 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Testing and Adapting REST APIs as LLM Tools
Apr 22, 2025Large Language Models (LLMs) are enabling autonomous agents to perform complex workflows using external tools or functions, often provided via REST APIs in enterprise systems. However, directly utilizing these APIs as tools poses challenges due to their complex input schemas, elaborate responses, and often ambiguous documentation. Current benchmarks for tool testing do not adequately address these complexities, leading to a critical gap in evaluating API readiness for agent-driven automation. In this work, we present a novel testing framework aimed at evaluating and enhancing the readiness of REST APIs to function as tools for LLM-based agents. Our framework transforms apis as tools, generates comprehensive test cases for the APIs, translates tests cases into natural language instructions suitable for agents, enriches tool definitions and evaluates the agent's ability t correctly invoke the API and process its inputs and responses. To provide actionable insights, we analyze the outcomes of 750 test cases, presenting a detailed taxonomy of errors, including input misinterpretation, output handling inconsistencies, and schema mismatches. Additionally, we classify these test cases to streamline debugging and refinement of tool integrations. This work offers a foundational step toward enabling enterprise APIs as tools, improving their usability in agent-based applications.
AutoMixer for Improved Multivariate Time-Series Forecasting on Business and IT Observability Data
Nov 02, 2023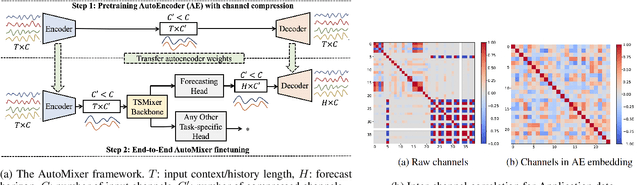
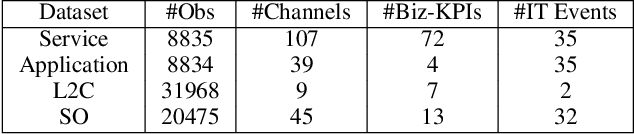
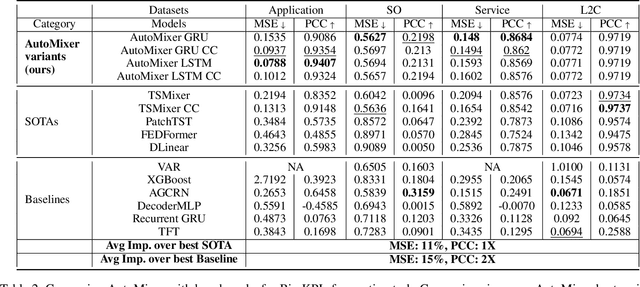
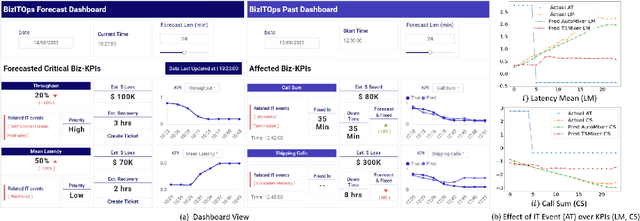
The efficiency of business processes relies on business key performance indicators (Biz-KPIs), that can be negatively impacted by IT failures. Business and IT Observability (BizITObs) data fuses both Biz-KPIs and IT event channels together as multivariate time series data. Forecasting Biz-KPIs in advance can enhance efficiency and revenue through proactive corrective measures. However, BizITObs data generally exhibit both useful and noisy inter-channel interactions between Biz-KPIs and IT events that need to be effectively decoupled. This leads to suboptimal forecasting performance when existing multivariate forecasting models are employed. To address this, we introduce AutoMixer, a time-series Foundation Model (FM) approach, grounded on the novel technique of channel-compressed pretrain and finetune workflows. AutoMixer leverages an AutoEncoder for channel-compressed pretraining and integrates it with the advanced TSMixer model for multivariate time series forecasting. This fusion greatly enhances the potency of TSMixer for accurate forecasts and also generalizes well across several downstream tasks. Through detailed experiments and dashboard analytics, we show AutoMixer's capability to consistently improve the Biz-KPI's forecasting accuracy (by 11-15\%) which directly translates to actionable business insights.
