 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Minimum Representation Clustering via Integer Programming
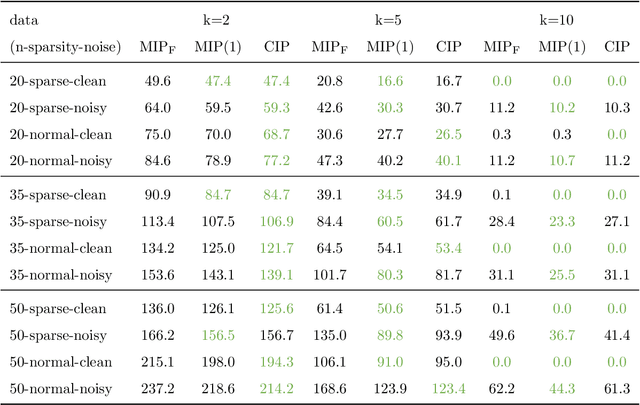
Sep 04, 2024Clustering is an unsupervised learning task that aims to partition data into a set of clusters. In many applications, these clusters correspond to real-world constructs (e.g., electoral districts, playlists, TV channels) whose benefit can only be attained by groups when they reach a minimum level of representation (e.g., 50\% to elect their desired candidate). In this paper, we study the k-means and k-medians clustering problems with the additional constraint that each group (e.g., demographic group) must have a minimum level of representation in at least a given number of clusters. We formulate the problem through a mixed-integer optimization framework and present an alternating minimization algorithm, called MiniReL, that directly incorporates the fairness constraints. While incorporating the fairness criteria leads to an NP-Hard assignment problem within the algorithm, we provide computational approaches that make the algorithm practical even for large datasets. Numerical results show that the approach is able to create fairer clusters with practically no increase in the clustering cost across standard benchmark datasets.
Fair Minimum Representation Clustering
Feb 08, 2023Clustering is an unsupervised learning task that aims to partition data into a set of clusters. In many applications, these clusters correspond to real-world constructs (e.g. electoral districts) whose benefit can only be attained by groups when they reach a minimum level of representation (e.g. 50\% to elect their desired candidate). This paper considers the problem of performing k-means clustering while ensuring groups (e.g. demographic groups) have that minimum level of representation in a specified number of clusters. We show that the popular $k$-means algorithm, Lloyd's algorithm, can result in unfair outcomes where certain groups lack sufficient representation past the minimum threshold in a proportional number of clusters. We formulate the problem through a mixed-integer optimization framework and present a variant of Lloyd's algorithm, called MiniReL, that directly incorporates the fairness constraints. We show that incorporating the fairness criteria leads to a NP-Hard sub-problem within Lloyd's algorithm, but we provide computational approaches that make the problem tractable for even large datasets. Numerical results show that the approach is able to create fairer clusters with practically no increase in the k-means clustering cost across standard benchmark datasets.
