 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Factual Sycophancy in Language Models: How Size and Instruction Tuning Shape Robustness
Jun 04, 2026Factual sycophancy occurs when a language model abandons a correct, verifiable answer under social pressure. Because a flip occurs only when pressure toward a false answer exceeds the model's neutral preference for the truth, flip rates conflate two mechanisms: the strength of that baseline preference (truth margin), and how far pressure shifts it (manipulation sensitivity). We decompose factual sycophancy into these channels and use them to separate the effects of size and instruction tuning across 56 open-weight models spanning 0.3B-32B parameters and 13 manipulation types. We find that vulnerability is governed mainly by size, but instruction tuning changes how size acts: small instruction-tuned models can become less robust, whereas large instruction-tuned models usually become more robust. Instruction tuning primarily increases truth margin, but its behavioral effect depends on manipulation type. Scaling also changes the two channels differently: base models gain margin but become mildly more manipulation-sensitive, whereas instruction-tuned models gain margin faster and become less sensitive. Factual sycophancy is therefore not a single scalar property. Evaluations should report channel-specific, manipulation-specific, and size-conditioned robustness rather than flip rates alone.
An Agentic AI Framework for Training General Practitioner Student Skills
Dec 20, 2025



Advancements in large language models offer strong potential for enhancing virtual simulated patients (VSPs) in medical education by providing scalable alternatives to resource-intensive traditional methods. However, current VSPs often struggle with medical accuracy, consistent roleplaying, scenario generation for VSP use, and educationally structured feedback. We introduce an agentic framework for training general practitioner student skills that unifies (i) configurable, evidence-based vignette generation, (ii) controlled persona-driven patient dialogue with optional retrieval grounding, and (iii) standards-based assessment and feedback for both communication and clinical reasoning. We instantiate the framework in an interactive spoken consultation setting and evaluate it with medical students ($\mathbf{N{=}14}$). Participants reported realistic and vignette-faithful dialogue, appropriate difficulty calibration, a stable personality signal, and highly useful example-rich feedback, alongside excellent overall usability. These results support agentic separation of scenario control, interaction control, and standards-based assessment as a practical pattern for building dependable and pedagogically valuable VSP training tools.
WinoWhat: A Parallel Corpus of Paraphrased WinoGrande Sentences with Common Sense Categorization
Mar 31, 2025In this study, we take a closer look at how Winograd schema challenges can be used to evaluate common sense reasoning in LLMs. Specifically, we evaluate generative models of different sizes on the popular WinoGrande benchmark. We release WinoWhat, a new corpus, in which each instance of the WinoGrande validation set is paraphrased. Additionally, we evaluate the performance on the challenge across five common sense knowledge categories, giving more fine-grained insights on what types of knowledge are more challenging for LLMs. Surprisingly, all models perform significantly worse on WinoWhat, implying that LLM reasoning capabilities are overestimated on WinoGrande. To verify whether this is an effect of benchmark memorization, we match benchmark instances to LLM trainingdata and create two test-suites. We observe that memorization has a minimal effect on model performance on WinoGrande.
BEIR-NL: Zero-shot Information Retrieval Benchmark for the Dutch Language
Dec 11, 2024Zero-shot evaluation of information retrieval (IR) models is often performed using BEIR; a large and heterogeneous benchmark composed of multiple datasets, covering different retrieval tasks across various domains. Although BEIR has become a standard benchmark for the zero-shot setup, its exclusively English content reduces its utility for underrepresented languages in IR, including Dutch. To address this limitation and encourage the development of Dutch IR models, we introduce BEIR-NL by automatically translating the publicly accessible BEIR datasets into Dutch. Using BEIR-NL, we evaluated a wide range of multilingual dense ranking and reranking models, as well as the lexical BM25 method. Our experiments show that BM25 remains a competitive baseline, and is only outperformed by the larger dense models trained for retrieval. When combined with reranking models, BM25 achieves performance on par with the best dense ranking models. In addition, we explored the impact of translation on the data by back-translating a selection of datasets to English, and observed a performance drop for both dense and lexical methods, indicating the limitations of translation for creating benchmarks. BEIR-NL is publicly available on the Hugging Face hub.
