 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Generalizability of Depression Detection by Leveraging Clinical Questionnaires
Apr 21, 2022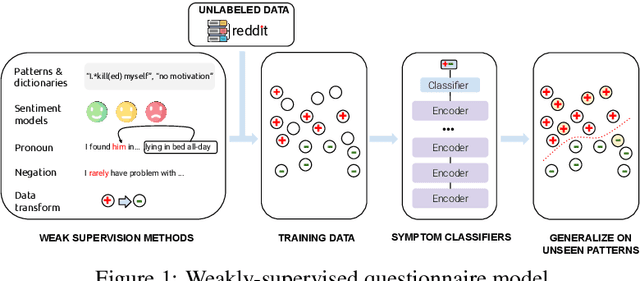


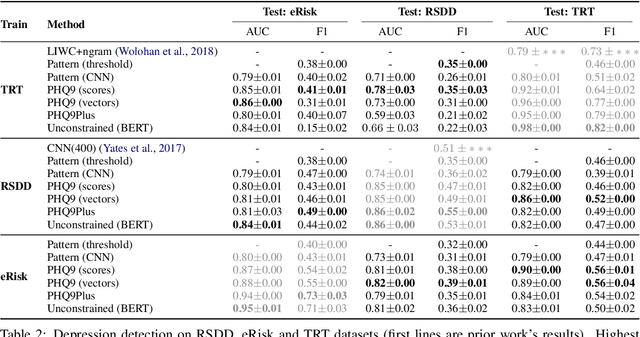
Automated methods have been widely used to identify and analyze mental health conditions (e.g., depression) from various sources of information, including social media. Yet, deployment of such models in real-world healthcare applications faces challenges including poor out-of-domain generalization and lack of trust in black box models. In this work, we propose approaches for depression detection that are constrained to different degrees by the presence of symptoms described in PHQ9, a questionnaire used by clinicians in the depression screening process. In dataset-transfer experiments on three social media datasets, we find that grounding the model in PHQ9's symptoms substantially improves its ability to generalize to out-of-distribution data compared to a standard BERT-based approach. Furthermore, this approach can still perform competitively on in-domain data. These results and our qualitative analyses suggest that grounding model predictions in clinically-relevant symptoms can improve generalizability while producing a model that is easier to inspect.
Sparse encoding for more-interpretable feature-selecting representations in probabilistic matrix factorization
Dec 29, 2020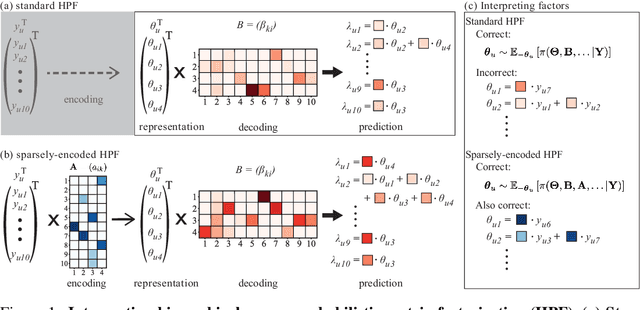
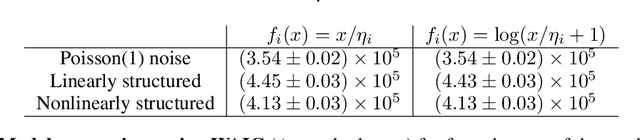
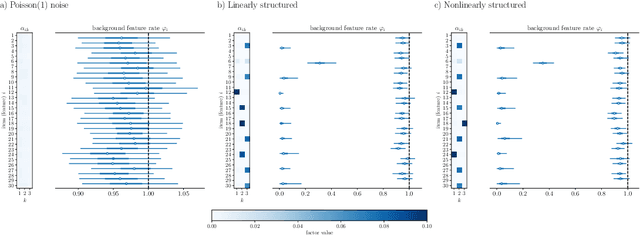
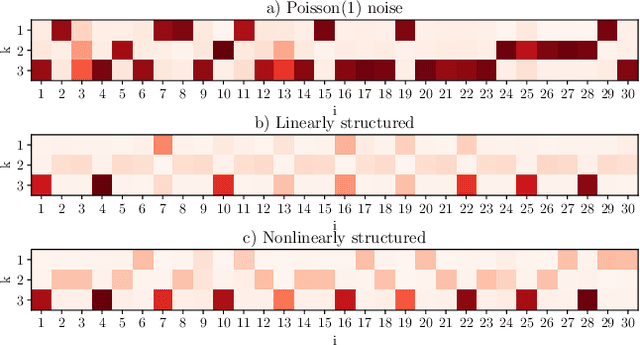
Dimensionality reduction methods for count data are critical to a wide range of applications in medical informatics and other fields where model interpretability is paramount. For such data, hierarchical Poisson matrix factorization (HPF) and other sparse probabilistic non-negative matrix factorization (NMF) methods are considered to be interpretable generative models. They consist of sparse transformations for decoding their learned representations into predictions. However, sparsity in representation decoding does not necessarily imply sparsity in the encoding of representations from the original data features. HPF is often incorrectly interpreted in the literature as if it possesses encoder sparsity. The distinction between decoder sparsity and encoder sparsity is subtle but important. Due to the lack of encoder sparsity, HPF does not possess the column-clustering property of classical NMF -- the factor loading matrix does not sufficiently define how each factor is formed from the original features. We address this deficiency by self-consistently enforcing encoder sparsity, using a generalized additive model (GAM), thereby allowing one to relate each representation coordinate to a subset of the original data features. In doing so, the method also gains the ability to perform feature selection. We demonstrate our method on simulated data and give an example of how encoder sparsity is of practical use in a concrete application of representing inpatient comorbidities in Medicare patients.
Current Limitations in Cyberbullying Detection: on Evaluation Criteria, Reproducibility, and Data Scarcity
Oct 25, 2019