Cluster Explanation via Polyhedral Descriptions
Oct 17, 2022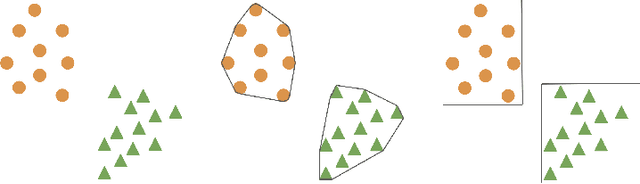
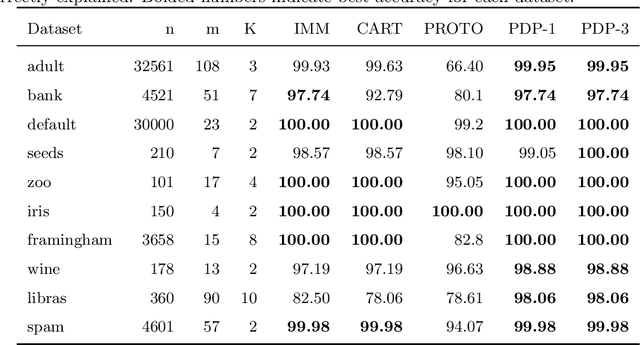
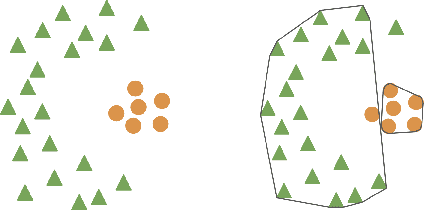
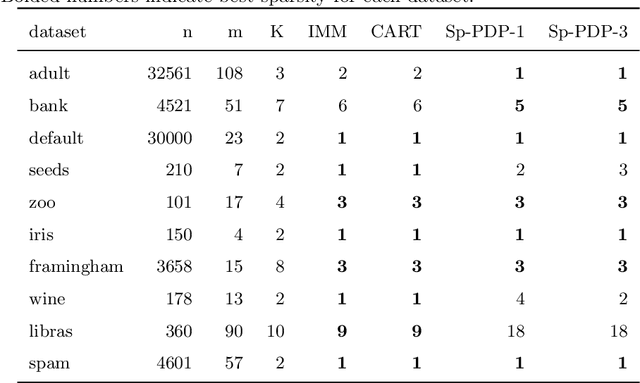
Clustering is an unsupervised learning problem that aims to partition unlabelled data points into groups with similar features. Traditional clustering algorithms provide limited insight into the groups they find as their main focus is accuracy and not the interpretability of the group assignments. This has spurred a recent line of work on explainable machine learning for clustering. In this paper we focus on the cluster description problem where, given a dataset and its partition into clusters, the task is to explain the clusters. We introduce a new approach to explain clusters by constructing polyhedra around each cluster while minimizing either the complexity of the resulting polyhedra or the number of features used in the description. We formulate the cluster description problem as an integer program and present a column generation approach to search over an exponential number of candidate half-spaces that can be used to build the polyhedra. To deal with large datasets, we introduce a novel grouping scheme that first forms smaller groups of data points and then builds the polyhedra around the grouped data, a strategy which out-performs simply sub-sampling data. Compared to state of the art cluster description algorithms, our approach is able to achieve competitive interpretability with improved description accuracy.
Interpretable and Fair Boolean Rule Sets via Column Generation
Nov 16, 2021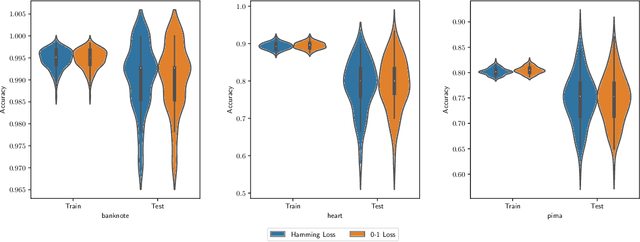
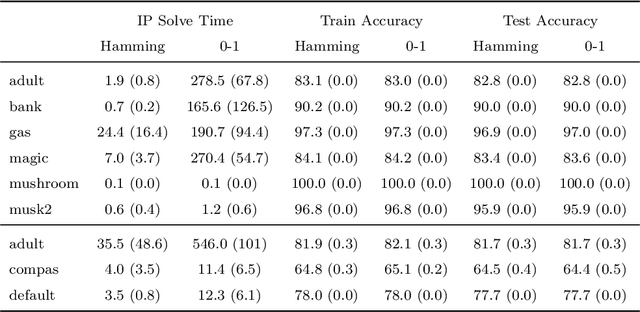
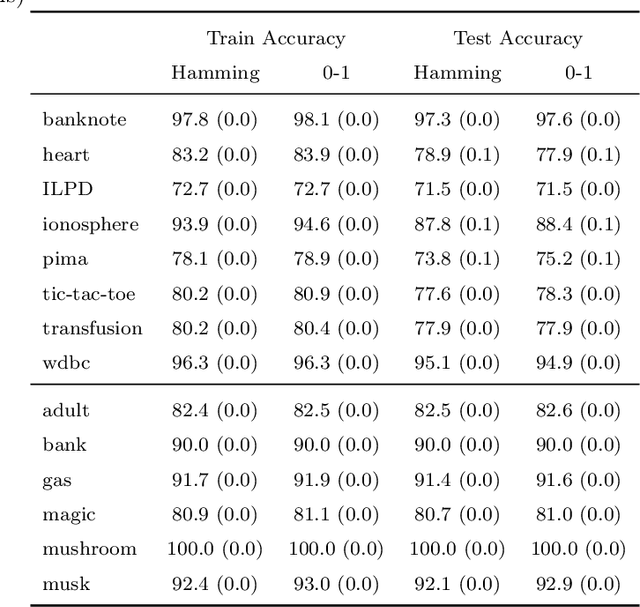
This paper considers the learning of Boolean rules in either disjunctive normal form (DNF, OR-of-ANDs, equivalent to decision rule sets) or conjunctive normal form (CNF, AND-of-ORs) as an interpretable model for classification. An integer program is formulated to optimally trade classification accuracy for rule simplicity. We also consider the fairness setting and extend the formulation to include explicit constraints on two different measures