 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhrase-Level Adversarial Training for Mitigating Bias in Neural Network-based Automatic Essay Scoring
Sep 07, 2024



Automatic Essay Scoring (AES) is widely used to evaluate candidates for educational purposes. However, due to the lack of representative data, most existing AES systems are not robust, and their scoring predictions are biased towards the most represented data samples. In this study, we propose a model-agnostic phrase-level method to generate an adversarial essay set to address the biases and robustness of AES models. Specifically, we construct an attack test set comprising samples from the original test set and adversarially generated samples using our proposed method. To evaluate the effectiveness of the attack strategy and data augmentation, we conducted a comprehensive analysis utilizing various neural network scoring models. Experimental results show that the proposed approach significantly improves AES model performance in the presence of adversarial examples and scenarios without such attacks.
Mapping Transformer Leveraged Embeddings for Cross-Lingual Document Representation
Jan 12, 2024



Recommendation systems, for documents, have become tools to find relevant content on the Web. However, these systems have limitations when it comes to recommending documents in languages different from the query language, which means they might overlook resources in non-native languages. This research focuses on representing documents across languages by using Transformer Leveraged Document Representations (TLDRs) that are mapped to a cross-lingual domain. Four multilingual pre-trained transformer models (mBERT, mT5 XLM RoBERTa, ErnieM) were evaluated using three mapping methods across 20 language pairs representing combinations of five selected languages of the European Union. Metrics like Mate Retrieval Rate and Reciprocal Rank were used to measure the effectiveness of mapped TLDRs compared to non-mapped ones. The results highlight the power of cross-lingual representations achieved through pre-trained transformers and mapping approaches suggesting a promising direction for expanding beyond language connections, between two specific languages.
Multimodal Feature Extraction for Memes Sentiment Classification
Jul 07, 2022

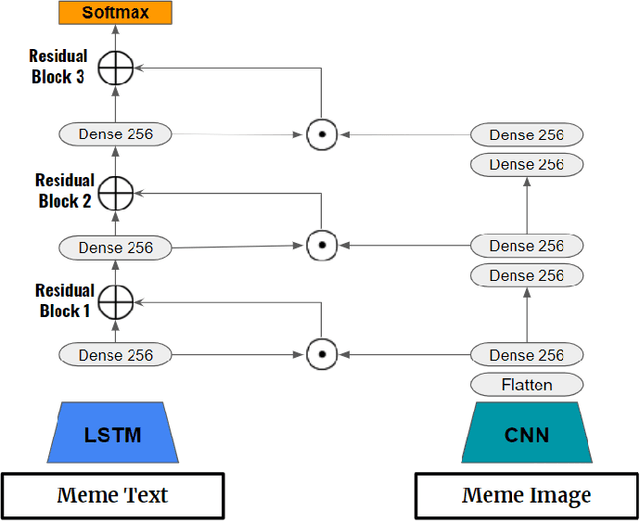
In this study, we propose feature extraction for multimodal meme classification using Deep Learning approaches. A meme is usually a photo or video with text shared by the young generation on social media platforms that expresses a culturally relevant idea. Since they are an efficient way to express emotions and feelings, a good classifier that can classify the sentiment behind the meme is important. To make the learning process more efficient, reduce the likelihood of overfitting, and improve the generalizability of the model, one needs a good approach for joint feature extraction from all modalities. In this work, we proposed to use different multimodal neural network approaches for multimodal feature extraction and use the extracted features to train a classifier to identify the sentiment in a meme.
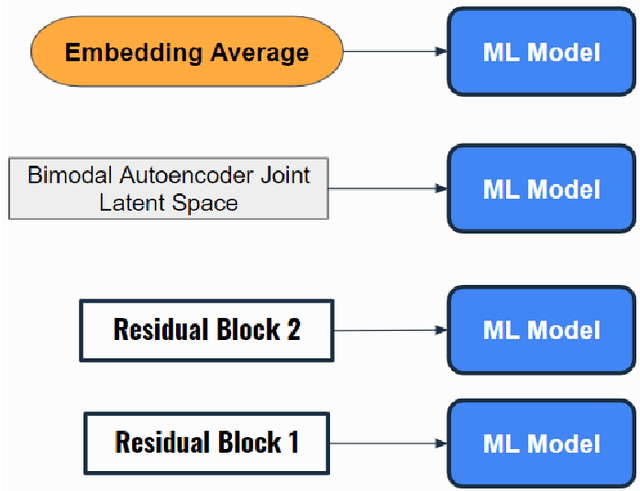
Multimodal E-Commerce Product Classification Using Hierarchical Fusion
Jul 07, 2022


