 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Feature Extraction for Memes Sentiment Classification
Jul 07, 2022

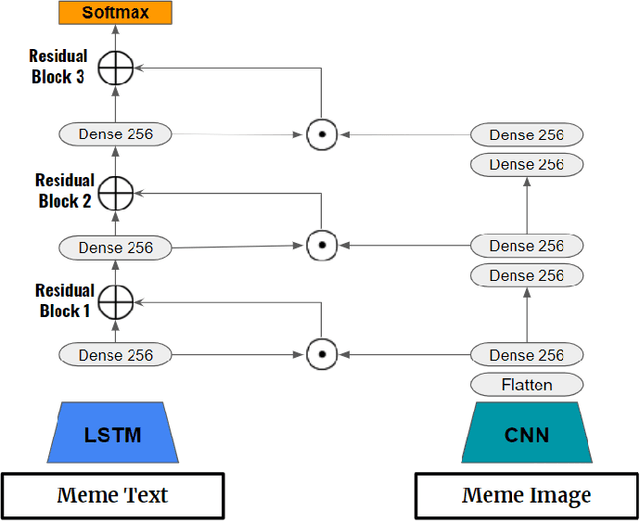
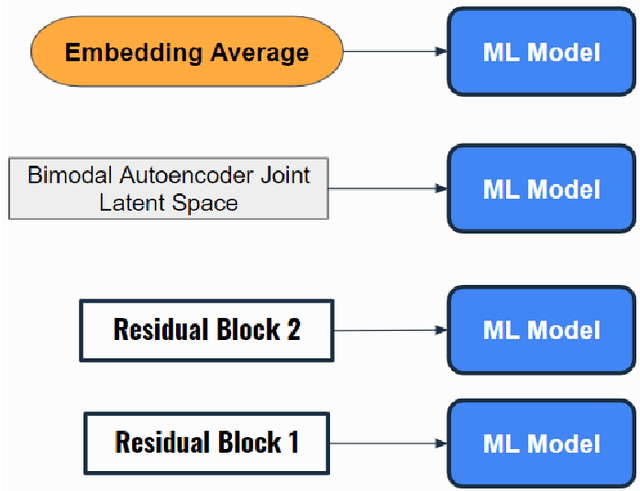
In this study, we propose feature extraction for multimodal meme classification using Deep Learning approaches. A meme is usually a photo or video with text shared by the young generation on social media platforms that expresses a culturally relevant idea. Since they are an efficient way to express emotions and feelings, a good classifier that can classify the sentiment behind the meme is important. To make the learning process more efficient, reduce the likelihood of overfitting, and improve the generalizability of the model, one needs a good approach for joint feature extraction from all modalities. In this work, we proposed to use different multimodal neural network approaches for multimodal feature extraction and use the extracted features to train a classifier to identify the sentiment in a meme.
Multimodal E-Commerce Product Classification Using Hierarchical Fusion
Jul 07, 2022


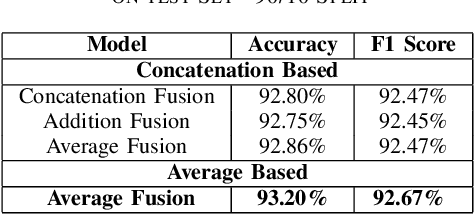
In this work, we present a multi-modal model for commercial product classification, that combines features extracted by multiple neural network models from textual (CamemBERT and FlauBERT) and visual data (SE-ResNeXt-50), using simple fusion techniques. The proposed method significantly outperformed the unimodal models' performance and the reported performance of similar models on our specific task. We did experiments with multiple fusing techniques and found, that the best performing technique to combine the individual embedding of the unimodal network is based on combining concatenation and averaging the feature vectors. Each modality complemented the shortcomings of the other modalities, demonstrating that increasing the number of modalities can be an effective method for improving the performance of multi-label and multimodal classification problems.
Deep Learning Architecture for Automatic Essay Scoring
Jun 16, 2022