Online Similarity Learning with Feedback for Invoice Line Item Matching
Feb 14, 2020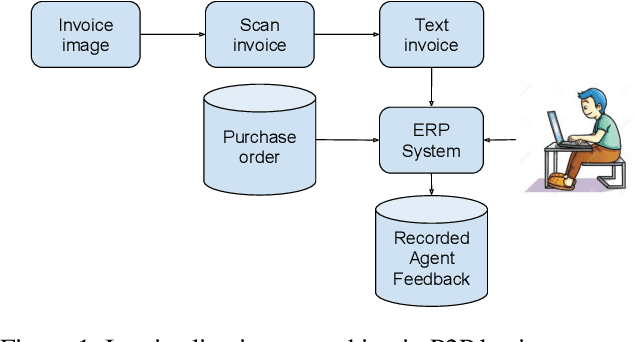

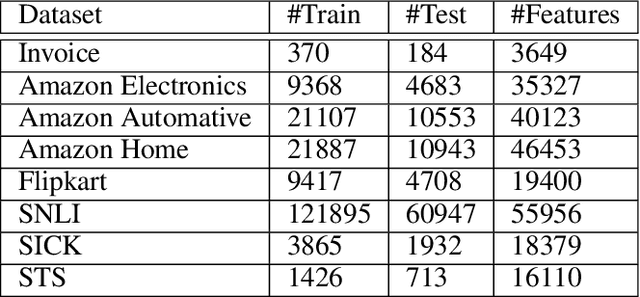
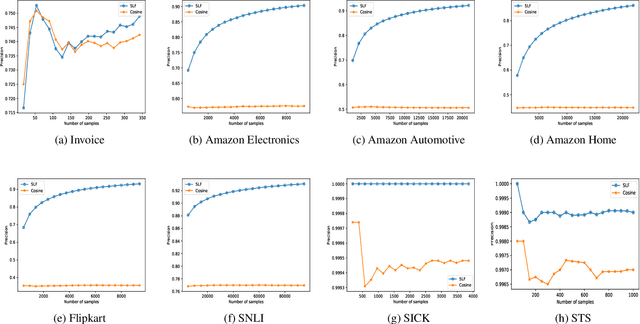
The procure to pay process (P2P) in large enterprises is a back-end business process which deals with the procurement of products and services for enterprise operations. Procurement is done by issuing purchase orders to impaneled vendors and invoices submitted by vendors are paid after they go through a rigorous validation process. Agents orchestrating P2P process often encounter the problem of matching a product or service descriptions in the invoice to those in purchase order and verify if the ordered items are what have been supplied or serviced. For example, the description in the invoice and purchase order could be TRES 739mL CD KER Smooth and TRES 0.739L CD KER Smth which look different at word level but refer to the same item. In a typical P2P process, agents are asked to manually select the products which are similar before invoices are posted for payment. This step in the business process is manual, repetitive, cumbersome, and costly. Since descriptions are not well-formed sentences, we cannot apply existing semantic and syntactic text similarity approaches directly. In this paper, we present two approaches to solve the above problem using various types of available agent's recorded feedback data. If the agent's feedback is in the form of a relative ranking between descriptions, we use similarity ranking algorithm. If the agent's feedback is absolute such as match or no-match, we use classification similarity algorithm. We also present the threats to the validity of our approach and present a possible remedy making use of product taxonomy and catalog. We showcase the comparative effectiveness and efficiency of the proposed approaches over many benchmarks and real-world data sets.
Using Semantic Role Knowledge for Relevance Ranking of Key Phrases inDocuments: An Unsupervised Approach
Aug 09, 2019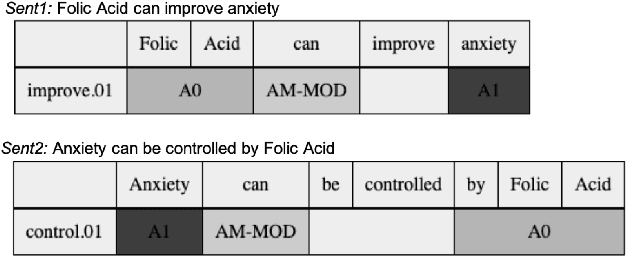

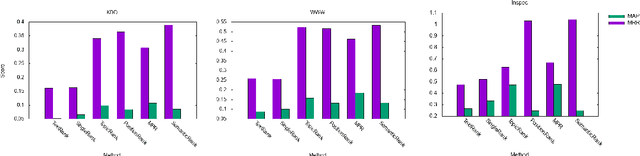
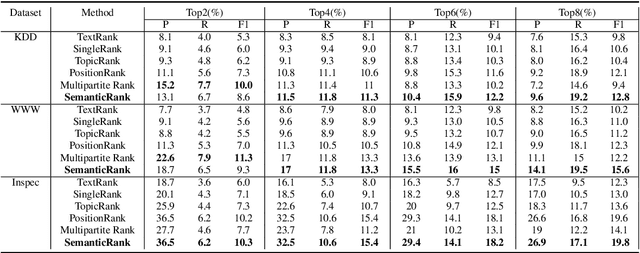
In this paper, we investigate the integration of sentence position and semantic role of words in a PageRank system to build a key phrase ranking method. We present the evaluation results of our approach on three scientific articles. We show that semantic role information, when integrated with a PageRank system, can become a new lexical feature. Our approach had an overall improvement on all the data sets over the state-of-art baseline approaches.
