 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom exemplar to copy: the scribal appropriation of a Hadewijch manuscript computationally explored
Oct 30, 2022This study is devoted to two of the oldest known manuscripts in which the oeuvre of the medieval mystical author Hadewijch has been preserved: Brussels, KBR, 2879-2880 (ms. A) and Brussels, KBR, 2877-2878 (ms. B). On the basis of codicological and contextual arguments, it is assumed that the scribe who produced B used A as an exemplar. While the similarities in both layout and content between the two manuscripts are striking, the present article seeks to identify the differences. After all, regardless of the intention to produce a copy that closely follows the exemplar, subtle linguistic variation is apparent. Divergences relate to spelling conventions, but also to the way in which words are abbreviated (and the extent to which abbreviations occur). The present study investigates the spelling profiles of the scribes who produced mss. A and B in a computational way. In the first part of this study, we will present both manuscripts in more detail, after which we will consider prior research carried out on scribal profiling. The current study both builds and expands on Kestemont (2015). Next, we outline the methodology used to analyse and measure the degree of scribal appropriation that took place when ms. B was copied off the exemplar ms. A. After this, we will discuss the results obtained, focusing on the scribal variation that can be found both at the level of individual words and n-grams. To this end, we use machine learning to identify the most distinctive features that separate manuscript A from B. Finally, we look at possible diachronic trends in the appropriation by B's scribe of his exemplar. We argue that scribal takeovers in the exemplar impacts the practice of the copying scribe, while transitions to a different content matter cause little to no effect.
Character-level Transformer-based Neural Machine Translation
May 22, 2020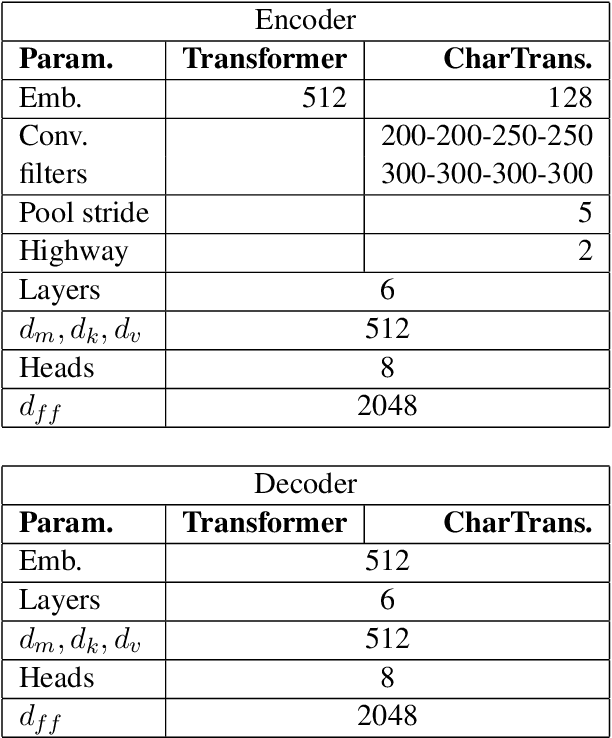
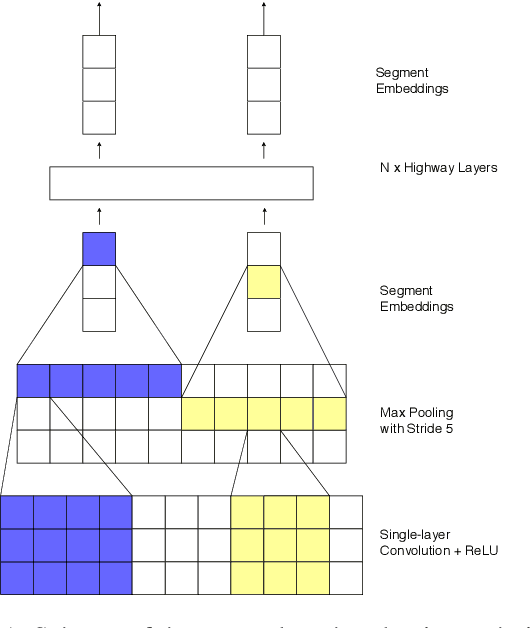
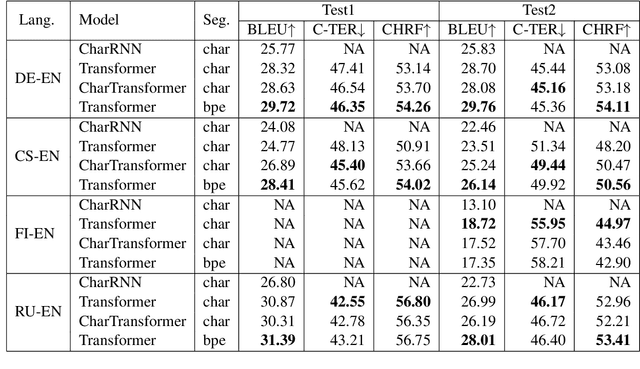
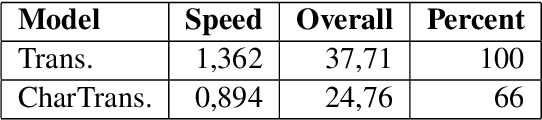
