 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEIR-NL: Zero-shot Information Retrieval Benchmark for the Dutch Language
Dec 11, 2024Zero-shot evaluation of information retrieval (IR) models is often performed using BEIR; a large and heterogeneous benchmark composed of multiple datasets, covering different retrieval tasks across various domains. Although BEIR has become a standard benchmark for the zero-shot setup, its exclusively English content reduces its utility for underrepresented languages in IR, including Dutch. To address this limitation and encourage the development of Dutch IR models, we introduce BEIR-NL by automatically translating the publicly accessible BEIR datasets into Dutch. Using BEIR-NL, we evaluated a wide range of multilingual dense ranking and reranking models, as well as the lexical BM25 method. Our experiments show that BM25 remains a competitive baseline, and is only outperformed by the larger dense models trained for retrieval. When combined with reranking models, BM25 achieves performance on par with the best dense ranking models. In addition, we explored the impact of translation on the data by back-translating a selection of datasets to English, and observed a performance drop for both dense and lexical methods, indicating the limitations of translation for creating benchmarks. BEIR-NL is publicly available on the Hugging Face hub.
Bilingual BSARD: Extending Statutory Article Retrieval to Dutch
Dec 10, 2024Statutory article retrieval plays a crucial role in making legal information more accessible to both laypeople and legal professionals. Multilingual countries like Belgium present unique challenges for retrieval models due to the need for handling legal issues in multiple languages. Building on the Belgian Statutory Article Retrieval Dataset (BSARD) in French, we introduce the bilingual version of this dataset, bBSARD. The dataset contains parallel Belgian statutory articles in both French and Dutch, along with legal questions from BSARD and their Dutch translation. Using bBSARD, we conduct extensive benchmarking of retrieval models available for Dutch and French. Our benchmarking setup includes lexical models, zero-shot dense models, and fine-tuned small foundation models. Our experiments show that BM25 remains a competitive baseline compared to many zero-shot dense models in both languages. We also observe that while proprietary models outperform open alternatives in the zero-shot setting, they can be matched or surpassed by fine-tuning small language-specific models. Our dataset and evaluation code are publicly available.
Character-level Transformer-based Neural Machine Translation
May 22, 2020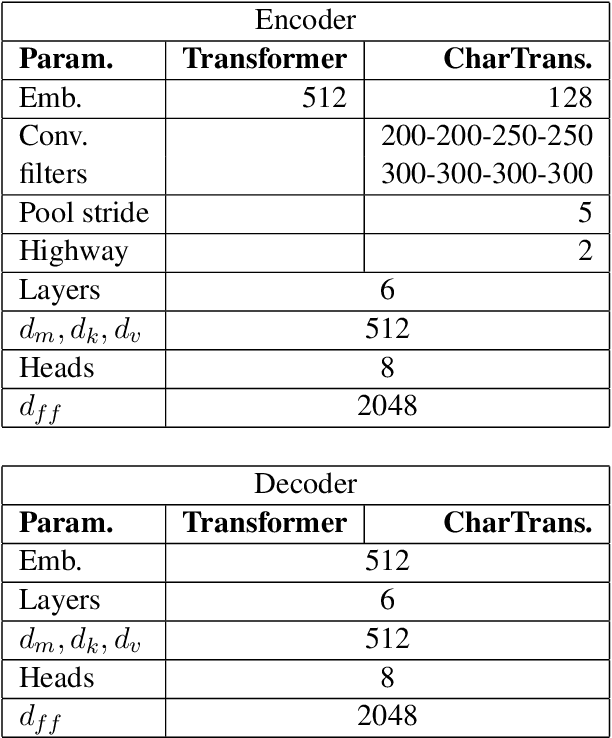
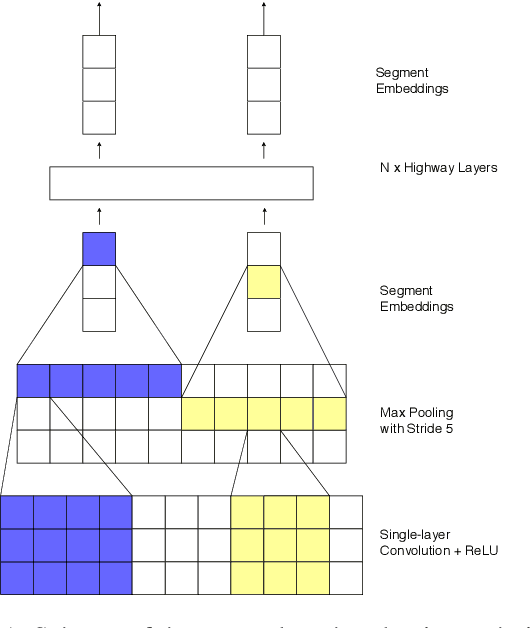
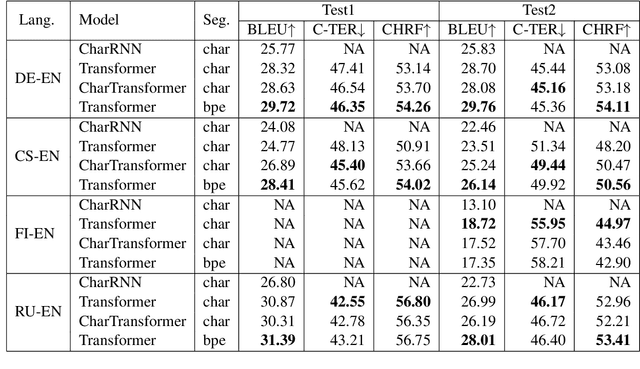
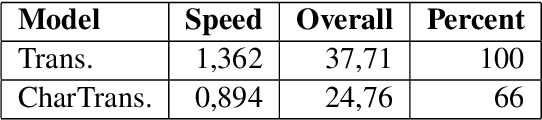
Neural machine translation (NMT) is nowadays commonly applied at the subword level, using byte-pair encoding. A promising alternative approach focuses on character-level translation, which simplifies processing pipelines in NMT considerably. This approach, however, must consider relatively longer sequences, rendering the training process prohibitively expensive. In this paper, we discuss a novel, Transformer-based approach, that we compare, both in speed and in quality to the Transformer at subword and character levels, as well as previously developed character-level models. We evaluate our models on 4 language pairs from WMT'15: DE-EN, CS-EN, FI-EN and RU-EN. The proposed novel architecture can be trained on a single GPU and is 34% percent faster than the character-level Transformer; still, the obtained results are at least on par with it. In addition, our proposed model outperforms the subword-level model in FI-EN and shows close results in CS-EN. To stimulate further research in this area and close the gap with subword-level NMT, we make all our code and models publicly available.