Sanskrit Sandhi Splitting using $\pmb{seq2^2}$
Aug 27, 2018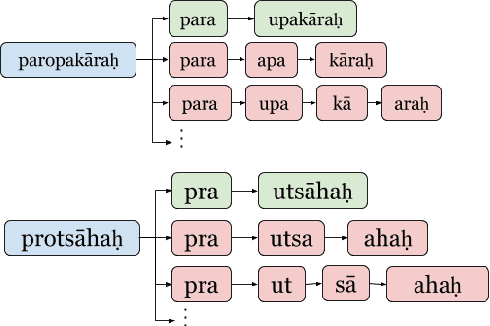
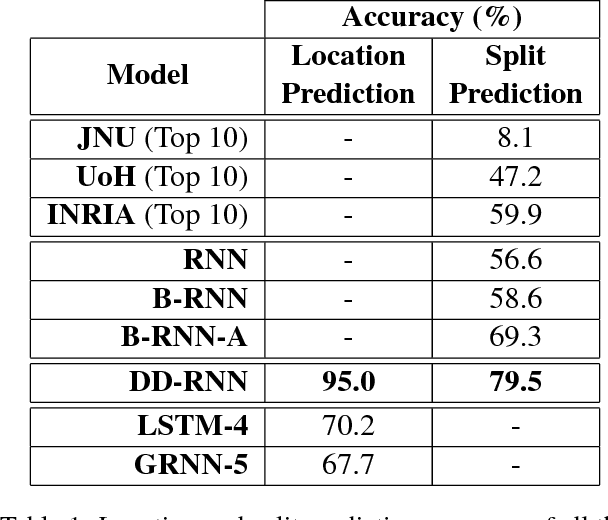
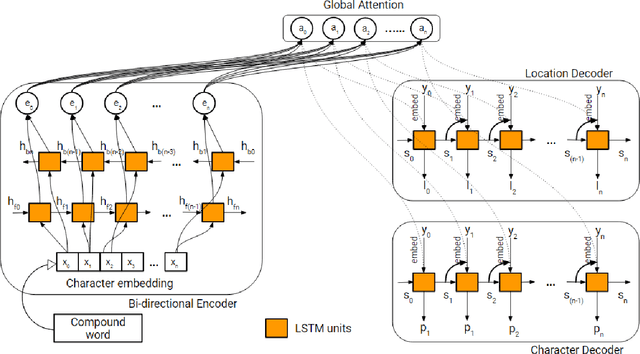
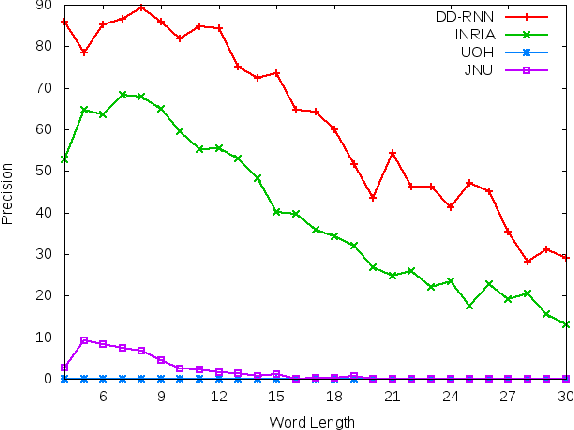
In Sanskrit, small words (morphemes) are combined to form compound words through a process known as Sandhi. Sandhi splitting is the process of splitting a given compound word into its constituent morphemes. Although rules governing word splitting exists in the language, it is highly challenging to identify the location of the splits in a compound word. Though existing Sandhi splitting systems incorporate these pre-defined splitting rules, they have a low accuracy as the same compound word might be broken down in multiple ways to provide syntactically correct splits. In this research, we propose a novel deep learning architecture called Double Decoder RNN (DD-RNN), which (i) predicts the location of the split(s) with 95% accuracy, and (ii) predicts the constituent words (learning the Sandhi splitting rules) with 79.5% accuracy, outperforming the state-of-art by 20%. Additionally, we show the generalization capability of our deep learning model, by showing competitive results in the problem of Chinese word segmentation, as well.