Neural machine translation (NMT) is nowadays commonly applied at the subword level, using byte-pair encoding. A promising alternative approach focuses on character-level translation, which simplifies processing pipelines in NMT considerably. This approach, however, must consider relatively longer sequences, rendering the training process prohibitively expensive. In this paper, we discuss a novel, Transformer-based approach, that we compare, both in speed and in quality to the Transformer at subword and character levels, as well as previously developed character-level models. We evaluate our models on 4 language pairs from WMT'15: DE-EN, CS-EN, FI-EN and RU-EN. The proposed novel architecture can be trained on a single GPU and is 34% percent faster than the character-level Transformer; still, the obtained results are at least on par with it. In addition, our proposed model outperforms the subword-level model in FI-EN and shows close results in CS-EN. To stimulate further research in this area and close the gap with subword-level NMT, we make all our code and models publicly available.
On the Transferability of Winning Tickets in Non-Natural Image Datasets
May 11, 2020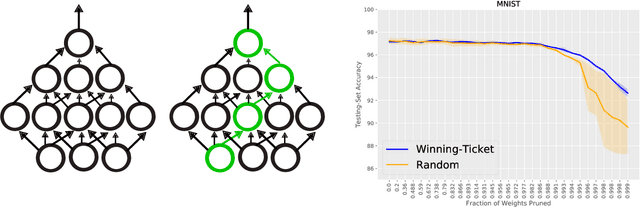
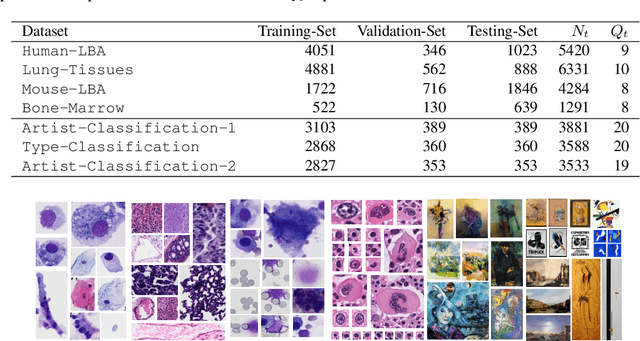
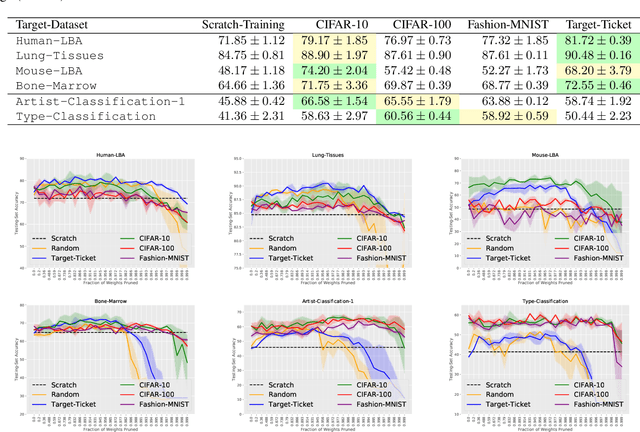

We study the generalization properties of pruned neural networks that are the winners of the lottery ticket hypothesis on datasets of natural images. We analyse their potential under conditions in which training data is scarce and comes from a non-natural domain. Specifically, we investigate whether pruned models that are found on the popular CIFAR-10/100 and Fashion-MNIST datasets, generalize to seven different datasets that come from the fields of digital pathology and digital heritage. Our results show that there are significant benefits in transferring and training sparse architectures over larger parametrized models, since in all of our experiments pruned networks, winners of the lottery ticket hypothesis, significantly outperform their larger unpruned counterparts. These results suggest that winning initializations do contain inductive biases that are generic to some extent, although, as reported by our experiments on the biomedical datasets, their generalization properties can be more limiting than what has been so far observed in the literature.
