 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach Me What to Say and I Will Learn What to Pick: Unsupervised Knowledge Selection Through Response Generation with Pretrained Generative Models
Paper and Code
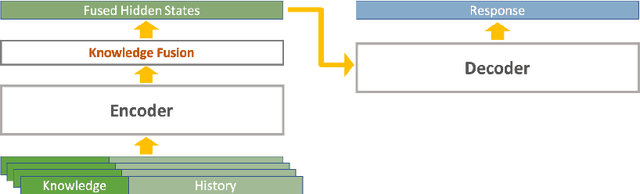

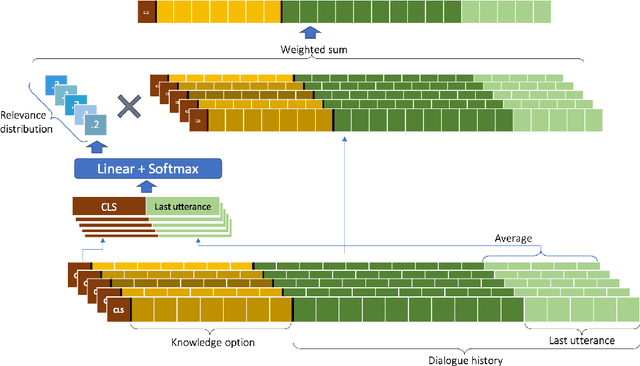

Knowledge Grounded Conversation Models (KGCM) are usually based on a selection/retrieval module and a generation module, trained separately or simultaneously, with or without having access to a gold knowledge option. With the introduction of large pre-trained generative models, the selection and generation part have become more and more entangled, shifting the focus towards enhancing knowledge incorporation (from multiple sources) instead of trying to pick the best knowledge option. These approaches however depend on knowledge labels and/or a separate dense retriever for their best performance. In this work we study the unsupervised selection abilities of pre-trained generative models (e.g. BART) and show that by adding a score-and-aggregate module between encoder and decoder, they are capable of learning to pick the proper knowledge through minimising the language modelling loss (i.e. without having access to knowledge labels). Trained as such, our model - K-Mine - shows competitive selection and generation performance against models that benefit from knowledge labels and/or separate dense retriever.