of classification parity: equality of opportunity and equalized odds. Column generation (CG) is used to efficiently search over an exponential number of candidate clauses (conjunctions or disjunctions) without the need for heuristic rule mining. This approach also bounds the gap between the selected rule set and the best possible rule set on the training data. To handle large datasets, we propose an approximate CG algorithm using randomization. Compared to three recently proposed alternatives, the CG algorithm dominates the accuracy-simplicity trade-off in 8 out of 16 datasets. When maximized for accuracy, CG is competitive with rule learners designed for this purpose, sometimes finding significantly simpler solutions that are no less accurate. Compared to other fair and interpretable classifiers, our method is able to find rule sets that meet stricter notions of fairness with a modest trade-off in accuracy.
Fair Decision Rules for Binary Classification
Jul 03, 2021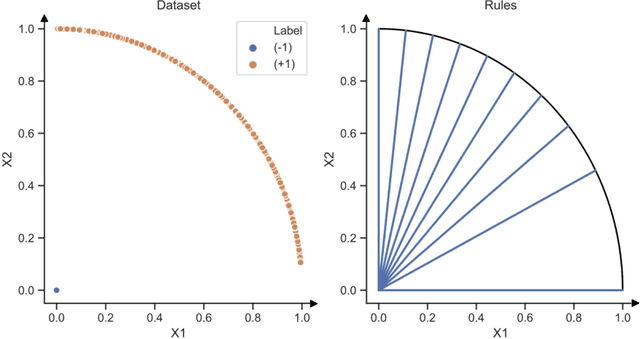


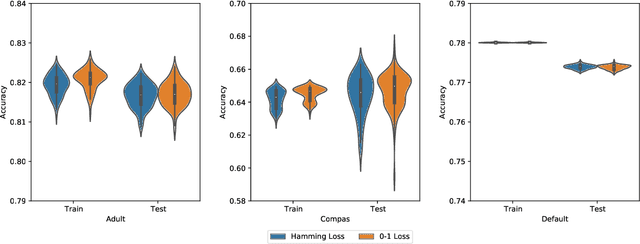
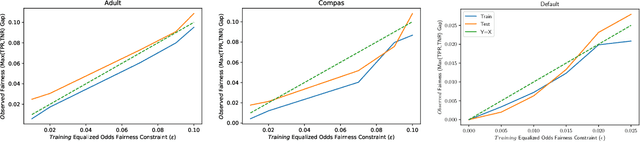
In recent years, machine learning has begun automating decision making in fields as varied as college admissions, credit lending, and criminal sentencing. The socially sensitive nature of some of these applications together with increasing regulatory constraints has necessitated the need for algorithms that are both fair and interpretable. In this paper we consider the problem of building Boolean rule sets in disjunctive normal form (DNF), an interpretable model for binary classification, subject to fairness constraints. We formulate the problem as an integer program that maximizes classification accuracy with explicit constraints on two different measures of classification parity: equality of opportunity and equalized odds. Column generation framework, with a novel formulation, is used to efficiently search over exponentially many possible rules. When combined with faster heuristics, our method can deal with large data-sets. Compared to other fair and interpretable classifiers, our method is able to find rule sets that meet stricter notions of fairness with a modest trade-off in accuracy.