On the Feasibility of Automated Detection of Allusive Text Reuse
May 08, 2019
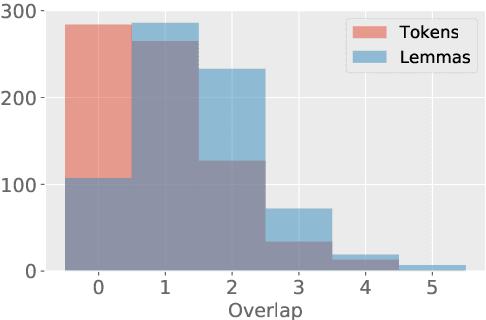
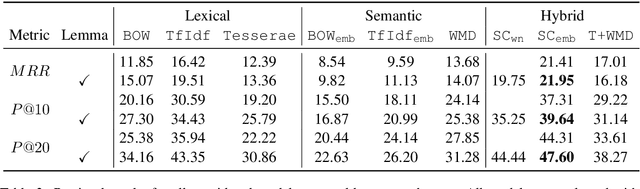
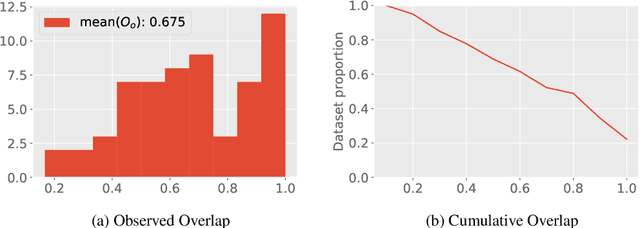
The detection of allusive text reuse is particularly challenging due to the sparse evidence on which allusive references rely---commonly based on none or very few shared words. Arguably, lexical semantics can be resorted to since uncovering semantic relations between words has the potential to increase the support underlying the allusion and alleviate the lexical sparsity. A further obstacle is the lack of evaluation benchmark corpora, largely due to the highly interpretative character of the annotation process. In the present paper, we aim to elucidate the feasibility of automated allusion detection. We approach the matter from an Information Retrieval perspective in which referencing texts act as queries and referenced texts as relevant documents to be retrieved, and estimate the difficulty of benchmark corpus compilation by a novel inter-annotator agreement study on query segmentation. Furthermore, we investigate to what extent the integration of lexical semantic information derived from distributional models and ontologies can aid retrieving cases of allusive reuse. The results show that (i) despite low agreement scores, using manual queries considerably improves retrieval performance with respect to a windowing approach, and that (ii) retrieval performance can be moderately boosted with distributional semantics.
Improving Lemmatization of Non-Standard Languages with Joint Learning
Mar 16, 2019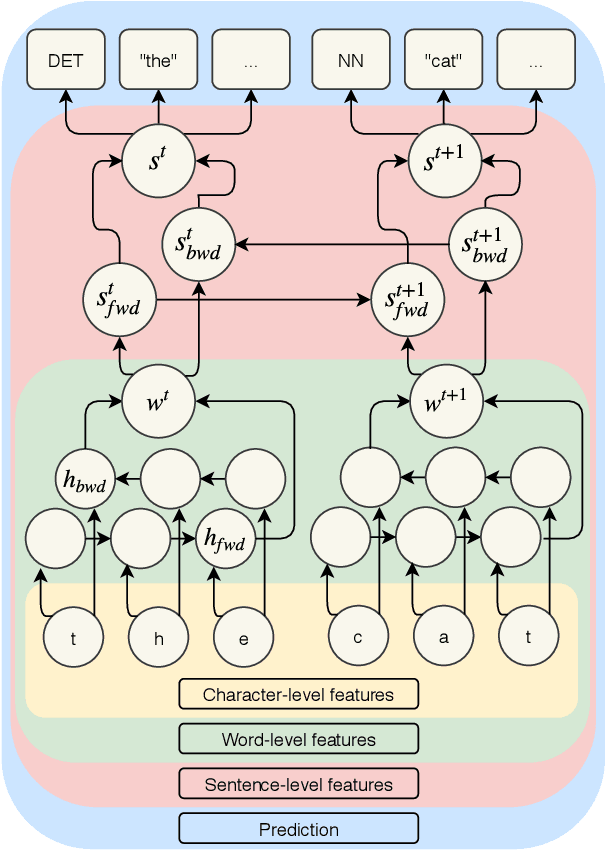
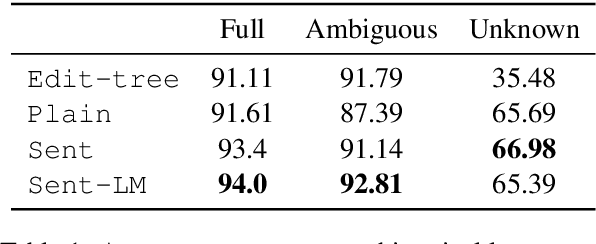
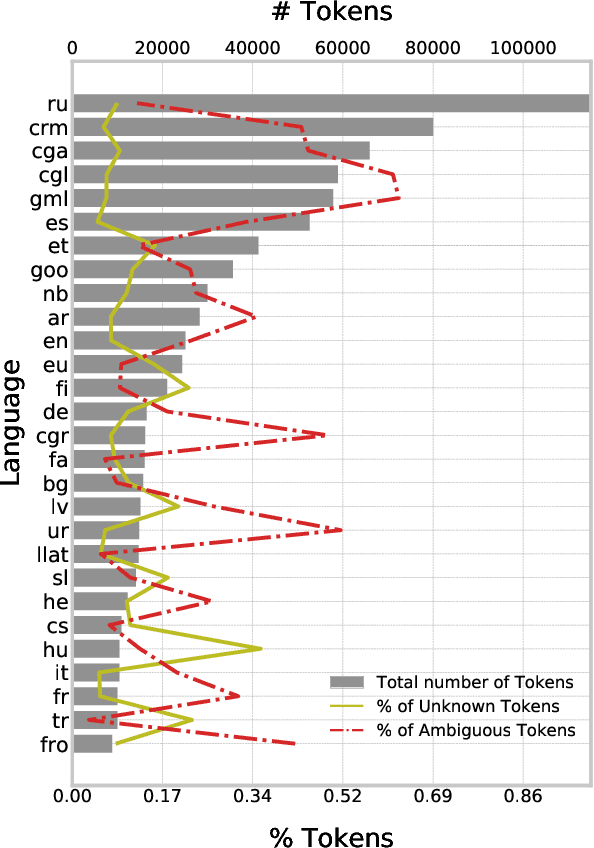

Lemmatization of standard languages is concerned with (i) abstracting over morphological differences and (ii) resolving token-lemma ambiguities of inflected words in order to map them to a dictionary headword. In the present paper we aim to improve lemmatization performance on a set of non-standard historical languages in which the difficulty is increased by