 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSPulse: Dual Space Tiny Pre-Trained Models for Rapid Time-Series Analysis
May 19, 2025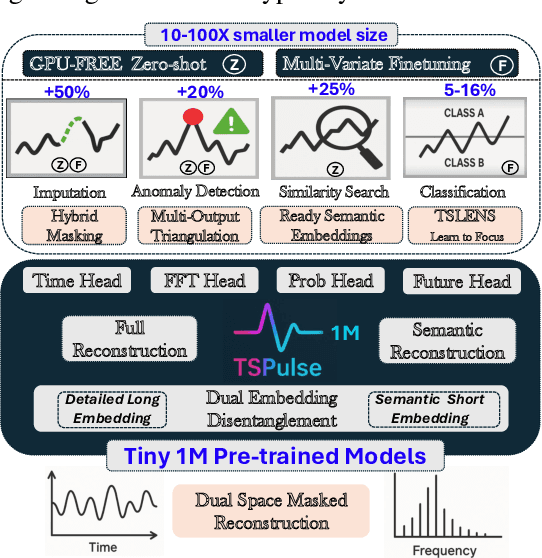

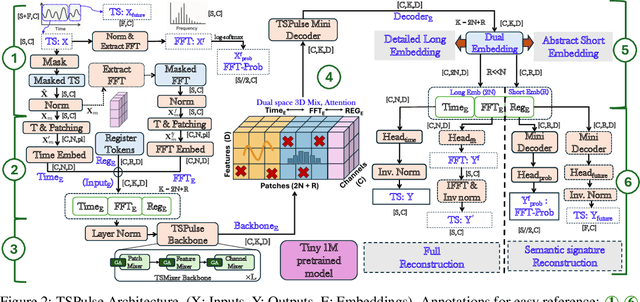

The rise of time-series pre-trained models has advanced temporal representation learning, but current state-of-the-art models are often large-scale, requiring substantial compute. We introduce TSPulse, ultra-compact time-series pre-trained models with only 1M parameters, specialized to perform strongly across classification, anomaly detection, imputation, and retrieval tasks. TSPulse introduces innovations at both the architecture and task levels. At the architecture level, it employs a dual-space masked reconstruction, learning from both time and frequency domains to capture complementary signals. This is further enhanced by a dual-embedding disentanglement, generating both detailed embeddings for fine-grained analysis and high-level semantic embeddings for broader task understanding. Notably, TSPulse's semantic embeddings are robust to shifts in time, magnitude, and noise, which is important for robust retrieval. At the task level, TSPulse incorporates TSLens, a fine-tuning component enabling task-specific feature attention. It also introduces a multi-head triangulation technique that correlates deviations from multiple prediction heads, enhancing anomaly detection by fusing complementary model outputs. Additionally, a hybrid mask pretraining is proposed to improves zero-shot imputation by reducing pre-training bias. These architecture and task innovations collectively contribute to TSPulse's significant performance gains: 5-16% on the UEA classification benchmarks, +20% on the TSB-AD anomaly detection leaderboard, +50% in zero-shot imputation, and +25% in time-series retrieval. Remarkably, these results are achieved with just 1M parameters, making TSPulse 10-100X smaller than existing pre-trained models. Its efficiency enables GPU-free inference and rapid pre-training, setting a new standard for efficient time-series pre-trained models. Models will be open-sourced soon.
Activations Through Extensions: A Framework To Boost Performance Of Neural Networks
Aug 07, 2024Activation functions are non-linearities in neural networks that allow them to learn complex mapping between inputs and outputs. Typical choices for activation functions are ReLU, Tanh, Sigmoid etc., where the choice generally depends on the application domain. In this work, we propose a framework/strategy that unifies several works on activation functions and theoretically explains the performance benefits of these works. We also propose novel techniques that originate from the framework and allow us to obtain ``extensions'' (i.e. special generalizations of a given neural network) of neural networks through operations on activation functions. We theoretically and empirically show that ``extensions'' of neural networks have performance benefits compared to vanilla neural networks with insignificant space and time complexity costs on standard test functions. We also show the benefits of neural network ``extensions'' in the time-series domain on real-world datasets.