Bilingual BSARD: Extending Statutory Article Retrieval to Dutch
Dec 10, 2024Statutory article retrieval plays a crucial role in making legal information more accessible to both laypeople and legal professionals. Multilingual countries like Belgium present unique challenges for retrieval models due to the need for handling legal issues in multiple languages. Building on the Belgian Statutory Article Retrieval Dataset (BSARD) in French, we introduce the bilingual version of this dataset, bBSARD. The dataset contains parallel Belgian statutory articles in both French and Dutch, along with legal questions from BSARD and their Dutch translation. Using bBSARD, we conduct extensive benchmarking of retrieval models available for Dutch and French. Our benchmarking setup includes lexical models, zero-shot dense models, and fine-tuned small foundation models. Our experiments show that BM25 remains a competitive baseline compared to many zero-shot dense models in both languages. We also observe that while proprietary models outperform open alternatives in the zero-shot setting, they can be matched or surpassed by fine-tuning small language-specific models. Our dataset and evaluation code are publicly available.
Bag of Lies: Robustness in Continuous Pre-training BERT
Jun 14, 2024This study aims to acquire more insights into the continuous pre-training phase of BERT regarding entity knowledge, using the COVID-19 pandemic as a case study. Since the pandemic emerged after the last update of BERT's pre-training data, the model has little to no entity knowledge about COVID-19. Using continuous pre-training, we control what entity knowledge is available to the model. We compare the baseline BERT model with the further pre-trained variants on the fact-checking benchmark Check-COVID. To test the robustness of continuous pre-training, we experiment with several adversarial methods to manipulate the input data, such as training on misinformation and shuffling the word order until the input becomes nonsensical. Surprisingly, our findings reveal that these methods do not degrade, and sometimes even improve, the model's downstream performance. This suggests that continuous pre-training of BERT is robust against misinformation. Furthermore, we are releasing a new dataset, consisting of original texts from academic publications in the LitCovid repository and their AI-generated false counterparts.
PersonalityChat: Conversation Distillation for Personalized Dialog Modeling with Facts and Traits
Jan 14, 2024



The new wave of Large Language Models (LLM) has offered an efficient tool to curate sizeable conversational datasets. So far studies have mainly focused on task-oriented or generic open-domain dialogs, and have not fully explored the ability of LLMs in following complicated prompts. In this work, we focus on personalization, and employ LLMs to curate a dataset which is difficult and costly to crowd-source: PersonalityChat is a synthetic conversational dataset based upon the popular PersonaChat dataset, but conditioned on both personas and (Big-5) personality traits. Evaluating models fine-tuned on this dataset, we show that the personality trait labels can be used for trait-based personalization of generative dialogue models. We also perform a head-to-head comparison between PersonalityChat and PersonaChat, and show that training on the distilled dataset results in more fluent and coherent dialog agents in the small-model regime.