an additional aspect (iii): spelling variation due to lacking orthographic standards. We approach lemmatization as a string-transduction task with an encoder-decoder architecture which we enrich with sentence context information using a hierarchical sentence encoder. We show significant improvements over the state-of-the-art when training the sentence encoder jointly for lemmatization and language modeling. Crucially, our architecture does not require POS or morphological annotations, which are not always available for historical corpora. Additionally, we also test the proposed model on a set of typologically diverse standard languages showing results on par or better than a model without enhanced sentence representations and previous state-of-the-art systems. Finally, to encourage future work on processing of non-standard varieties, we release the dataset of non-standard languages underlying the present study, based on openly accessible sources.
Integrated Sequence Tagging for Medieval Latin Using Deep Representation Learning
Aug 03, 2017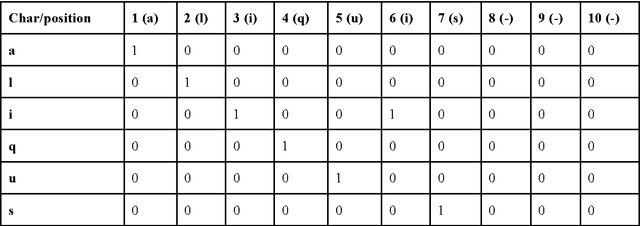

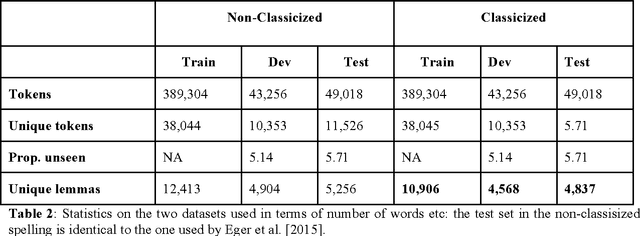

In this paper we consider two sequence tagging tasks for medieval Latin: part-of-speech tagging and lemmatization. These are both basic, yet foundational preprocessing steps in applications such as text re-use detection. Nevertheless, they are generally complicated by the considerable orthographic variation which is typical of medieval Latin. In Digital Classics, these tasks are traditionally solved in a (i) cascaded and (ii) lexicon-dependent fashion. For example, a lexicon is used to generate all the potential lemma-tag pairs for a token, and next, a context-aware PoS-tagger is used to select the most appropriate tag-lemma pair. Apart from the problems with out-of-lexicon items, error percolation is a major downside of such approaches. In this paper we explore the possibility to elegantly solve these tasks using a single, integrated approach. For this, we make use of a layered neural network architecture from the field of deep representation learning.