 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrace-Mediated Peak Bias: Bridging Temporal Credit Assignment and Cognitive Heuristics in Deep Reinforcement Learning
Jun 03, 2026Temporal credit assignment is central to both biological and artificial intelligence, yet its interaction with non-linear function approximation is poorly understood. We identify a systematic failure mode in deep reinforcement learning (RL) termed Trace-Mediated Peak Bias (TMPB). At intermediate eligibility trace depths, agents irrationally prefer trajectories with high-magnitude reward ``peaks'' over alternatives with higher cumulative returns. This provides a mechanistic account of the Peak-End Rule: a human memory bias where experiences are judged by their most intense moments rather than integrated utility. We show that TMPB emerges because traces amplify distal Temporal Difference errors into ``gradient shocks'' that fixed-step-size Stochastic Gradient Descent cannot normalize, leading to global overestimation. Conversely, adaptive optimizers mitigate this pathology via second-moment normalization. Our results suggest that human-like saliency distortions may emerge naturally from the mathematical constraints of credit assignment in distributed systems, and that adaptive optimization is a theoretical necessity for rational value estimation.
Learning in Low-Dimensional Subspaces: Orthogonal Bottlenecks for Reinforcement Learning
May 25, 2026Deep reinforcement learning (RL) agents commonly rely on high-dimensional neural representations, despite growing evidence that task-relevant value and policy structure may be intrinsically low-dimensional. In this work, we present a simple yet effective representation-level prior that inserts a fixed orthonormal projection to constrain encoder features to a low-dimensional subspace, requiring no auxiliary objectives, pretraining, or changes to the underlying RL algorithm. Under a linear realizability assumption, we prove that when the bottleneck dimension exceeds the intrinsic rank of the optimal value function in feature space, the bottleneck preserves expressivity and leaves the induced gradient dynamics unchanged up to an equivalent low-dimensional parameterization. Empirically, we find that across both single and multi-task benchmarks, baseline performance is either matched or improved once the bottleneck dimension exceeds a small task-dependent threshold; in many cases, value representations can be compressed to extremely low dimensions without loss, and the minimal sufficient dimension depends far more on environment complexity than encoder width. In addition, we analyze representation geometry and find that orthogonal bottlenecks stabilize feature norms and are associated with higher effective rank. Together, these results support a representation-space interpretation of the manifold hypothesis in reinforcement learning and position orthogonal bottlenecks as a lightweight, architecture-agnostic mechanism for shaping RL representations.
On The Presence of Double-Descent in Deep Reinforcement Learning
Nov 10, 2025The double descent (DD) paradox, where over-parameterized models see generalization improve past the interpolation point, remains largely unexplored in the non-stationary domain of Deep Reinforcement Learning (DRL). We present preliminary evidence that DD exists in model-free DRL, investigating it systematically across varying model capacity using the Actor-Critic framework. We rely on an information-theoretic metric, Policy Entropy, to measure policy uncertainty throughout training. Preliminary results show a clear epoch-wise DD curve; the policy's entrance into the second descent region correlates with a sustained, significant reduction in Policy Entropy. This entropic decay suggests that over-parameterization acts as an implicit regularizer, guiding the policy towards robust, flatter minima in the loss landscape. These findings establish DD as a factor in DRL and provide an information-based mechanism for designing agents that are more general, transferable, and robust.
On the Generalisation of Koopman Representations for Chaotic System Control
Aug 26, 2025This paper investigates the generalisability of Koopman-based representations for chaotic dynamical systems, focusing on their transferability across prediction and control tasks. Using the Lorenz system as a testbed, we propose a three-stage methodology: learning Koopman embeddings through autoencoding, pre-training a transformer on next-state prediction, and fine-tuning for safety-critical control. Our results show that Koopman embeddings outperform both standard and physics-informed PCA baselines, achieving accurate and data-efficient performance. Notably, fixing the pre-trained transformer weights during fine-tuning leads to no performance degradation, indicating that the learned representations capture reusable dynamical structure rather than task-specific patterns. These findings support the use of Koopman embeddings as a foundation for multi-task learning in physics-informed machine learning. A project page is available at https://kikisprdx.github.io/.