Binary Matrix Factorisation and Completion via Integer Programming
Jun 25, 2021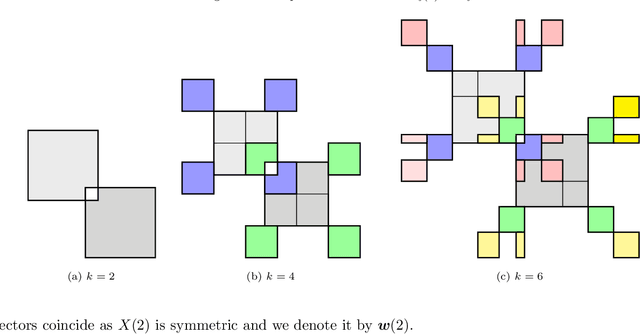

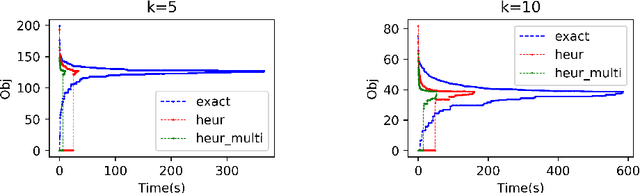
Binary matrix factorisation is an essential tool for identifying discrete patterns in binary data. In this paper we consider the rank-k binary matrix factorisation problem (k-BMF) under Boolean arithmetic: we are given an n x m binary matrix X with possibly missing entries and need to find two binary matrices A and B of dimension n x k and k x m respectively, which minimise the distance between X and the Boolean product of A and B in the squared Frobenius distance. We present a compact and two exponential size integer programs (IPs) for k-BMF and show that the compact IP has a weak LP relaxation, while the exponential size LPs have a stronger equivalent LP relaxation. We introduce a new objective function, which differs from the traditional squared Frobenius objective in attributing a weight to zero entries of the input matrix that is proportional to the number of times the zero is erroneously covered in a rank-k factorisation. For one of the exponential size IPs we describe a computational approach based on column generation. Experimental results on synthetic and real word datasets suggest that our integer programming approach is competitive against available methods for k-BMF and provides accurate low-error factorisations.
Binary Matrix Factorisation via Column Generation
Nov 09, 2020