Tiny Time Mixers : Fast Pre-trained Models for Enhanced Zero/Few-Shot Forecasting of Multivariate Time Series
Jan 17, 2024Large pre-trained models for zero/few-shot learning excel in language and vision domains but encounter challenges in multivariate time series (TS) due to the diverse nature and scarcity of publicly available pre-training data. Consequently, there has been a recent surge in utilizing pre-trained large language models (LLMs) with token adaptations for TS forecasting. These approaches employ cross-domain transfer learning and surprisingly yield impressive results. However, these models are typically very slow and large (~billion parameters) and do not consider cross-channel correlations. To address this, we present Tiny Time Mixers (TTM), a significantly small model based on the lightweight TSMixer architecture. TTM marks the first success in developing fast and tiny general pre-trained models (<1M parameters), exclusively trained on public TS datasets, with effective transfer learning capabilities for forecasting. To tackle the complexity of pre-training on multiple datasets with varied temporal resolutions, we introduce several novel enhancements such as adaptive patching, dataset augmentation via downsampling, and resolution prefix tuning. Moreover, we employ a multi-level modeling strategy to effectively model channel correlations and infuse exogenous signals during fine-tuning, a crucial capability lacking in existing benchmarks. TTM shows significant accuracy gains (12-38\%) over popular benchmarks in few/zero-shot forecasting. It also drastically reduces the compute needs as compared to LLM-TS methods, with a 14X cut in learnable parameters, 106X less total parameters, and substantial reductions in fine-tuning (65X) and inference time (54X). In fact, TTM's zero-shot often surpasses the few-shot results in many popular benchmarks, highlighting the efficacy of our approach. Code and pre-trained models will be open-sourced.
AutoMixer for Improved Multivariate Time-Series Forecasting on Business and IT Observability Data
Nov 02, 2023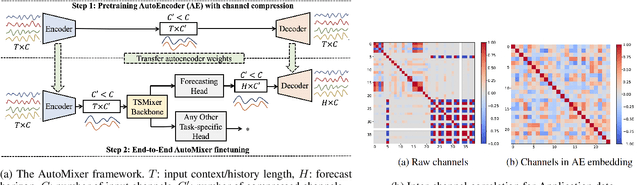
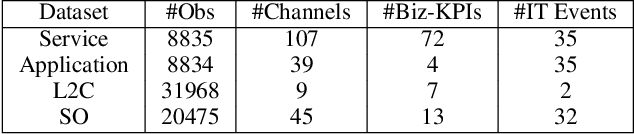
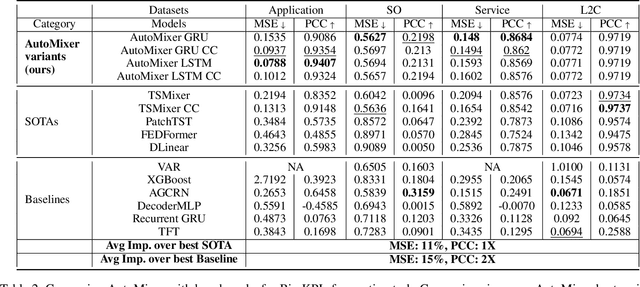
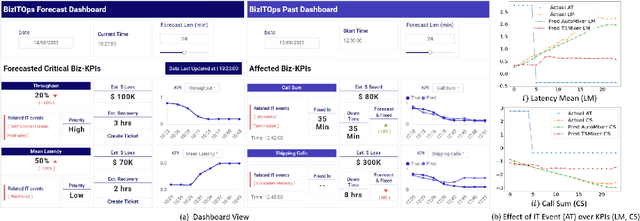
The efficiency of business processes relies on business key performance indicators (Biz-KPIs), that can be negatively impacted by IT failures. Business and IT Observability (BizITObs) data fuses both Biz-KPIs and IT event channels together as multivariate time series data. Forecasting Biz-KPIs in advance can enhance efficiency and revenue through proactive corrective measures. However, BizITObs data generally exhibit both useful and noisy inter-channel interactions between Biz-KPIs and IT events that need to be effectively decoupled. This leads to suboptimal forecasting performance when existing multivariate forecasting models are employed. To address this, we introduce AutoMixer, a time-series Foundation Model (FM) approach, grounded on the novel technique of channel-compressed pretrain and finetune workflows. AutoMixer leverages an AutoEncoder for channel-compressed pretraining and integrates it with the advanced TSMixer model for multivariate time series forecasting. This fusion greatly enhances the potency of TSMixer for accurate forecasts and also generalizes well across several downstream tasks. Through detailed experiments and dashboard analytics, we show AutoMixer's capability to consistently improve the Biz-KPI's forecasting accuracy (by 11-15\%) which directly translates to actionable business insights.
TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting
Jun 28, 2023


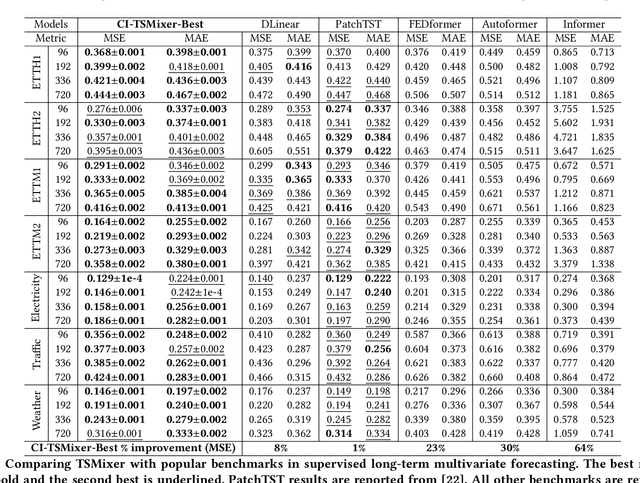
Transformers have gained popularity in time series forecasting for their ability to capture long-sequence interactions. However, their high memory and computing requirements pose a critical bottleneck for long-term forecasting. To address this, we propose TSMixer, a lightweight neural architecture exclusively composed of multi-layer perceptron (MLP) modules. TSMixer is designed for multivariate forecasting and representation learning on patched time series, providing an efficient alternative to Transformers. Our model draws inspiration from the success of MLP-Mixer models in computer vision. We demonstrate the challenges involved in adapting Vision MLP-Mixer for time series and introduce empirically validated components to enhance accuracy. This includes a novel design paradigm of attaching online reconciliation heads to the MLP-Mixer backbone, for explicitly modeling the time-series properties such as hierarchy and channel-correlations. We also propose a Hybrid channel modeling approach to effectively handle noisy channel interactions and generalization across diverse datasets, a common challenge in existing patch channel-mixing methods. Additionally, a simple gated attention mechanism is introduced in the backbone to prioritize important features. By incorporating these lightweight components, we significantly enhance the learning capability of simple MLP structures, outperforming complex Transformer models with minimal computing usage. Moreover, TSMixer's modular design enables compatibility with both supervised and masked self-supervised learning methods, making it a promising building block for time-series Foundation Models. TSMixer outperforms state-of-the-art MLP and Transformer models in forecasting by a considerable margin of 8-60%. It also outperforms the latest strong benchmarks of Patch-Transformer models (by 1-2%) with a significant reduction in memory and runtime (2-3X).
TsSHAP: Robust model agnostic feature-based explainability for time series forecasting
Mar 22, 2023


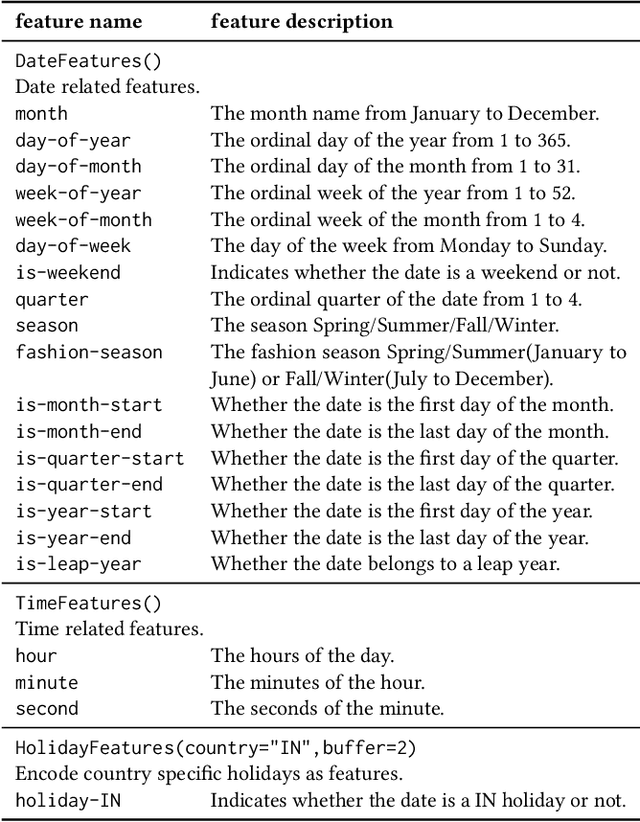
A trustworthy machine learning model should be accurate as well as explainable. Understanding why a model makes a certain decision defines the notion of explainability. While various flavors of explainability have been well-studied in supervised learning paradigms like classification and regression, literature on explainability for time series forecasting is relatively scarce. In this paper, we propose a feature-based explainability algorithm, TsSHAP, that can explain the forecast of any black-box forecasting model. The method is agnostic of the