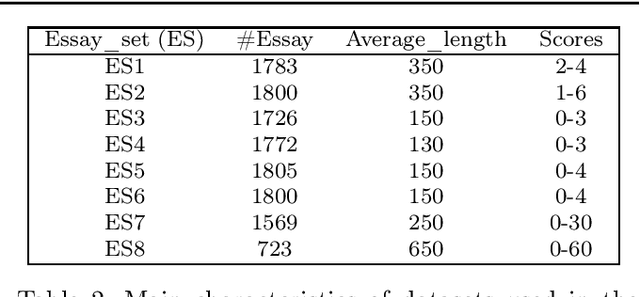
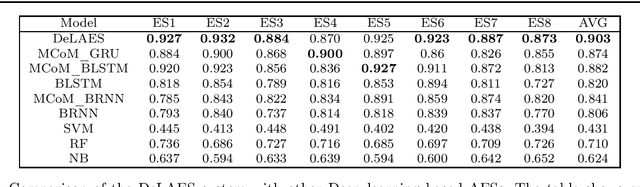
Automatic evaluation of essay (AES) and also called automatic essay scoring has become a severe problem due to the rise of online learning and evaluation platforms such as Coursera, Udemy, Khan academy, and so on. Researchers have recently proposed many techniques for automatic evaluation. However, many of these techniques use hand-crafted features and thus are limited from the feature representation point of view. Deep learning has emerged as a new paradigm in machine learning which can exploit the vast data and identify the features useful for essay evaluation. To this end, we propose a novel architecture based on recurrent networks (RNN) and convolution neural network (CNN). In the proposed architecture, the multichannel convolutional layer learns and captures the contextual features of the word n-gram from the word embedding vectors and the essential semantic concepts to form the feature vector at essay level using max-pooling operation. A variant of RNN called Bi-gated recurrent unit (BGRU) is used to access both previous and subsequent contextual representations. The experiment was carried out on eight data sets available on Kaggle for the task of AES. The experimental results show that our proposed system achieves significantly higher grading accuracy than other deep learning-based AES systems and also other state-of-the-art AES systems.
Online Similarity Learning with Feedback for Invoice Line Item Matching
Feb 14, 2020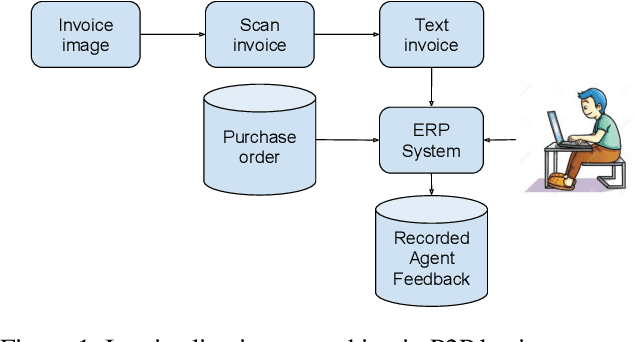

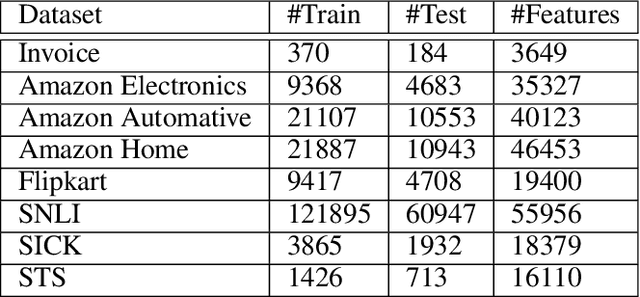
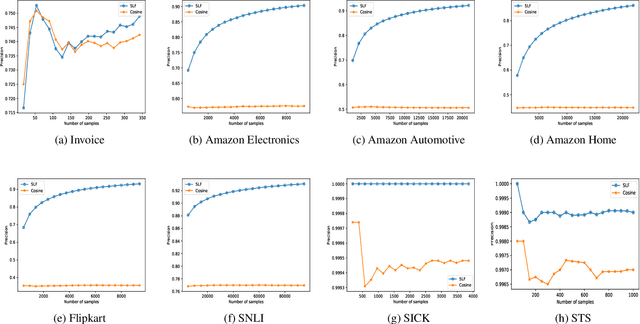
The procure to pay process (P2P) in large enterprises is a back-end business process which deals with the procurement of products and services for enterprise operations. Procurement is done by issuing purchase orders to impaneled vendors and invoices submitted by vendors are paid after they go through a rigorous validation process. Agents orchestrating P2P process often encounter the problem of matching a product or service descriptions in the invoice to those in purchase order and verify if the ordered items are what have been supplied or serviced. For example, the description in the invoice and purchase order could be TRES 739mL CD KER Smooth and TRES 0.739L CD KER Smth which look different at word level but refer to the same item. In a typical P2P process, agents are asked to manually select the products which are similar before invoices are posted for payment. This step in the business process is manual, repetitive, cumbersome, and costly. Since descriptions are not well-formed sentences, we cannot apply existing semantic and syntactic text similarity approaches directly. In this paper, we present two approaches to solve the above problem using various types of available agent's recorded feedback data. If the agent's feedback is in the form of a relative ranking between descriptions, we use similarity ranking algorithm. If the agent's feedback is absolute such as match or no-match, we use classification similarity algorithm. We also present the threats to the validity of our approach and present a possible remedy making use of product taxonomy and catalog. We showcase the comparative effectiveness and efficiency of the proposed approaches over many benchmarks and real-world data sets.