 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Generic Transformer: Deconstructing a Strong Baseline for Time Series Foundation Models
Feb 06, 2026The recent surge in Time Series Foundation Models has rapidly advanced the field, yet the heterogeneous training setups across studies make it difficult to attribute improvements to architectural innovations versus data engineering. In this work, we investigate the potential of a standard patch Transformer, demonstrating that this generic architecture achieves state-of-the-art zero-shot forecasting performance using a straightforward training protocol. We conduct a comprehensive ablation study that covers model scaling, data composition, and training techniques to isolate the essential ingredients for high performance. Our findings identify the key drivers of performance, while confirming that the generic architecture itself demonstrates excellent scalability. By strictly controlling these variables, we provide comprehensive empirical results on model scaling across multiple dimensions. We release our open-source model and detailed findings to establish a transparent, reproducible baseline for future research.
AssetOpsBench: Benchmarking AI Agents for Task Automation in Industrial Asset Operations and Maintenance
Jun 04, 2025AI for Industrial Asset Lifecycle Management aims to automate complex operational workflows -- such as condition monitoring, maintenance planning, and intervention scheduling -- to reduce human workload and minimize system downtime. Traditional AI/ML approaches have primarily tackled these problems in isolation, solving narrow tasks within the broader operational pipeline. In contrast, the emergence of AI agents and large language models (LLMs) introduces a next-generation opportunity: enabling end-to-end automation across the entire asset lifecycle. This paper envisions a future where AI agents autonomously manage tasks that previously required distinct expertise and manual coordination. To this end, we introduce AssetOpsBench -- a unified framework and environment designed to guide the development, orchestration, and evaluation of domain-specific agents tailored for Industry 4.0 applications. We outline the key requirements for such holistic systems and provide actionable insights into building agents that integrate perception, reasoning, and control for real-world industrial operations. The software is available at https://github.com/IBM/AssetOpsBench.
TSPulse: Dual Space Tiny Pre-Trained Models for Rapid Time-Series Analysis
May 19, 2025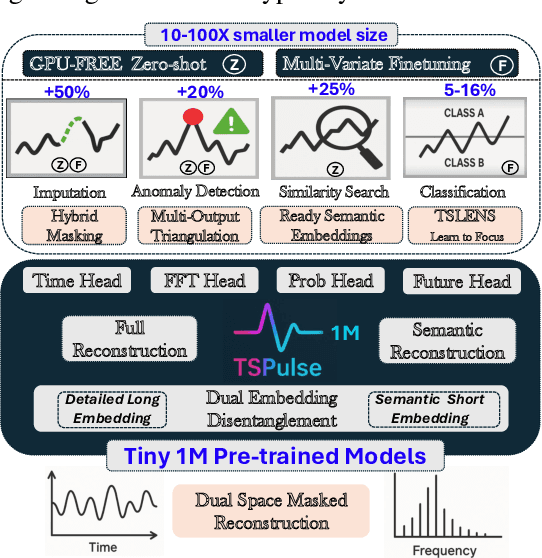

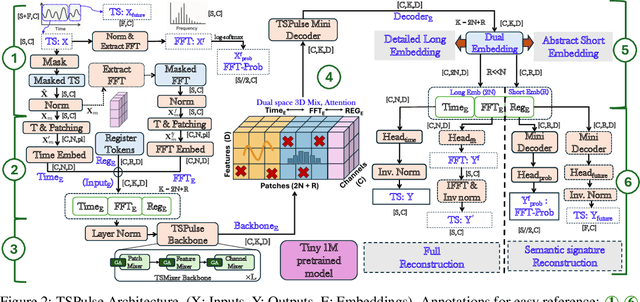

The rise of time-series pre-trained models has advanced temporal representation learning, but current state-of-the-art models are often large-scale, requiring substantial compute. We introduce TSPulse, ultra-compact time-series pre-trained models with only 1M parameters, specialized to perform strongly across classification, anomaly detection, imputation, and retrieval tasks. TSPulse introduces innovations at both the architecture and task levels. At the architecture level, it employs a dual-space masked reconstruction, learning from both time and frequency domains to capture complementary signals. This is further enhanced by a dual-embedding disentanglement, generating both detailed embeddings for fine-grained