forecasting model and can provide explanations for a forecast in terms of interpretable features defined by the user a prior. The explanations are in terms of the SHAP values obtained by applying the TreeSHAP algorithm on a surrogate model that learns a mapping between the interpretable feature space and the forecast of the black-box model. Moreover, we formalize the notion of local, semi-local, and global explanations in the context of time series forecasting, which can be useful in several scenarios. We validate the efficacy and robustness of TsSHAP through extensive experiments on multiple datasets.
Hierarchy-guided Model Selection for Time Series Forecasting
Nov 28, 2022



Generalizability of time series forecasting models depends on the quality of model selection. Temporal cross validation (TCV) is a standard technique to perform model selection in forecasting tasks. TCV sequentially partitions the training time series into train and validation windows, and performs hyperparameter optmization (HPO) of the forecast model to select the model with the best validation performance. Model selection with TCV often leads to poor test performance when the test data distribution differs from that of the validation data. We propose a novel model selection method, H-Pro that exploits the data hierarchy often associated with a time series dataset. Generally, the aggregated data at the higher levels of the hierarchy show better predictability and more consistency compared to the bottom-level data which is more sparse and (sometimes) intermittent. H-Pro performs the HPO of the lowest-level student model based on the test proxy forecasts obtained from a set of teacher models at higher levels in the hierarchy. The consistency of the teachers' proxy forecasts help select better student models at the lowest-level. We perform extensive empirical studies on multiple datasets to validate the efficacy of the proposed method. H-Pro along with off-the-shelf forecasting models outperform existing state-of-the-art forecasting methods including the winning models of the M5 point-forecasting competition.
Adversarial Attack and Defense Strategies for Deep Speaker Recognition Systems
Aug 18, 2020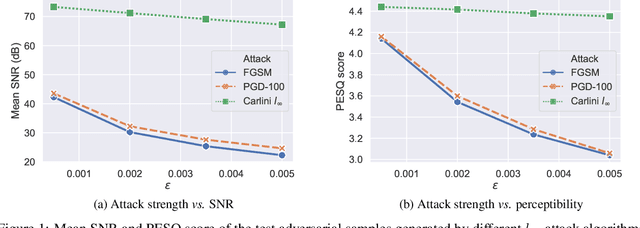
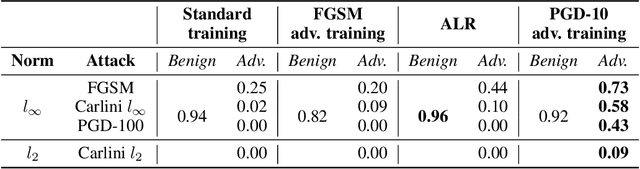
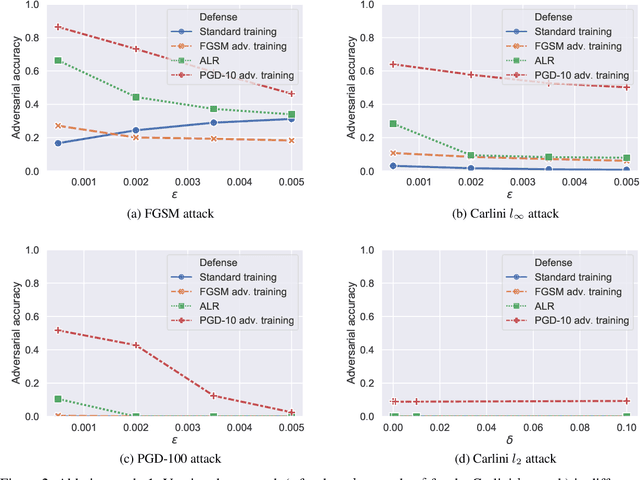