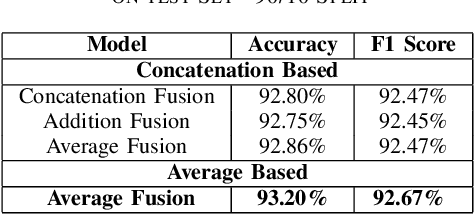
In this work, we present a multi-modal model for commercial product classification, that combines features extracted by multiple neural network models from textual (CamemBERT and FlauBERT) and visual data (SE-ResNeXt-50), using simple fusion techniques. The proposed method significantly outperformed the unimodal models' performance and the reported performance of similar models on our specific task. We did experiments with multiple fusing techniques and found, that the best performing technique to combine the individual embedding of the unimodal network is based on combining concatenation and averaging the feature vectors. Each modality complemented the shortcomings of the other modalities, demonstrating that increasing the number of modalities can be an effective method for improving the performance of multi-label and multimodal classification problems.
Deep Learning Architecture for Automatic Essay Scoring
Jun 16, 2022

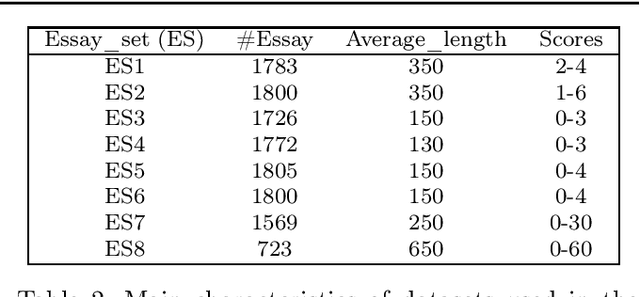
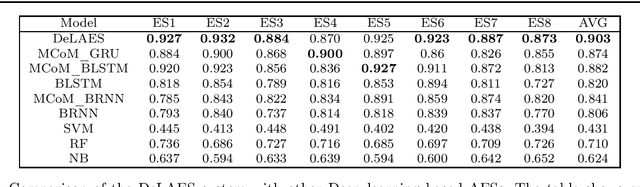
Automatic evaluation of essay (AES) and also called automatic essay scoring has become a severe problem due to the rise of online learning and evaluation platforms such as Coursera, Udemy, Khan academy, and so on. Researchers have recently proposed many techniques for automatic evaluation. However, many of these techniques use hand-crafted features and thus are limited from the feature representation point of view. Deep learning has emerged as a new paradigm in machine learning which can exploit the vast data and identify the features useful for essay evaluation. To this end, we propose a novel architecture based on recurrent networks (RNN) and convolution neural network (CNN). In the proposed architecture, the multichannel convolutional layer learns and captures the contextual features of the word n-gram from the word embedding vectors and the essential semantic concepts to form the feature vector at essay level using max-pooling operation. A variant of RNN called Bi-gated recurrent unit (BGRU) is used to access both previous and subsequent contextual representations. The experiment was carried out on eight data sets available on Kaggle for the task of AES. The experimental results show that our proposed system achieves significantly higher grading accuracy than other deep learning-based AES systems and also other state-of-the-art AES systems.