 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFAQ: a Multilingual FAQ Dataset
Paper and Code
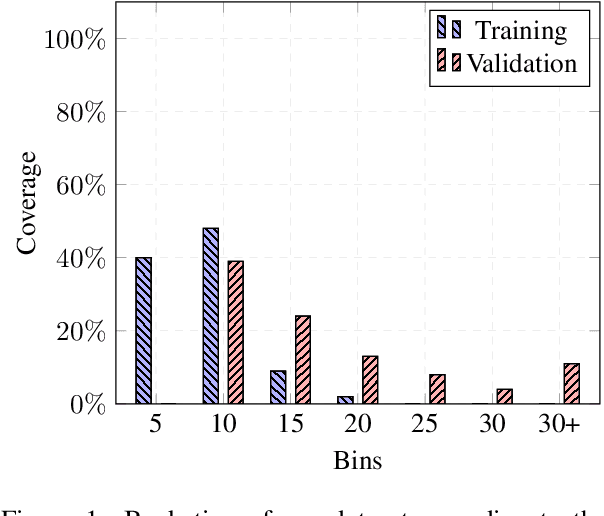

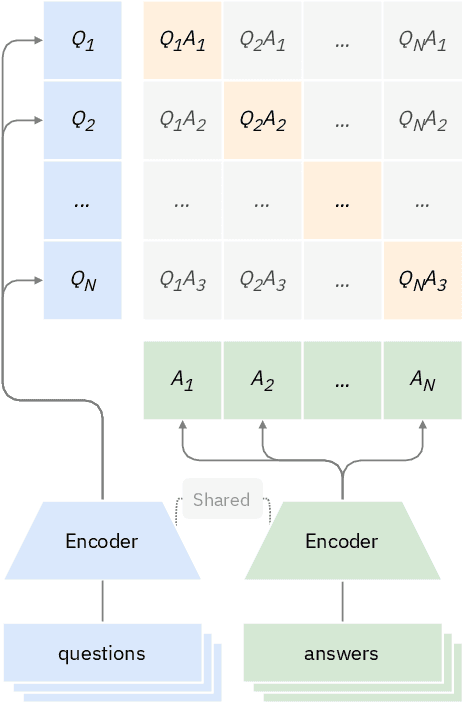

In this paper, we present the first multilingual FAQ dataset publicly available. We collected around 6M FAQ pairs from the web, in 21 different languages. Although this is significantly larger than existing FAQ retrieval datasets, it comes with its own challenges: duplication of content and uneven distribution of topics. We adopt a similar setup as Dense Passage Retrieval (DPR) and test various bi-encoders on this dataset. Our experiments reveal that a multilingual model based on XLM-RoBERTa achieves the best results, except for English. Lower resources languages seem to learn from one another as a multilingual model achieves a higher MRR than language-specific ones. Our qualitative analysis reveals the brittleness of the model on simple word changes. We publicly release our dataset, model and training script.