Sparsity-Driven Plasticity in Multi-Task Reinforcement Learning
Aug 09, 2025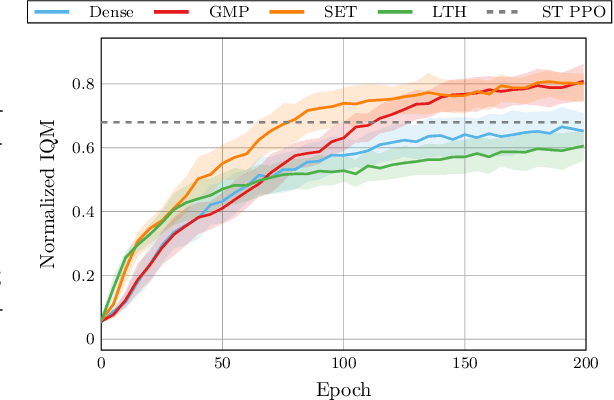
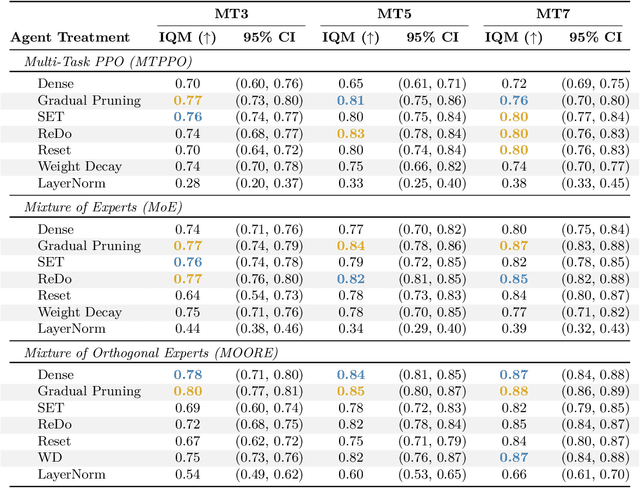

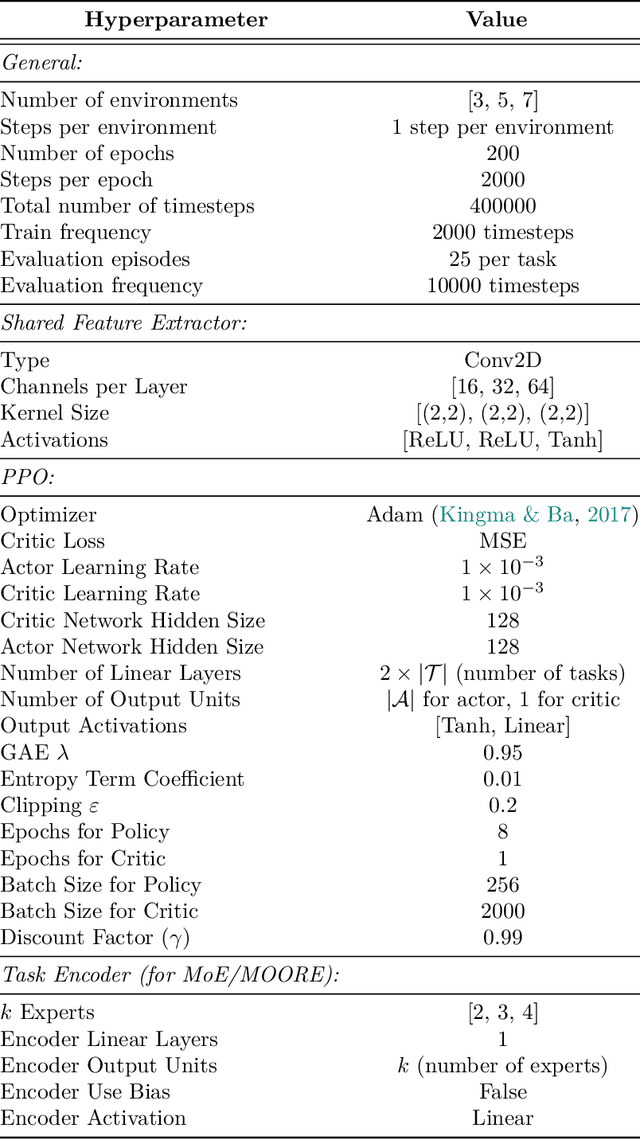
Plasticity loss, a diminishing capacity to adapt as training progresses, is a critical challenge in deep reinforcement learning. We examine this issue in multi-task reinforcement learning (MTRL), where higher representational flexibility is crucial for managing diverse and potentially conflicting task demands. We systematically explore how sparsification methods, particularly Gradual Magnitude Pruning (GMP) and Sparse Evolutionary Training (SET), enhance plasticity and consequently improve performance in MTRL agents. We evaluate these approaches across distinct MTRL architectures (shared backbone, Mixture of Experts, Mixture of Orthogonal Experts) on standardized MTRL benchmarks, comparing against dense baselines, and a comprehensive range of alternative plasticity-inducing or regularization methods. Our results demonstrate that both GMP and SET effectively mitigate key indicators of plasticity degradation, such as neuron dormancy and representational collapse. These plasticity improvements often correlate with enhanced multi-task performance, with sparse agents frequently outperforming dense counterparts and achieving competitive results against explicit plasticity interventions. Our findings offer insights into the interplay between plasticity, network sparsity, and MTRL designs, highlighting dynamic sparsification as a robust but context-sensitive tool for developing more adaptable MTRL systems.