analysis and high-level semantic embeddings for broader task understanding. Notably, TSPulse's semantic embeddings are robust to shifts in time, magnitude, and noise, which is important for robust retrieval. At the task level, TSPulse incorporates TSLens, a fine-tuning component enabling task-specific feature attention. It also introduces a multi-head triangulation technique that correlates deviations from multiple prediction heads, enhancing anomaly detection by fusing complementary model outputs. Additionally, a hybrid mask pretraining is proposed to improves zero-shot imputation by reducing pre-training bias. These architecture and task innovations collectively contribute to TSPulse's significant performance gains: 5-16% on the UEA classification benchmarks, +20% on the TSB-AD anomaly detection leaderboard, +50% in zero-shot imputation, and +25% in time-series retrieval. Remarkably, these results are achieved with just 1M parameters, making TSPulse 10-100X smaller than existing pre-trained models. Its efficiency enables GPU-free inference and rapid pre-training, setting a new standard for efficient time-series pre-trained models. Models will be open-sourced soon.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024
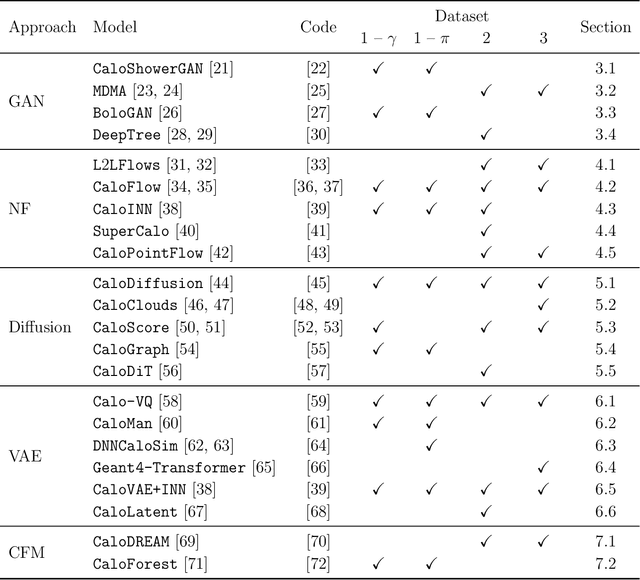
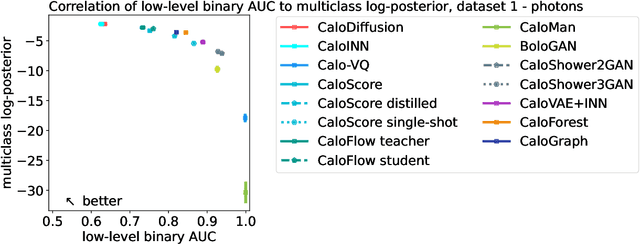
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Tiny Time Mixers : Fast Pre-trained Models for Enhanced Zero/Few-Shot Forecasting of Multivariate Time Series
Jan 17, 2024Large pre-trained models for zero/few-shot learning excel in language and vision domains but encounter challenges in multivariate time series (TS) due to the diverse nature and scarcity of publicly available pre-training data. Consequently, there has been a recent surge in utilizing pre-trained large language models (LLMs) with token adaptations for TS forecasting. These approaches employ cross-domain transfer learning and surprisingly yield impressive results. However, these models are typically very slow and large (~billion parameters) and do not consider cross-channel correlations. To address this, we present Tiny Time Mixers (TTM), a significantly small model based on the lightweight TSMixer architecture. TTM marks the first success in developing fast and tiny general pre-trained models (<1M parameters), exclusively trained on public TS datasets, with effective transfer learning capabilities for forecasting. To tackle the complexity of pre-training on multiple datasets with varied temporal resolutions, we introduce several novel enhancements such as adaptive patching, dataset augmentation via downsampling, and resolution prefix tuning. Moreover, we employ a multi-level modeling strategy to effectively model channel correlations and infuse exogenous signals during fine-tuning, a crucial capability lacking in existing benchmarks. TTM shows significant accuracy gains (12-38\%) over popular benchmarks in few/zero-shot forecasting. It also drastically reduces the compute needs as compared to LLM-TS methods, with a 14X cut in learnable parameters, 106X less total parameters, and substantial reductions in fine-tuning (65X) and inference time (54X). In fact, TTM's zero-shot often surpasses the few-shot results in many popular benchmarks, highlighting the efficacy of our approach. Code and pre-trained models will be open-sourced.