Robust speaker recognition, including in the presence of malicious attacks, is becoming increasingly important and essential, especially due to the proliferation of several smart speakers and personal agents that interact with an individual's voice commands to perform diverse, and even sensitive tasks. Adversarial attack is a recently revived domain which is shown to be effective in breaking deep neural network-based classifiers, specifically, by forcing them to change their posterior distribution by only perturbing the input samples by a very small amount. Although, significant progress in this realm has been made in the computer vision domain, advances within speaker recognition is still limited. The present expository paper considers several state-of-the-art adversarial attacks to a deep speaker recognition system, employing strong defense methods as countermeasures, and reporting on several ablation studies to obtain a comprehensive understanding of the problem. The experiments show that the speaker recognition systems are vulnerable to adversarial attacks, and the strongest attacks can reduce the accuracy of the system from 94% to even 0%. The study also compares the performances of the employed defense methods in detail, and finds adversarial training based on Projected Gradient Descent (PGD) to be the best defense method in our setting. We hope that the experiments presented in this paper provide baselines that can be useful for the research community interested in further studying adversarial robustness of speaker recognition systems.
Characterizing dynamically varying acoustic scenes from egocentric audio recordings in workplace setting
Nov 10, 2019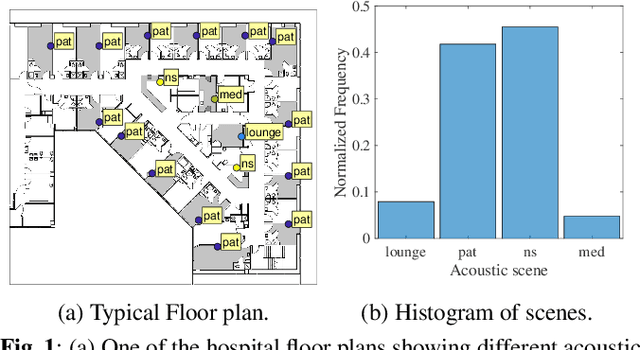



Devices capable of detecting and categorizing acoustic scenes have numerous applications such as providing context-aware user experiences. In this paper, we address the task of characterizing acoustic scenes in a workplace setting from audio recordings collected with wearable microphones. The acoustic scenes, tracked with Bluetooth transceivers, vary dynamically with time from the egocentric perspective of a mobile user. Our dataset contains experience sampled long audio recordings collected from clinical providers in a hospital, who wore the audio badges during multiple work shifts. To handle the long egocentric recordings, we propose a Time Delay Neural Network~(TDNN)-based segment-level modeling. The experiments show that TDNN outperforms other models in the acoustic scene classification task. We investigate the effect of primary speaker's speech in determining acoustic scenes from audio badges, and provide a comparison between performance of different models. Moreover, we explore the relationship between the sequence of acoustic scenes experienced by the users and the nature of their jobs, and find that the scene sequence predicted by our model tend to possess similar relationship. The initial promising results reveal numerous research directions for acoustic scene classification via wearable devices as well as egocentric analysis of dynamic acoustic scenes encountered by the users.
