 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConveRT for FAQ Answering
Paper and Code
Aug 03, 2021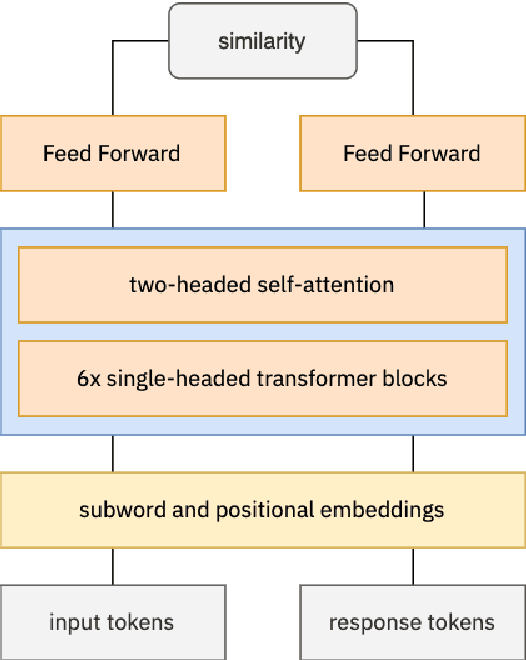

Knowledgeable FAQ chatbots are a valuable resource to any organization. Unlike traditional call centers or FAQ web pages, they provide instant responses and are always available. Our experience running a COVID19 chatbot revealed the lack of resources available for FAQ answering in non-English languages. While powerful and efficient retrieval-based models exist for English, it is rarely the case for other languages which do not have the same amount of training data available. In this work, we propose a novel pretaining procedure to adapt ConveRT, an English SOTA conversational agent, to other languages with less training data available. We apply it for the first time to the task of Dutch FAQ answering related to the COVID19 vaccine. We show it performs better than an open-source alternative in a low-data regime and high-data regime.