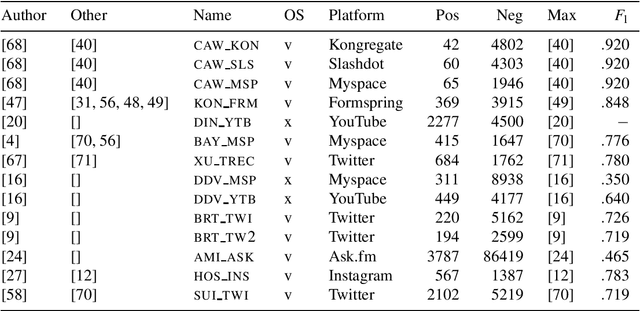
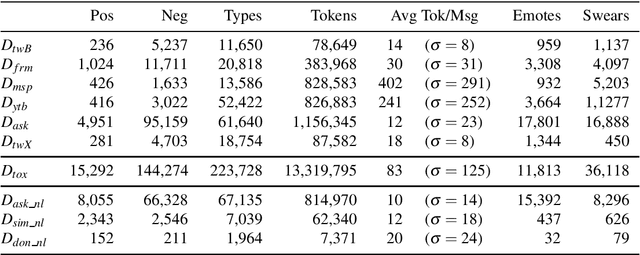
The detection of online cyberbullying has seen an increase in societal importance, popularity in research, and available open data. Nevertheless, while computational power and affordability of resources continue to increase, the access restrictions on high-quality data limit the applicability of state-of-the-art techniques. Consequently, much of the recent research uses small, heterogeneous datasets, without a thorough evaluation of applicability. In this paper, we further illustrate these issues, as we (i) evaluate many publicly available resources for this task and demonstrate difficulties with data collection. These predominantly yield small datasets that fail to capture the required complex social dynamics and impede direct comparison of progress. We (ii) conduct an extensive set of experiments that indicate a general lack of cross-domain generalization of classifiers trained on these sources, and openly provide this framework to replicate and extend our evaluation criteria. Finally, we (iii) present an effective crowdsourcing method: simulating real-life bullying scenarios in a lab setting generates plausible data that can be effectively used to enrich real data. This largely circumvents the restrictions on data that can be collected, and increases classifier performance. We believe these contributions can aid in improving the empirical practices of future research in the field.
Classifying the reported ability in clinical mobility descriptions
Jun 07, 2019
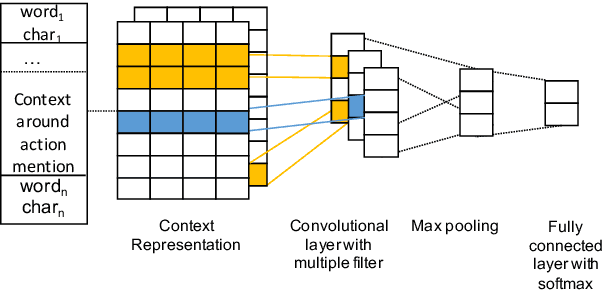