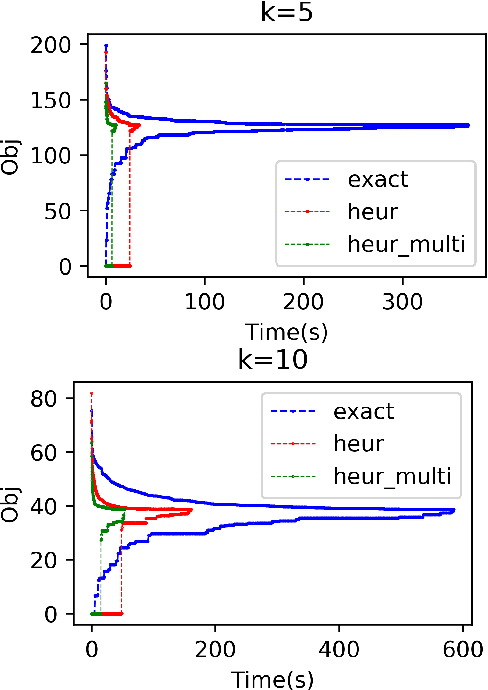
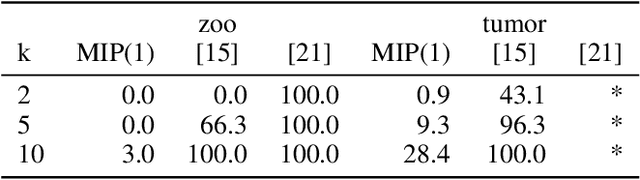
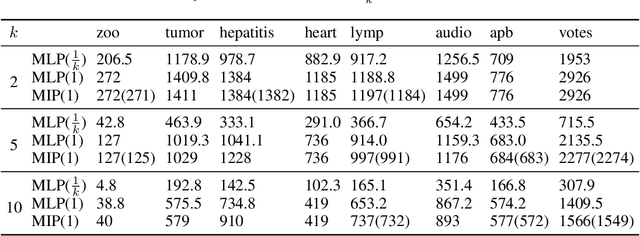
Identifying discrete patterns in binary data is an important dimensionality reduction tool in machine learning and data mining. In this paper, we consider the problem of low-rank binary matrix factorisation (BMF) under Boolean arithmetic. Due to the NP-hardness of this problem, most previous attempts rely on heuristic techniques. We formulate the problem as a mixed integer linear program and use a large scale optimisation technique of column generation to solve it without the need of heuristic pattern mining. Our approach focuses on accuracy and on the provision of optimality guarantees. Experimental results on real world datasets demonstrate that our proposed method is effective at producing highly accurate factorisations and improves on the previously available best known results for 16 out of 24 problem instances.
Multilabel Classification by Hierarchical Partitioning and Data-dependent Grouping
Jun 24, 2020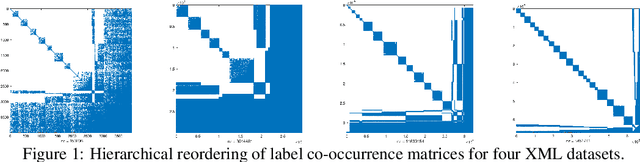
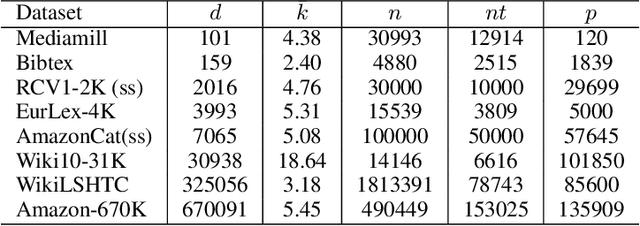
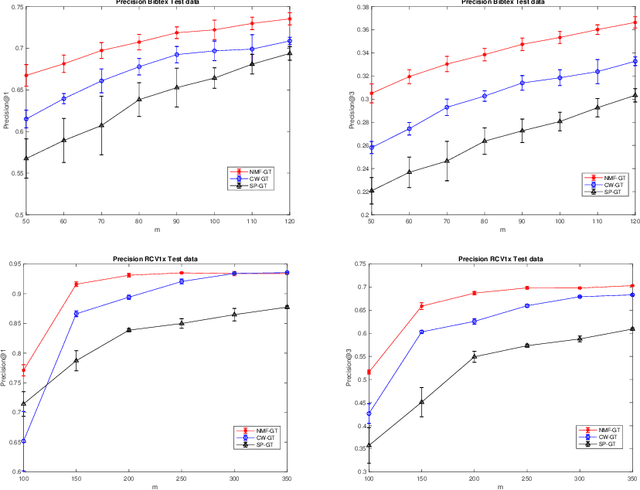
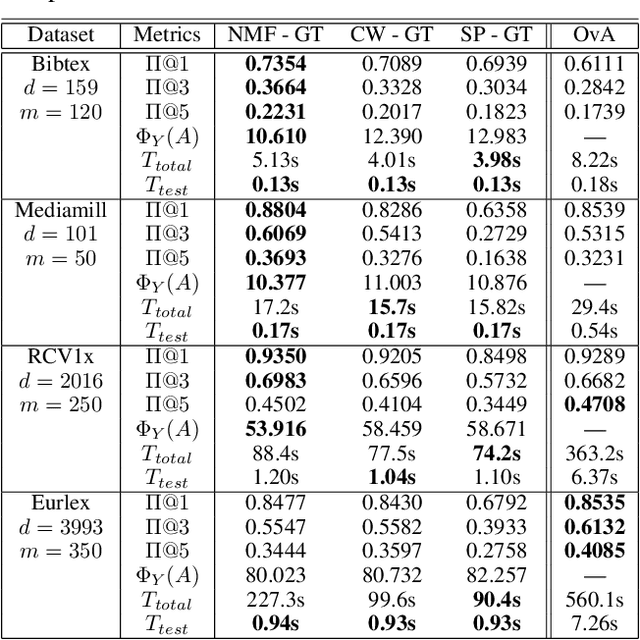
In modern multilabel classification problems, each data instance belongs to a small number of classes from a large set of classes. In other words, these problems involve learning very sparse binary label vectors. Moreover, in large-scale problems, the labels typically have