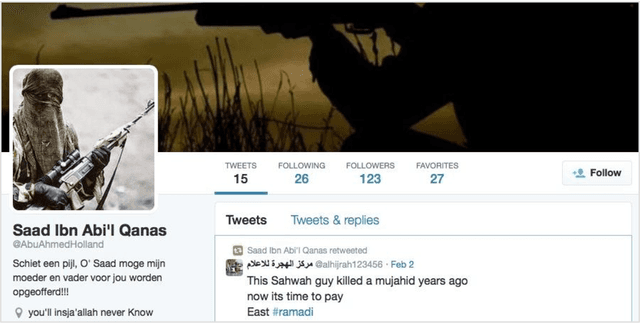
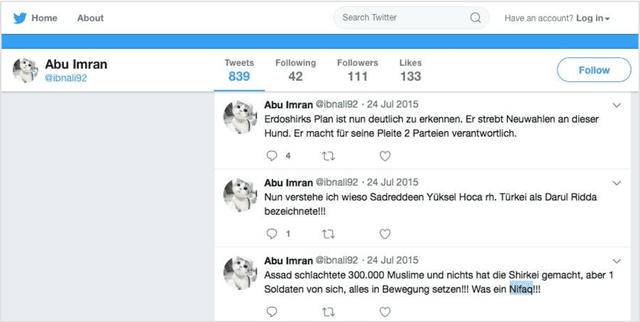
We have developed a system that automatically detects online jihadist hate speech with over 80% accuracy, by using techniques from Natural Language Processing and Machine Learning. The system is trained on a corpus of 45,000 subversive Twitter messages collected from October 2014 to December 2016. We present a qualitative and quantitative analysis of the jihadist rhetoric in the corpus, examine the network of Twitter users, outline the technical procedure used to train the system, and discuss examples of use.
* 31 pages
Automatic Detection of Cyberbullying in Social Media Text
Jan 17, 2018



While social media offer great communication opportunities, they also increase the vulnerability of young people to threatening situations online. Recent studies report that cyberbullying constitutes a growing problem among youngsters. Successful prevention depends on the adequate detection of potentially harmful messages and the information overload on the Web requires intelligent systems to identify potential risks automatically. The focus of this paper is on automatic cyberbullying detection in social media text by modelling posts written by bullies, victims, and bystanders of online bullying. We describe the collection and fine-grained annotation of a training corpus for English and Dutch and perform a series of binary classification experiments to determine the feasibility of automatic cyberbullying detection. We make use of linear support vector machines exploiting a rich feature set and investigate which information sources contribute the most for this particular task. Experiments on a holdout test set reveal promising results for the detection of cyberbullying-related posts. After optimisation of the hyperparameters, the classifier yields an F1-score of 64% and 61% for English and Dutch respectively, and considerably outperforms baseline systems based on keywords and word unigrams.
Aspects of Pattern-Matching in Data-Oriented Parsing
Aug 18, 2000
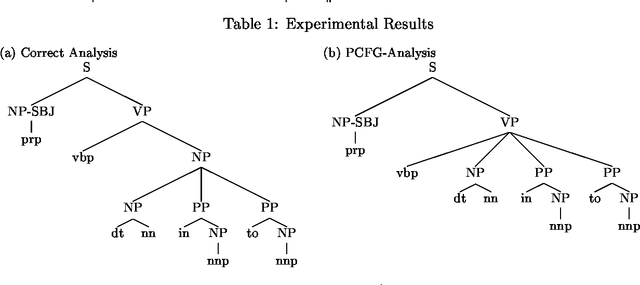
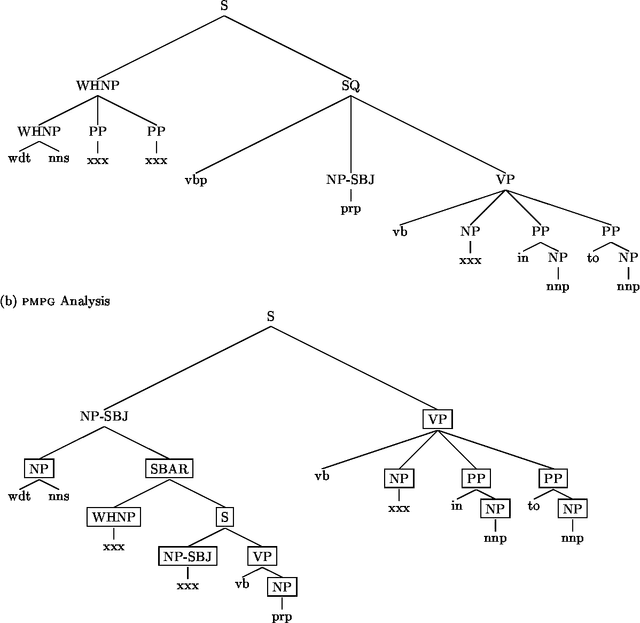
Data-Oriented Parsing (dop) ranks among the best parsing schemes, pairing state-of-the art parsing accuracy to the psycholinguistic insight that larger chunks of syntactic structures are relevant grammatical and probabilistic units. Parsing with the dop-model, however, seems to involve a lot of CPU cycles and a considerable amount of double work, brought on by the concept of multiple derivations, which is necessary for probabilistic processing, but which is not convincingly related to a proper linguistic backbone. It is however possible to re-interpret the dop-model as a pattern-matching model, which tries to maximize the size of the substructures that construct the parse, rather than the probability of the parse. By emphasizing this memory-based aspect of the dop-model, it is possible to do away with multiple derivations, opening up possibilities for efficient Viterbi-style optimizations, while still retaining acceptable parsing accuracy through enhanced context-sensitivity.
* 7 pages, 3 figures