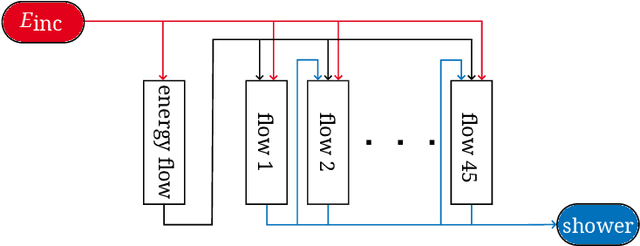
AutoMixer for Improved Multivariate Time-Series Forecasting on Business and IT Observability Data
Nov 02, 2023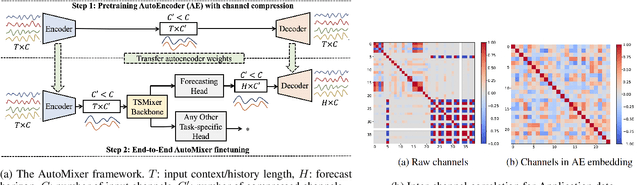
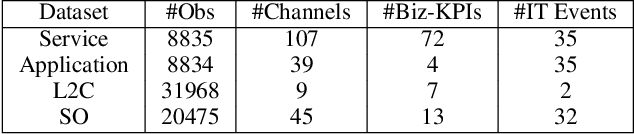
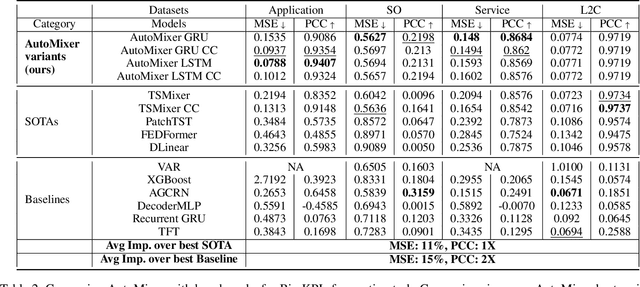
The efficiency of business processes relies on business key performance indicators (Biz-KPIs), that can be negatively impacted by IT failures. Business and IT Observability (BizITObs) data fuses both Biz-KPIs and IT event channels together as multivariate time series data. Forecasting Biz-KPIs in advance can enhance efficiency and revenue through proactive corrective measures. However, BizITObs data generally exhibit both useful and noisy inter-channel interactions between Biz-KPIs and IT events that need to be effectively decoupled. This leads to suboptimal forecasting performance when existing multivariate forecasting models are employed. To address this, we introduce AutoMixer, a time-series Foundation Model (FM) approach, grounded on the novel technique of channel-compressed pretrain and finetune workflows. AutoMixer leverages an AutoEncoder for channel-compressed pretraining and integrates it with the advanced TSMixer model for multivariate time series forecasting. This fusion greatly enhances the potency of TSMixer for accurate forecasts and also generalizes well across several downstream tasks. Through detailed experiments and dashboard analytics, we show AutoMixer's capability to consistently improve the Biz-KPI's forecasting accuracy (by 11-15\%) which directly translates to actionable business insights.
TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting
Jun 28, 2023


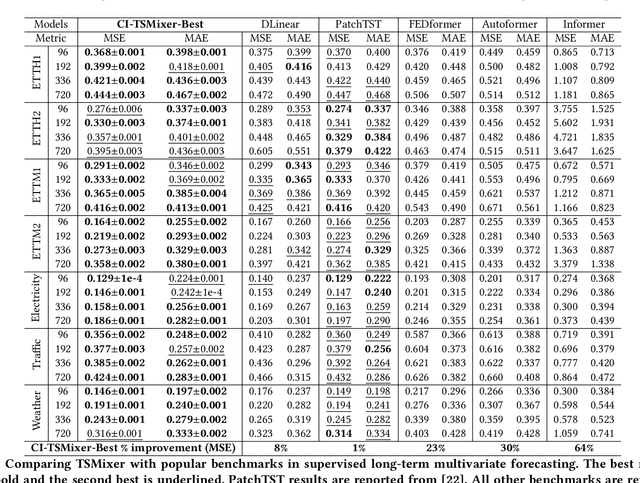
Transformers have gained popularity in time series forecasting for their ability to capture long-sequence interactions. However, their high memory and computing requirements pose a critical bottleneck for long-term forecasting. To address this, we propose TSMixer, a lightweight neural architecture exclusively composed of multi-layer perceptron (MLP) modules. TSMixer is designed for multivariate forecasting and representation learning on patched time series, providing an efficient alternative to Transformers. Our model draws inspiration from the success of MLP-Mixer models in computer vision. We demonstrate the challenges involved in adapting Vision MLP-Mixer for time series and introduce empirically validated components to enhance accuracy. This includes a novel design paradigm of attaching online reconciliation heads to the MLP-Mixer backbone, for explicitly modeling the time-series properties such as hierarchy and channel-correlations. We also propose a Hybrid channel modeling approach to effectively handle noisy channel interactions and generalization across diverse datasets, a common challenge in existing patch channel-mixing methods. Additionally, a simple gated attention mechanism is introduced in the backbone to prioritize important features. By incorporating these lightweight components, we significantly enhance the learning capability of simple MLP structures, outperforming complex Transformer models with minimal computing usage. Moreover, TSMixer's modular design enables compatibility with both supervised and masked self-supervised learning methods, making it a promising building block for time-series Foundation Models. TSMixer outperforms state-of-the-art MLP and Transformer models in forecasting by a considerable margin of 8-60%. It also outperforms the latest strong benchmarks of Patch-Transformer models (by 1-2%) with a significant reduction in memory and runtime (2-3X).
An End-to-End Time Series Model for Simultaneous Imputation and Forecast
Jun 01, 2023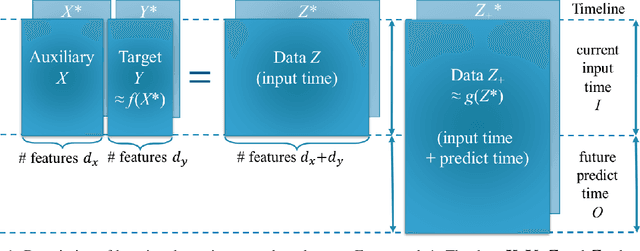
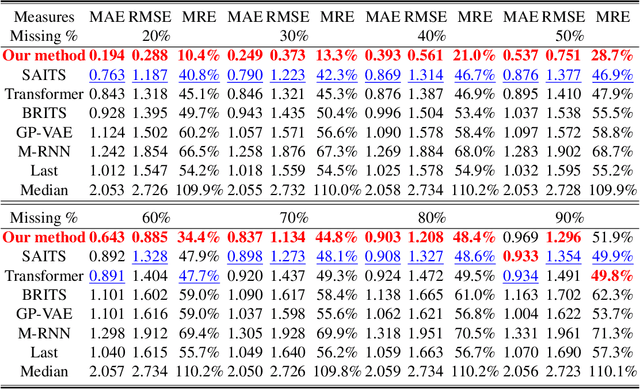
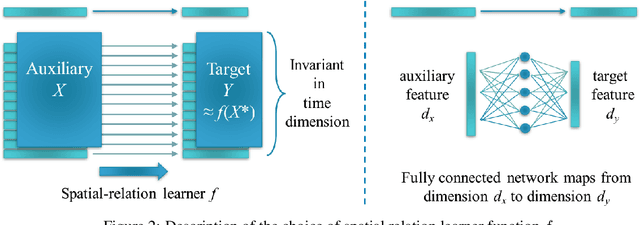
Time series forecasting using historical data has been an interesting and challenging topic, especially when the data is corrupted by missing values. In many industrial problem, it is important to learn the inference function between the auxiliary observations and target variables as it provides additional knowledge when the data is not fully observed. We develop an end-to-end time series model that aims to learn the such inference relation and make a multiple-step ahead forecast. Our framework trains jointly two neural networks, one to learn the feature-wise correlations and the other for the modeling of temporal behaviors. Our model is capable of simultaneously imputing the missing entries and making a multiple-step ahead prediction. The experiments show good overall performance of our framework over existing methods in both imputation and forecasting tasks.