Fault in your stars: An Analysis of Android App Reviews
Aug 11, 2018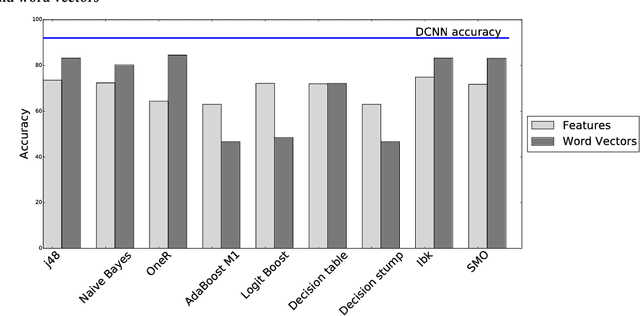
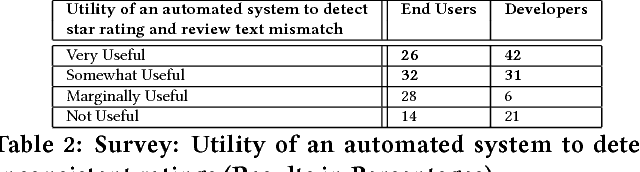
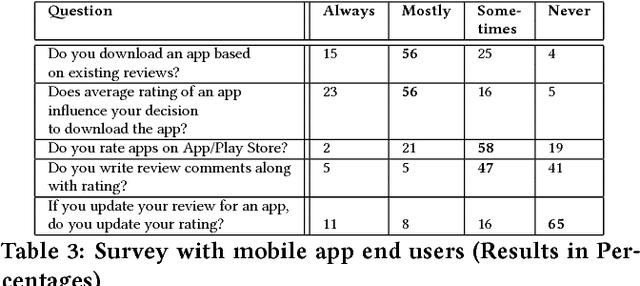
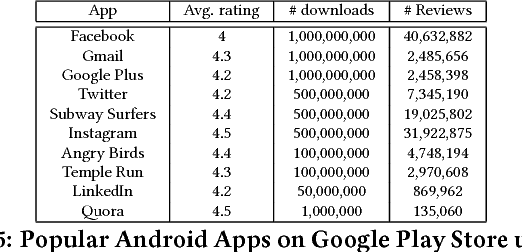
Mobile app distribution platforms such as Google Play Store allow users to share their feedback about downloaded apps in the form of a review comment and a corresponding star rating. Typically, the star rating ranges from one to five stars, with one star denoting a high sense of dissatisfaction with the app and five stars denoting a high sense of satisfaction. Unfortunately, due to a variety of reasons, often the star rating provided by a user is inconsistent with the opinion expressed in the review. For example, consider the following review for the Facebook App on Android; "Awesome App". One would reasonably expect the rating for this review to be five stars, but the actual rating is one star! Such inconsistent ratings can lead to a deflated (or inflated) overall average rating of an app which can affect user downloads, as typically users look at the average star ratings while making a decision on downloading an app. Also, the app developers receive a biased feedback about the application that does not represent ground reality. This is especially significant for small apps with a few thousand downloads as even a small number of mismatched reviews can bring down the average rating drastically. In this paper, we conducted a study on this review-rating mismatch problem. We manually examined 8600 reviews from 10 popular Android apps and found that 20% of the ratings in our dataset were inconsistent with the review. Further, we developed three systems; two of which were based on traditional machine learning and one on deep learning to automatically identify reviews whose rating did not match with the opinion expressed in the review. Our deep learning system performed the best and had an accuracy of 92% in identifying the correct star rating to be associated with a given review.