Open-Domain Dialog Evaluation using Follow-Ups Likelihood
Sep 12, 2022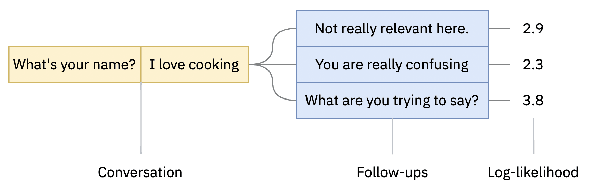
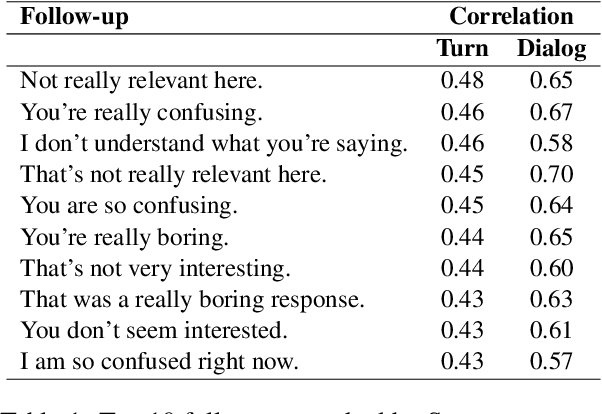
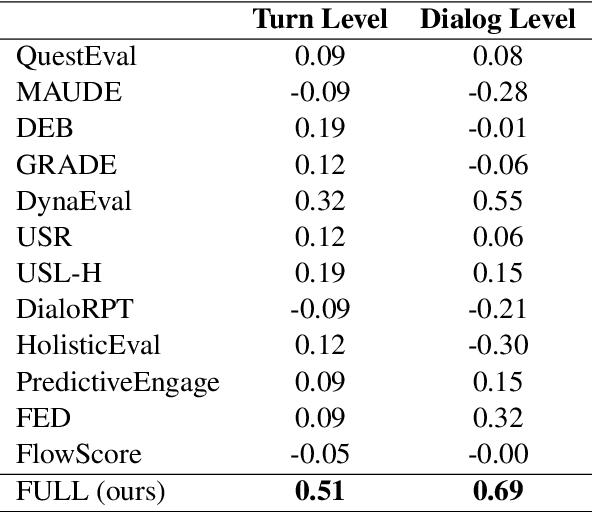
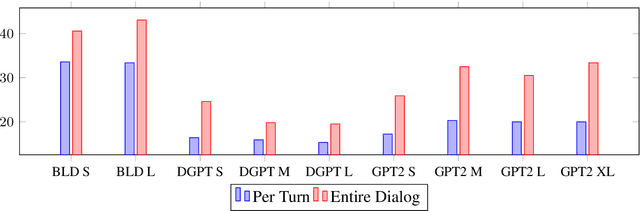
Automatic evaluation of open-domain dialogs remains an unsolved problem. Moreover, existing methods do not correlate strongly with human annotations. This paper presents a new automated evaluation method using follow-ups: we measure the probability that a language model will continue the conversation with a fixed set of follow-ups (e.g., not really relevant here, what are you trying to say). When compared against twelve existing methods, our new evaluation achieves the highest correlation with human evaluations.
CoNTACT: A Dutch COVID-19 Adapted BERT for Vaccine Hesitancy and Argumentation Detection
Mar 14, 2022
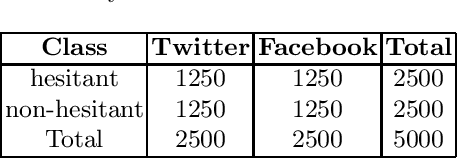
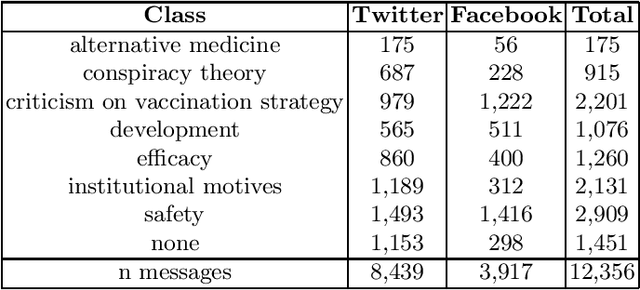
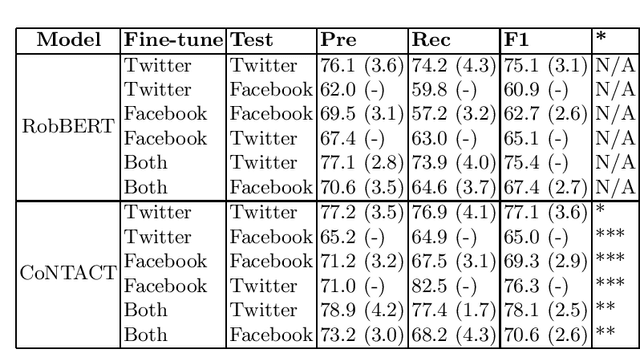
We present CoNTACT: a Dutch language model adapted to the domain of COVID-19 tweets. The model was developed by continuing the pre-training phase of RobBERT (Delobelle, 2020) by using 2.8M Dutch COVID-19 related tweets posted in 2021. In order to test the performance of the model and compare it to RobBERT, the two models were tested on two tasks: (1) binary vaccine hesitancy detection and (2) detection of arguments for vaccine hesitancy. For both tasks, not only Twitter but also Facebook data was used to show cross-genre performance. In our experiments, CoNTACT showed statistically significant gains over RobBERT in all experiments for task 1. For task 2, we observed substantial improvements in virtually all classes in all experiments. An error analysis indicated that the domain adaptation yielded better representations of domain-specific terminology, causing CoNTACT to make more accurate classification decisions.