certain (unknown) hierarchy. In this paper we exploit the sparsity of label vectors and the hierarchical structure to embed them in low-dimensional space using label groupings. Consequently, we solve the classification problem in a much lower dimensional space and then obtain labels in the original space using an appropriately defined lifting. Our method builds on the work of (Ubaru & Mazumdar, 2017), where the idea of group testing was also explored for multilabel classification. We first present a novel data-dependent grouping approach, where we use a group construction based on a low-rank Nonnegative Matrix Factorization (NMF) of the label matrix of training instances. The construction also allows us, using recent results, to develop a fast prediction algorithm that has a logarithmic runtime in the number of labels. We then present a hierarchical partitioning approach that exploits the label hierarchy in large scale problems to divide up the large label space and create smaller sub-problems, which can then be solved independently via the grouping approach. Numerical results on many benchmark datasets illustrate that, compared to other popular methods, our proposed methods achieve competitive accuracy with significantly lower computational costs.
Low-Rank Boolean Matrix Approximation by Integer Programming
Mar 13, 2018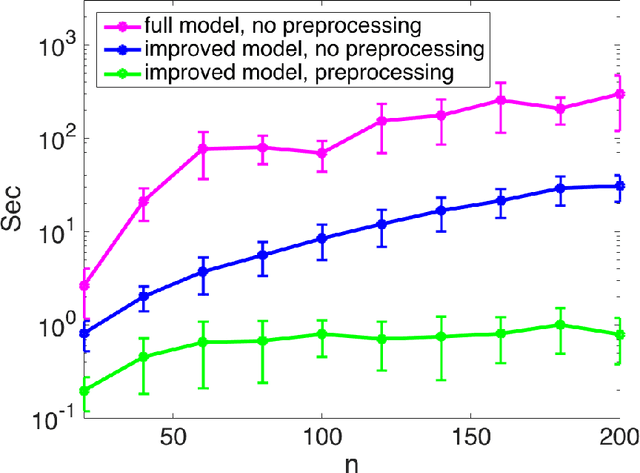
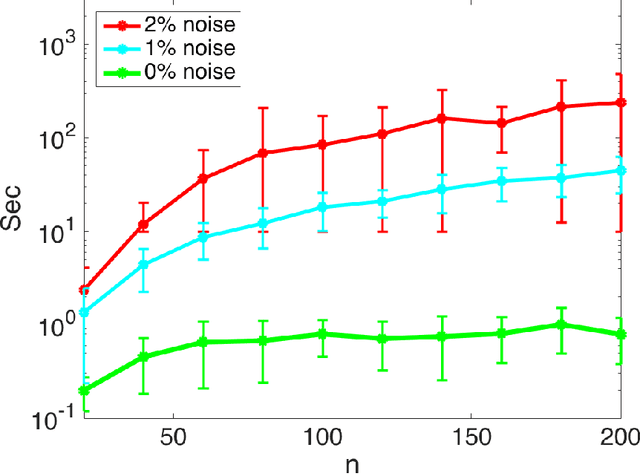
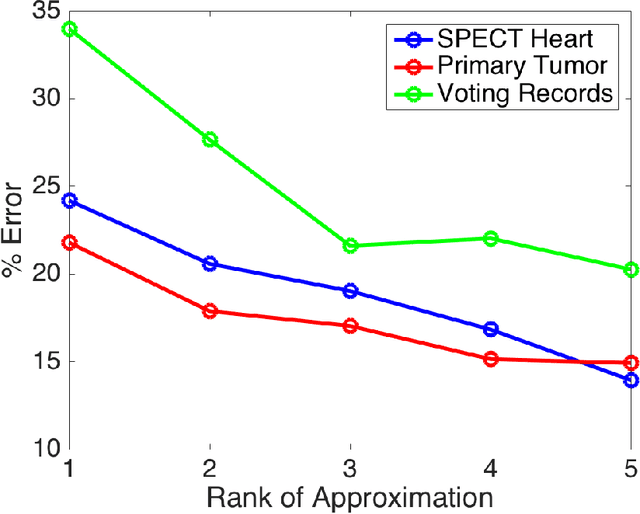