Hi, how can I help you?: Automating enterprise IT support help desks
Nov 02, 2017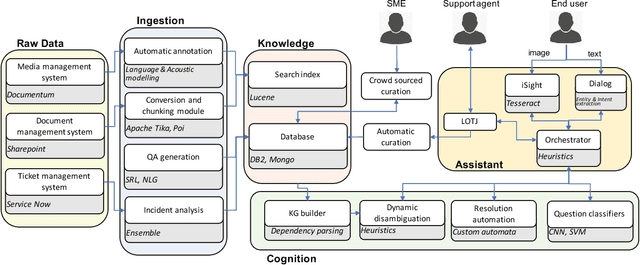
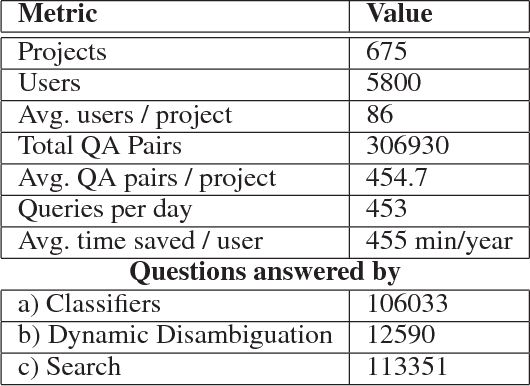
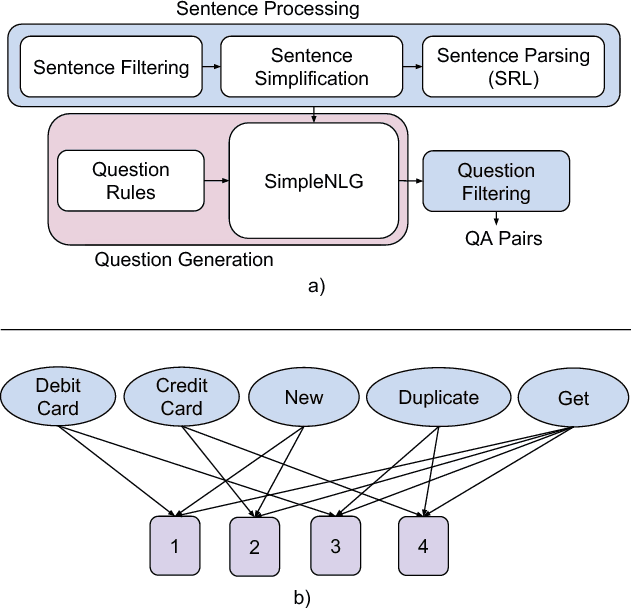
Question answering is one of the primary challenges of natural language understanding. In realizing such a system, providing complex long answers to questions is a challenging task as opposed to factoid answering as the former needs context disambiguation. The different methods explored in the literature can be broadly classified into three categories namely: 1) classification based, 2) knowledge graph based and 3) retrieval based. Individually, none of them address the need of an enterprise wide assistance system for an IT support and maintenance domain. In this domain the variance of answers is large ranging from factoid to structured operating procedures; the knowledge is present across heterogeneous data sources like application specific documentation, ticket management systems and any single technique for a general purpose assistance is unable to scale for such a landscape. To address this, we have built a cognitive platform with capabilities adopted for this domain. Further, we have built a general purpose question answering system leveraging the platform that can be instantiated for multiple products, technologies in the support domain. The system uses a novel hybrid answering model that orchestrates across a deep learning classifier, a knowledge graph based context disambiguation module and a sophisticated bag-of-words search system. This orchestration performs context switching for a provided question and also does a smooth hand-off of the question to a human expert if none of the automated techniques can provide a confident answer. This system has been deployed across 675 internal enterprise IT support and maintenance projects.
mAnI: Movie Amalgamation using Neural Imitation
Aug 16, 2017
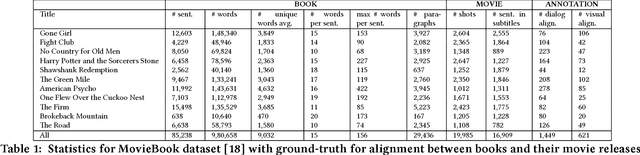

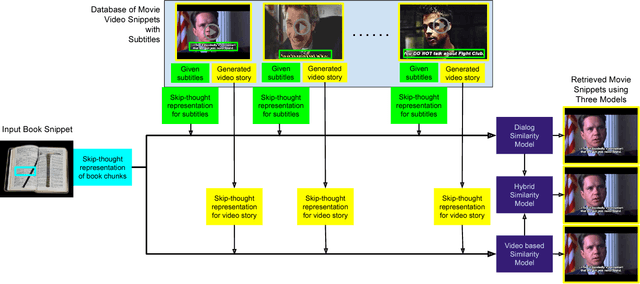
Cross-modal data retrieval has been the basis of various creative tasks performed by Artificial Intelligence (AI). One such highly challenging task for AI is to convert a book into its corresponding movie, which most of the creative film makers do as of today. In this research, we take the first step towards it by visualizing the content of a book using its corresponding movie visuals. Given a set of sentences from a book or even a fan-fiction written in the same universe, we employ deep learning models to visualize the input by stitching together relevant frames from the movie. We studied and compared three different types of setting to match the book with the movie content: (i) Dialog model: using only the dialog from the movie, (ii) Visual model: using only the visual content from the movie, and (iii) Hybrid model: using the dialog and the visual content from the movie. Experiments on the publicly available MovieBook dataset shows the effectiveness of the proposed models.