 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalityChat: Conversation Distillation for Personalized Dialog Modeling with Facts and Traits
Jan 14, 2024



The new wave of Large Language Models (LLM) has offered an efficient tool to curate sizeable conversational datasets. So far studies have mainly focused on task-oriented or generic open-domain dialogs, and have not fully explored the ability of LLMs in following complicated prompts. In this work, we focus on personalization, and employ LLMs to curate a dataset which is difficult and costly to crowd-source: PersonalityChat is a synthetic conversational dataset based upon the popular PersonaChat dataset, but conditioned on both personas and (Big-5) personality traits. Evaluating models fine-tuned on this dataset, we show that the personality trait labels can be used for trait-based personalization of generative dialogue models. We also perform a head-to-head comparison between PersonalityChat and PersonaChat, and show that training on the distilled dataset results in more fluent and coherent dialog agents in the small-model regime.
Open-Domain Dialog Evaluation using Follow-Ups Likelihood
Sep 12, 2022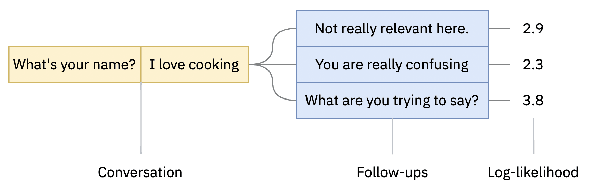
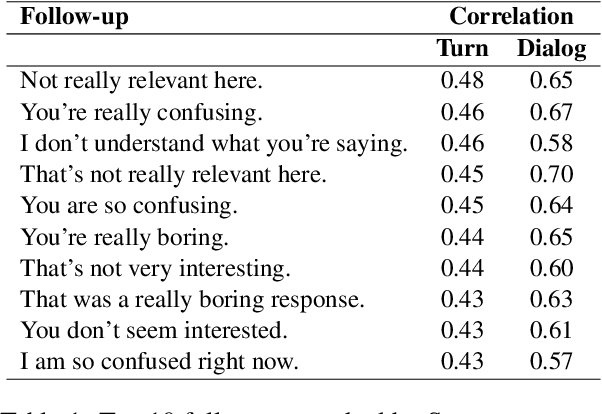
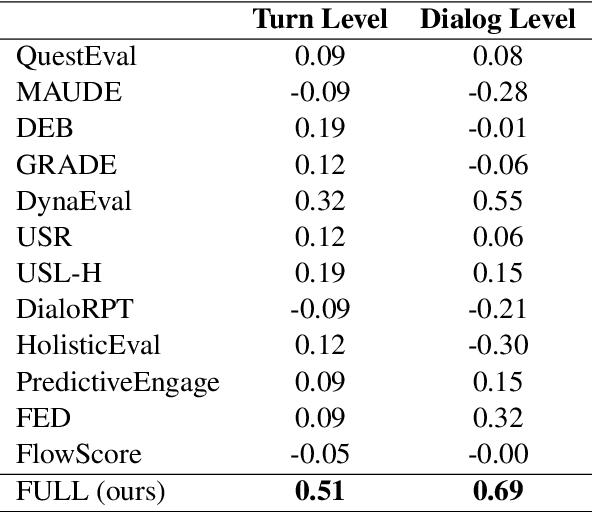
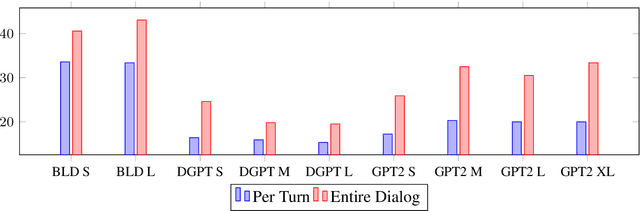
Automatic evaluation of open-domain dialogs remains an unsolved problem. Moreover, existing methods do not correlate strongly with human annotations. This paper presents a new automated evaluation method using follow-ups: we measure the probability that a language model will continue the conversation with a fixed set of follow-ups (e.g., not really relevant here, what are you trying to say). When compared against twelve existing methods, our new evaluation achieves the highest correlation with human evaluations.
MFAQ: a Multilingual FAQ Dataset
Oct 05, 2021