Low-rank approximations of data matrices are an important dimensionality reduction tool in machine learning and regression analysis. We consider the case of categorical variables, where it can be formulated as the problem of finding low-rank approximations to Boolean matrices. In this paper we give what is to the best of our knowledge the first integer programming formulation that relies on only polynomially many variables and constraints, we discuss how to solve it computationally and report numerical tests on synthetic and real-world data.
Optimal Generalized Decision Trees via Integer Programming
Jan 14, 2018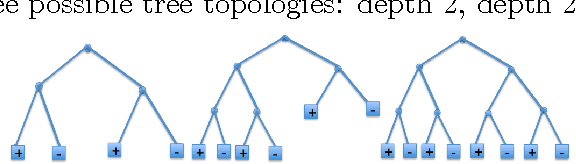
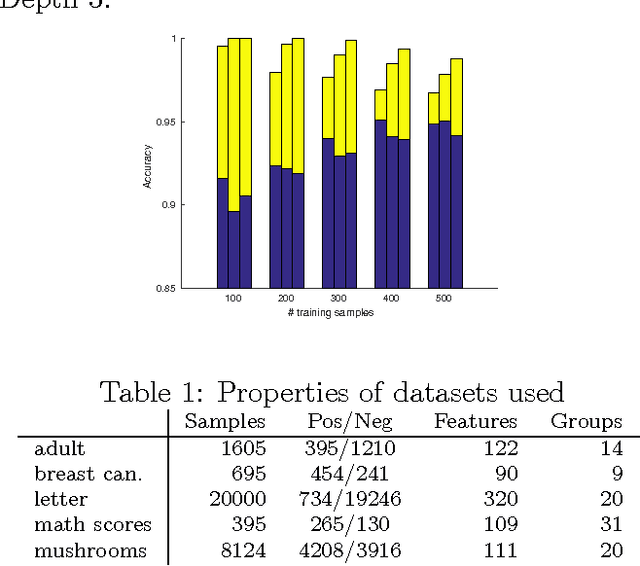
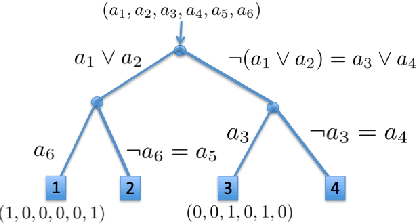

Decision trees have been a very popular class of predictive models for decades due to their interpretability and good performance on categorical features. However, they are not always robust and tend to overfit the data. Additionally, if allowed to grow large, they lose interpretability. In this paper, we present a novel mixed integer programming formulation to construct optimal decision trees of specified size. We take special structure of categorical features into account and allow combinatorial decisions (based on subsets of values of such a feature) at each node. We show that very good accuracy can be achieved with small trees using moderately-sized training sets. The optimization problems we solve are easily tractable with modern solvers.