Neural Predictive Coding using Convolutional Neural Networks towards Unsupervised Learning of Speaker Characteristics
Feb 22, 2018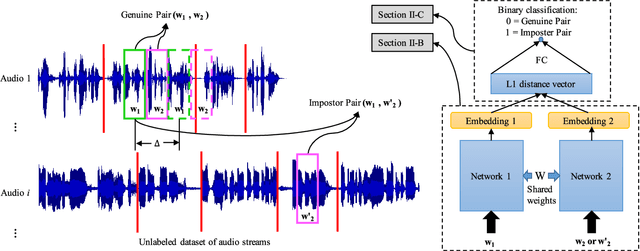
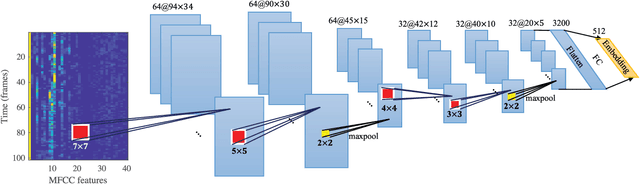
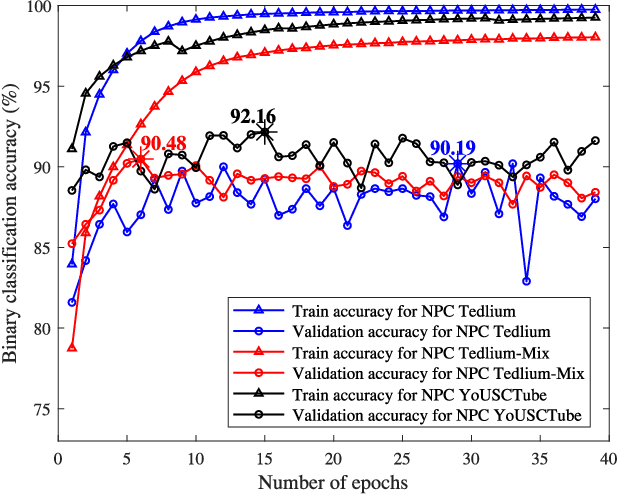
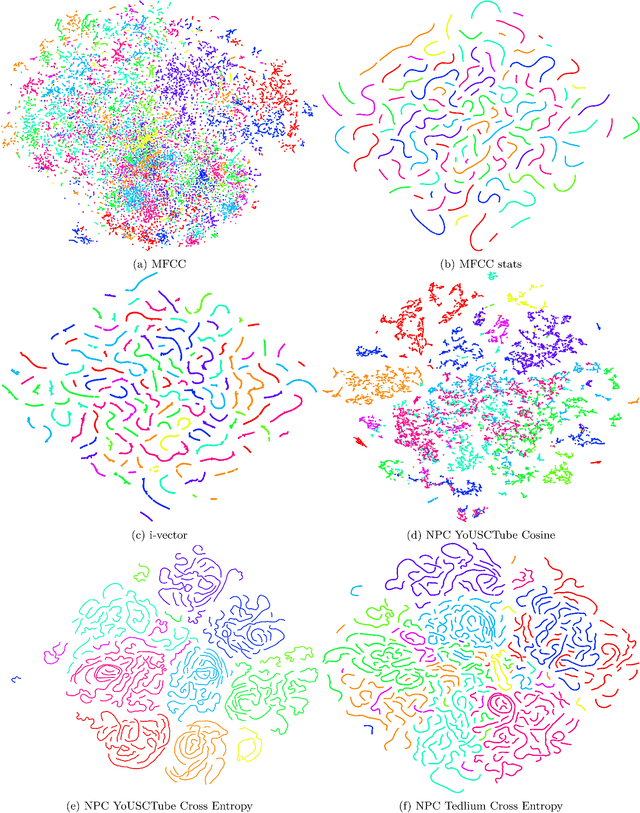
Learning speaker-specific features is vital in many applications like speaker recognition, diarization and speech recognition. This paper provides a novel approach, we term Neural Predictive Coding (NPC), to learn speaker-specific characteristics in a completely unsupervised manner from large amounts of unlabeled training data that even contain multi-speaker audio streams. The NPC framework exploits the proposed short-term active-speaker stationarity hypothesis which assumes two temporally-close short speech segments belong to the same speaker, and thus a common representation that can encode the commonalities of both the segments, should capture the vocal characteristics of that speaker. We train a convolutional deep siamese network to produce "speaker embeddings" by optimizing a loss function that increases between-speaker variability and decreases within-speaker variability. The trained NPC model can produce these embeddings by projecting any test audio stream into a high dimensional manifold where speech frames of the same speaker come closer than they do in the raw feature space. Results in the frame-level speaker classification experiment along with the visualization of the embeddings manifest the distinctive ability of the NPC model to learn short-term speaker-specific features as compared to raw MFCC features and i-vectors. The utterance-level speaker classification experiments show that concatenating simple statistics of the short-term NPC embeddings over the whole utterance with the utterance-level i-vectors can give useful complimentary information to the i-vectors and boost the classification accuracy. The results also show the efficacy of this technique to learn those characteristics from large amounts of unlabeled training set which has no prior information about the environment of the test set.