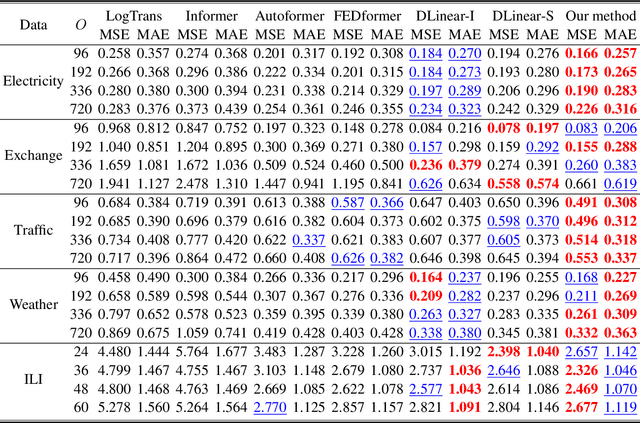
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nov 27, 2022We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. Patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models. We also apply our model to self-supervised pre-training tasks and attain excellent fine-tuning performance, which outperforms supervised training on large datasets. Transferring of masked pre-trained representation on one dataset to others also produces SOTA forecasting accuracy. Code is available at: https://github.com/yuqinie98/PatchTST.
Interpretable Clustering via Multi-Polytope Machines
Dec 10, 2021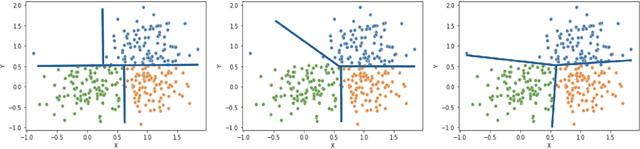
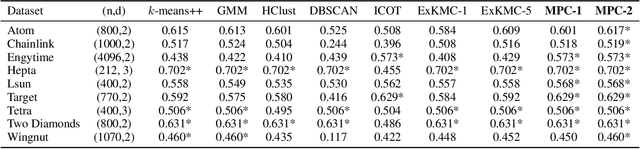


Clustering is a popular unsupervised learning tool often used to discover groups within a larger population such as customer segments, or patient subtypes. However, despite its use as a tool for subgroup discovery and description - few state-of-the-art algorithms provide any rationale or description behind the clusters found. We propose a novel approach for interpretable clustering that both clusters data points and constructs polytopes around the discovered clusters to explain them. Our framework allows for additional constraints on the polytopes - including ensuring that the hyperplanes constructing the polytope are axis-parallel or sparse with integer coefficients. We formulate the problem of constructing clusters via polytopes as a Mixed-Integer Non-Linear Program (MINLP). To solve our formulation we propose a two phase approach where we first initialize clusters and polytopes using alternating minimization, and then use coordinate descent to boost clustering performance. We benchmark our approach on a suite of synthetic and real world clustering problems, where our algorithm outperforms state of the art interpretable and non-interpretable clustering algorithms.