Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Domain Dialog Evaluation using Follow-Ups Likelihood
Paper and Code
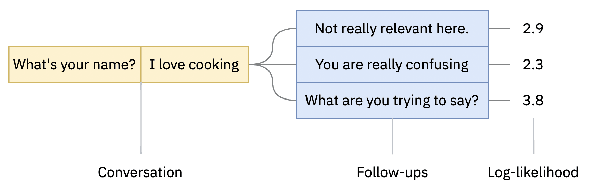
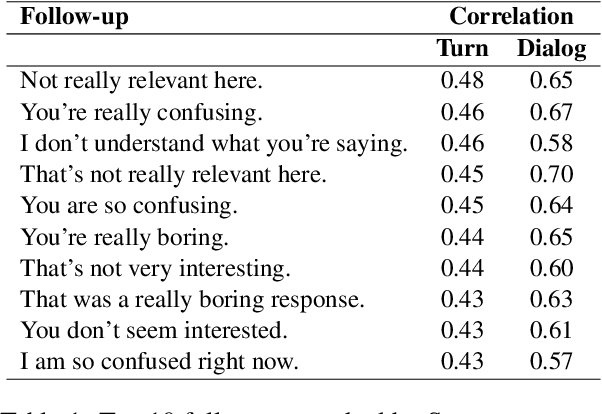
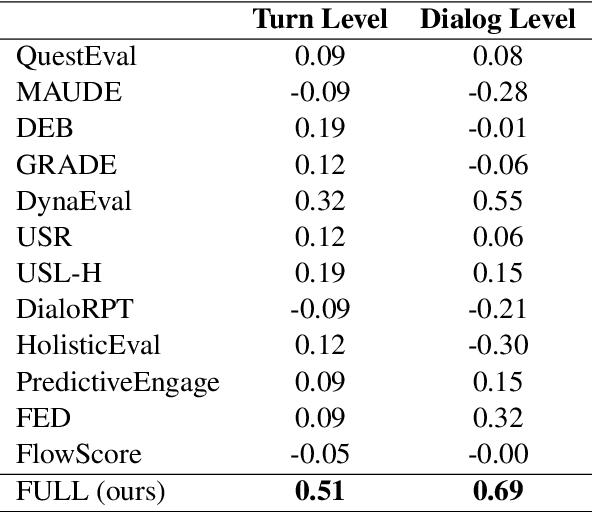
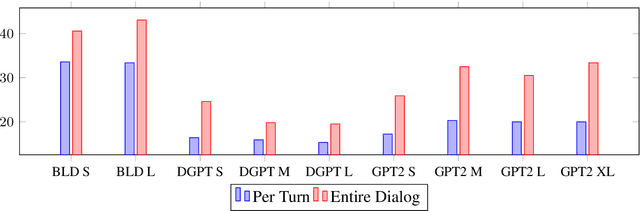
Automatic evaluation of open-domain dialogs remains an unsolved problem. Moreover, existing methods do not correlate strongly with human annotations. This paper presents a new automated evaluation method using follow-ups: we measure the probability that a language model will continue the conversation with a fixed set of follow-ups (e.g., not really relevant here, what are you trying to say). When compared against twelve existing methods, our new evaluation achieves the highest correlation with human evaluations.
* Accepted at COLING 2022
View paper on