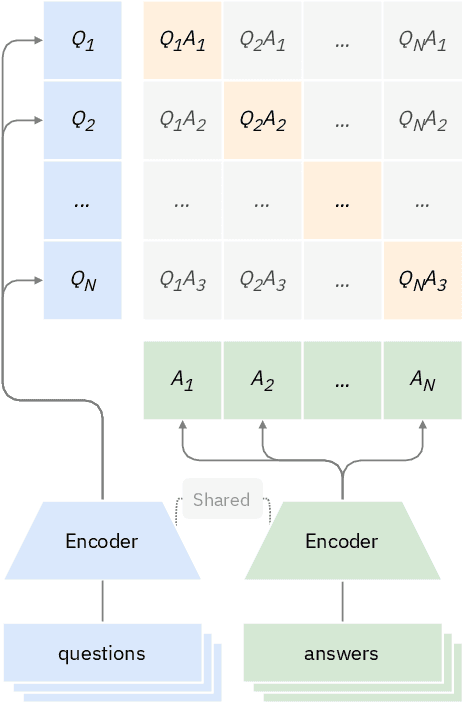

In this paper, we present the first multilingual FAQ dataset publicly available. We collected around 6M FAQ pairs from the web, in 21 different languages. Although this is significantly larger than existing FAQ retrieval datasets, it comes with its own challenges: duplication of content and uneven distribution of topics. We adopt a similar setup as Dense Passage Retrieval (DPR) and test various bi-encoders on this dataset. Our experiments reveal that a multilingual model based on XLM-RoBERTa achieves the best results, except for English. Lower resources languages seem to learn from one another as a multilingual model achieves a higher MRR than language-specific ones. Our qualitative analysis reveals the brittleness of the model on simple word changes. We publicly release our dataset, model and training script.
Teach Me What to Say and I Will Learn What to Pick: Unsupervised Knowledge Selection Through Response Generation with Pretrained Generative Models
Oct 05, 2021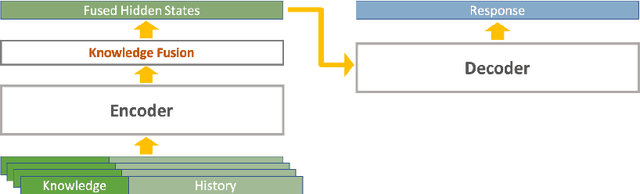

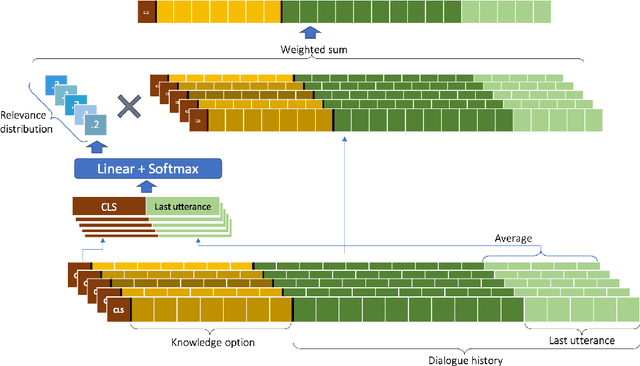

Knowledge Grounded Conversation Models (KGCM) are usually based on a selection/retrieval module and a generation module, trained separately or simultaneously, with or without having access to a gold knowledge option. With the introduction of large pre-trained generative models, the selection and generation part have become more and more entangled, shifting the focus towards enhancing knowledge incorporation (from multiple sources) instead of trying to pick the best knowledge option. These approaches however depend on knowledge labels and/or a separate dense retriever for their best performance. In this work we study the unsupervised selection abilities of pre-trained generative models (e.g. BART) and show that by adding a score-and-aggregate module between encoder and decoder, they are capable of learning to pick the proper knowledge through minimising the language modelling loss (i.e. without having access to knowledge labels). Trained as such, our model - K-Mine - shows competitive selection and generation performance against models that benefit from knowledge labels and/or separate dense retriever.
ConveRT for FAQ Answering
Aug 03, 2021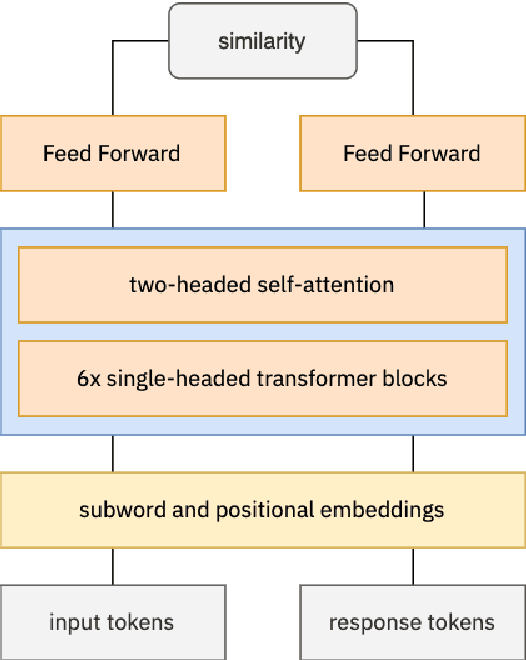

Knowledgeable FAQ chatbots are a valuable resource to any organization. Unlike traditional call centers or FAQ web pages, they provide instant responses and are always available. Our experience running a COVID19 chatbot revealed the lack of resources available for FAQ answering in non-English languages. While powerful and efficient retrieval-based models exist for English, it is rarely the case for other languages which do not have the same amount of training data available. In this work, we propose a novel pretaining procedure to adapt ConveRT, an English SOTA conversational agent, to other languages with less training data available. We apply it for the first time to the task of Dutch FAQ answering related to the COVID19 vaccine. We show it performs better than an open-source alternative in a low-data regime and high-data regime.