Assessing how individuals perform different activities is key information for modeling health states of individuals and populations. Descriptions of activity performance in clinical free text are complex, including syntactic negation and similarities to textual entailment tasks. We explore a variety of methods for the novel task of classifying four types of assertions about activity performance: Able, Unable, Unclear, and None (no information). We find that ensembling an SVM trained with lexical features and a CNN achieves 77.9% macro F1 score on our task, and yields nearly 80% recall on the rare Unclear and Unable samples. Finally, we highlight several challenges in classifying performance assertions, including capturing information about sources of assistance, incorporating syntactic structure and negation scope, and handling new modalities at test time. Our findings establish a strong baseline for this novel task, and identify intriguing areas for further research.
SMHD: A Large-Scale Resource for Exploring Online Language Usage for Multiple Mental Health Conditions
Jul 10, 2018

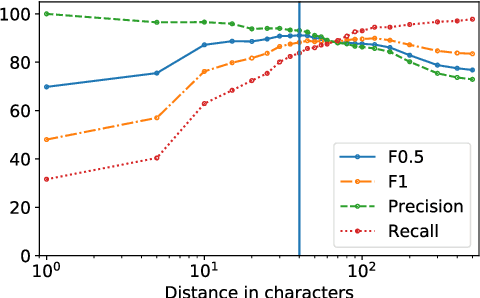

Mental health is a significant and growing public health concern. As language usage can be leveraged to obtain crucial insights into mental health conditions, there is a need for large-scale, labeled, mental health-related datasets of users who have been diagnosed with one or more of such conditions. In this paper, we investigate the creation of high-precision patterns to identify self-reported diagnoses of nine different mental health conditions, and obtain high-quality labeled data without the need for manual labelling. We introduce the SMHD (Self-reported Mental Health Diagnoses) dataset and make it available. SMHD is a novel large dataset of social media posts from users with one or multiple mental health conditions along with matched control users. We examine distinctions in users' language, as measured by linguistic and psychological variables. We further explore text classification methods to identify individuals with mental conditions through their language.
RSDD-Time: Temporal Annotation of Self-Reported Mental Health Diagnoses
Jun 20, 2018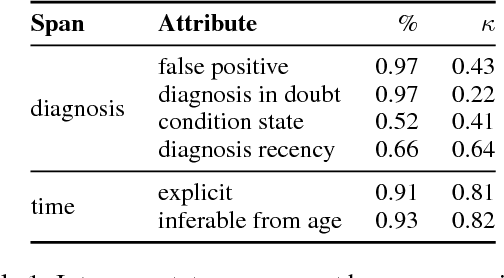



Self-reported diagnosis statements have been widely employed in studying language related to mental health in social media. However, existing research has largely ignored the temporality of mental health diagnoses. In this work, we introduce RSDD-Time: a new dataset of 598 manually annotated self-reported depression diagnosis posts from Reddit that include temporal information about the diagnosis. Annotations include whether a mental health condition is present and how recently the diagnosis happened. Furthermore, we include exact temporal spans that relate to the date of diagnosis. This information is valuable for various computational methods to examine mental health through social media because one's mental health state is not static. We also test several baseline classification and extraction approaches, which suggest that extracting temporal information from self-reported diagnosis statements is challenging.
Automatic Detection of Cyberbullying in Social Media Text
Jan 17, 2018



While social media offer great communication opportunities, they also increase the vulnerability of young people to threatening situations online. Recent studies report that cyberbullying constitutes a growing problem among youngsters. Successful prevention depends on the adequate detection of potentially harmful messages and the information overload on the Web requires intelligent systems to identify potential risks automatically. The focus of this paper is on automatic cyberbullying detection in social media text by modelling posts written by bullies, victims, and bystanders of online bullying. We describe the collection and fine-grained annotation of a training corpus for English and Dutch and perform a series of binary classification experiments to determine the feasibility of automatic cyberbullying detection. We make use of linear support vector machines exploiting a rich feature set and investigate which information sources contribute the most for this particular task. Experiments on a holdout test set reveal promising results for the detection of cyberbullying-related posts. After optimisation of the hyperparameters, the classifier yields an F1-score of 64% and 61% for English and Dutch respectively, and considerably outperforms baseline systems based on keywords and word unigrams.