Cyberbullying Classifiers are Sensitive to Model-Agnostic Perturbations
Jan 17, 2022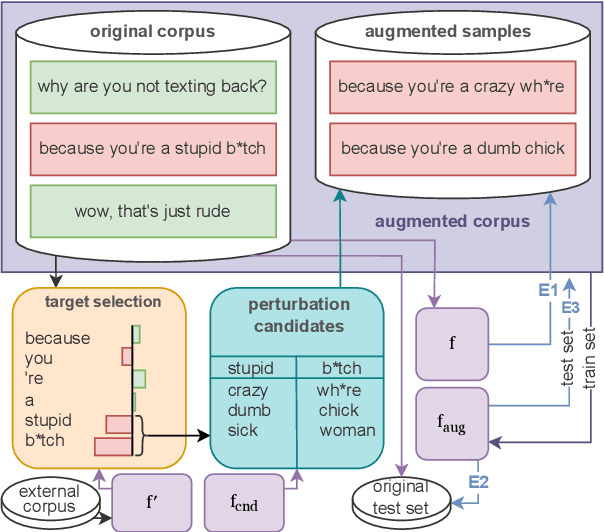
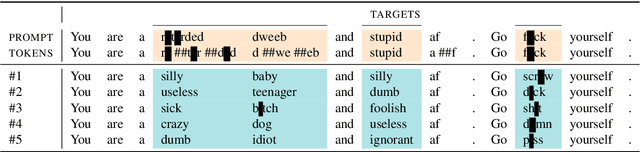
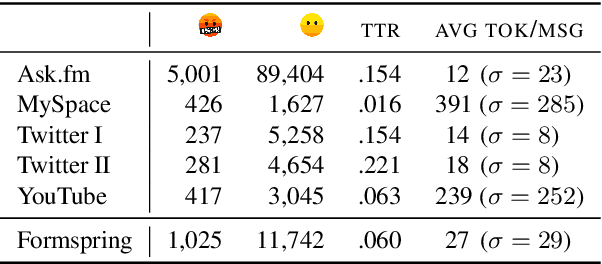
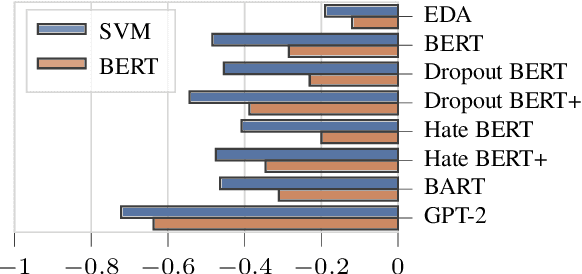
A limited amount of studies investigates the role of model-agnostic adversarial behavior in toxic content classification. As toxicity classifiers predominantly rely on lexical cues, (deliberately) creative and evolving language-use can be detrimental to the utility of current corpora and state-of-the-art models when they are deployed for content moderation. The less training data is available, the more vulnerable models might become. This study is, to our knowledge, the first to investigate the effect of adversarial behavior and augmentation for cyberbullying detection. We demonstrate that model-agnostic lexical substitutions significantly hurt classifier performance. Moreover, when these perturbed samples are used for augmentation, we show models become robust against word-level perturbations at a slight trade-off in overall task performance. Augmentations proposed in prior work on toxicity prove to be less effective. Our results underline the need for such evaluations in online harm areas with small corpora. The perturbed data, models, and code are available for reproduction at https://github.com/cmry/augtox