Fisher-Guided Selective Forgetting: Mitigating The Primacy Bias in Deep Reinforcement Learning
Feb 02, 2025Deep Reinforcement Learning (DRL) systems often tend to overfit to early experiences, a phenomenon known as the primacy bias (PB). This bias can severely hinder learning efficiency and final performance, particularly in complex environments. This paper presents a comprehensive investigation of PB through the lens of the Fisher Information Matrix (FIM). We develop a framework characterizing PB through distinct patterns in the FIM trace, identifying critical memorization and reorganization phases during learning. Building on this understanding, we propose Fisher-Guided Selective Forgetting (FGSF), a novel method that leverages the geometric structure of the parameter space to selectively modify network weights, preventing early experiences from dominating the learning process. Empirical results across DeepMind Control Suite (DMC) environments show that FGSF consistently outperforms baselines, particularly in complex tasks. We analyze the different impacts of PB on actor and critic networks, the role of replay ratios in exacerbating the effect, and the effectiveness of even simple noise injection methods. Our findings provide a deeper understanding of PB and practical mitigation strategies, offering a FIM-based geometric perspective for advancing DRL.
Upside-Down Reinforcement Learning for More Interpretable Optimal Control
Nov 18, 2024



Model-Free Reinforcement Learning (RL) algorithms either learn how to map states to expected rewards or search for policies that can maximize a certain performance function. Model-Based algorithms instead, aim to learn an approximation of the underlying model of the RL environment and then use it in combination with planning algorithms. Upside-Down Reinforcement Learning (UDRL) is a novel learning paradigm that aims to learn how to predict actions from states and desired commands. This task is formulated as a Supervised Learning problem and has successfully been tackled by Neural Networks (NNs). In this paper, we investigate whether function approximation algorithms other than NNs can also be used within a UDRL framework. Our experiments, performed over several popular optimal control benchmarks, show that tree-based methods like Random Forests and Extremely Randomized Trees can perform just as well as NNs with the significant benefit of resulting in policies that are inherently more interpretable than NNs, therefore paving the way for more transparent, safe, and robust RL.
Smaller Batches, Bigger Gains? Investigating the Impact of Batch Sizes on Reinforcement Learning Based Real-World Production Scheduling
Jun 04, 2024Production scheduling is an essential task in manufacturing, with Reinforcement Learning (RL) emerging as a key solution. In a previous work, RL was utilized to solve an extended permutation flow shop scheduling problem (PFSSP) for a real-world production line with two stages, linked by a central buffer. The RL agent was trained to sequence equallysized product batches to minimize setup efforts and idle times. However, the substantial impact caused by varying the size of these product batches has not yet been explored. In this follow-up study, we investigate the effects of varying batch sizes, exploring both the quality of solutions and the training dynamics of the RL agent. The results demonstrate that it is possible to methodically identify reasonable boundaries for the batch size. These boundaries are determined on one side by the increasing sample complexity associated with smaller batch sizes, and on the other side by the decreasing flexibility of the agent when dealing with larger batch sizes. This provides the practitioner the ability to make an informed decision regarding the selection of an appropriate batch size. Moreover, we introduce and investigate two new curriculum learning strategies to enable the training with small batch sizes. The findings of this work offer the potential for application in several industrial use cases with comparable scheduling problems.
$ε$-Optimally Solving Zero-Sum POSGs
May 29, 2024



A recent method for solving zero-sum partially observable stochastic games (zs-POSGs) embeds the original game into a new one called the occupancy Markov game. This reformulation allows applying Bellman's principle of optimality to solve zs-POSGs. However, improving a current solution requires solving a linear program with exponentially many potential constraints, which significantly restricts the scalability of this approach. This paper exploits the optimal value function's novel uniform continuity properties to overcome this limitation. We first construct a new operator that is computationally more efficient than the state-of-the-art update rules without compromising optimality. In particular, improving a current solution now involves a linear program with an exponential drop in constraints. We then also show that point-based value iteration algorithms utilizing our findings improve the scalability of existing methods while maintaining guarantees in various domains.
VDSC: Enhancing Exploration Timing with Value Discrepancy and State Counts
Mar 26, 2024



Despite the considerable attention given to the questions of \textit{how much} and \textit{how to} explore in deep reinforcement learning, the investigation into \textit{when} to explore remains relatively less researched. While more sophisticated exploration strategies can excel in specific, often sparse reward environments, existing simpler approaches, such as $\epsilon$-greedy, persist in outperforming them across a broader spectrum of domains. The appeal of these simpler strategies lies in their ease of implementation and generality across a wide range of domains. The downside is that these methods are essentially a blind switching mechanism, which completely disregards the agent's internal state. In this paper, we propose to leverage the agent's internal state to decide \textit{when} to explore, addressing the shortcomings of blind switching mechanisms. We present Value Discrepancy and State Counts through homeostasis (VDSC), a novel approach for efficient exploration timing. Experimental results on the Atari suite demonstrate the superiority of our strategy over traditional methods such as $\epsilon$-greedy and Boltzmann, as well as more sophisticated techniques like Noisy Nets.