 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Compressors in Distributed Mean Estimation with Limited Communication Budget
Jan 26, 2026Distributed high dimensional mean estimation is a common aggregation routine used often in distributed optimization methods. Most of these applications call for a communication-constrained setting where vectors, whose mean is to be estimated, have to be compressed before sharing. One could independently encode and decode these to achieve compression, but that overlooks the fact that these vectors are often close to each other. To exploit these similarities, recently Suresh et al., 2022, Jhunjhunwala et al., 2021, Jiang et al, 2023, proposed multiple correlation-aware compression schemes. However, in most cases, the correlations have to be known for these schemes to work. Moreover, a theoretical analysis of graceful degradation of these correlation-aware compression schemes with increasing dissimilarity is limited to only the $\ell_2$-error in the literature. In this paper, we propose four different collaborative compression schemes that agnostically exploit the similarities among vectors in a distributed setting. Our schemes are all simple to implement and computationally efficient, while resulting in big savings in communication. The analysis of our proposed schemes show how the $\ell_2$, $\ell_\infty$ and cosine estimation error varies with the degree of similarity among vectors.
Generalization Bound of Gradient Flow through Training Trajectory and Data-dependent Kernel
Jun 12, 2025Gradient-based optimization methods have shown remarkable empirical success, yet their theoretical generalization properties remain only partially understood. In this paper, we establish a generalization bound for gradient flow that aligns with the classical Rademacher complexity bounds for kernel methods-specifically those based on the RKHS norm and kernel trace-through a data-dependent kernel called the loss path kernel (LPK). Unlike static kernels such as NTK, the LPK captures the entire training trajectory, adapting to both data and optimization dynamics, leading to tighter and more informative generalization guarantees. Moreover, the bound highlights how the norm of the training loss gradients along the optimization trajectory influences the final generalization performance. The key technical ingredients in our proof combine stability analysis of gradient flow with uniform convergence via Rademacher complexity. Our bound recovers existing kernel regression bounds for overparameterized neural networks and shows the feature learning capability of neural networks compared to kernel methods. Numerical experiments on real-world datasets validate that our bounds correlate well with the true generalization gap.
LocalKMeans: Convergence of Lloyd's Algorithm with Distributed Local Iterations
May 23, 2025In this paper, we analyze the classical $K$-means alternating-minimization algorithm, also known as Lloyd's algorithm (Lloyd, 1956), for a mixture of Gaussians in a data-distributed setting that incorporates local iteration steps. Assuming unlabeled data distributed across multiple machines, we propose an algorithm, LocalKMeans, that performs Lloyd's algorithm in parallel in the machines by running its iterations on local data, synchronizing only every $L$ of such local steps. We characterize the cost of these local iterations against the non-distributed setting, and show that the price paid for the local steps is a higher required signal-to-noise ratio. While local iterations were theoretically studied in the past for gradient-based learning methods, the analysis of unsupervised learning methods is more involved owing to the presence of latent variables, e.g. cluster identities, than that of an iterative gradient-based algorithm. To obtain our results, we adapt a virtual iterate method to work with a non-convex, non-smooth objective function, in conjunction with a tight statistical analysis of Lloyd steps.
Learning and Generalization with Mixture Data
Apr 29, 2025In many, if not most, machine learning applications the training data is naturally heterogeneous (e.g. federated learning, adversarial attacks and domain adaptation in neural net training). Data heterogeneity is identified as one of the major challenges in modern day large-scale learning. A classical way to represent heterogeneous data is via a mixture model. In this paper, we study generalization performance and statistical rates when data is sampled from a mixture distribution. We first characterize the heterogeneity of the mixture in terms of the pairwise total variation distance of the sub-population distributions. Thereafter, as a central theme of this paper, we characterize the range where the mixture may be treated as a single (homogeneous) distribution for learning. In particular, we study the generalization performance under the classical PAC framework and the statistical error rates for parametric (linear regression, mixture of hyperplanes) as well as non-parametric (Lipschitz, convex and H\"older-smooth) regression problems. In order to do this, we obtain Rademacher complexity and (local) Gaussian complexity bounds with mixture data, and apply them to get the generalization and convergence rates respectively. We observe that as the (regression) function classes get more complex, the requirement on the pairwise total variation distance gets stringent, which matches our intuition. We also do a finer analysis for the case of mixed linear regression and provide a tight bound on the generalization error in terms of heterogeneity.
Client Selection in Federated Learning with Data Heterogeneity and Network Latencies
Apr 02, 2025


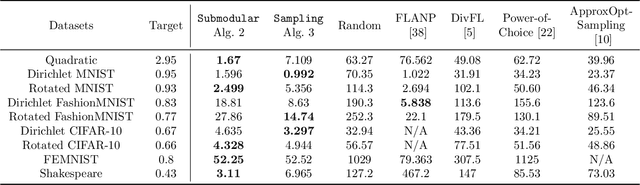
Federated learning (FL) is a distributed machine learning paradigm where multiple clients conduct local training based on their private data, then the updated models are sent to a central server for global aggregation. The practical convergence of FL is challenged by multiple factors, with the primary hurdle being the heterogeneity among clients. This heterogeneity manifests as data heterogeneity concerning local data distribution and latency heterogeneity during model transmission to the server. While prior research has introduced various efficient client selection methods to alleviate the negative impacts of either of these heterogeneities individually, efficient methods to handle real-world settings where both these heterogeneities exist simultaneously do not exist. In this paper, we propose two novel theoretically optimal client selection schemes that can handle both these heterogeneities. Our methods involve solving simple optimization problems every round obtained by minimizing the theoretical runtime to convergence. Empirical evaluations on 9 datasets with non-iid data distributions, 2 practical delay distributions, and non-convex neural network models demonstrate that our algorithms are at least competitive to and at most 20 times better than best existing baselines.
Learning sparse generalized linear models with binary outcomes via iterative hard thresholding
Feb 25, 2025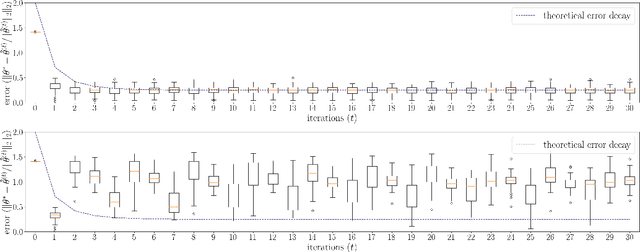
In statistics, generalized linear models (GLMs) are widely used for modeling data and can expressively capture potential nonlinear dependence of the model's outcomes on its covariates. Within the broad family of GLMs, those with binary outcomes, which include logistic and probit regressions, are motivated by common tasks such as binary classification with (possibly) non-separable data. In addition, in modern machine learning and statistics, data is often high-dimensional yet has a low intrinsic dimension, making sparsity constraints in models another reasonable consideration. In this work, we propose to use and analyze an iterative hard thresholding (projected gradient descent on the ReLU loss) algorithm, called binary iterative hard thresholding (BIHT), for parameter estimation in sparse GLMs with binary outcomes. We establish that BIHT is statistically efficient and converges to the correct solution for parameter estimation in a general class of sparse binary GLMs. Unlike many other methods for learning GLMs, including maximum likelihood estimation, generalized approximate message passing, and GLM-tron (Kakade et al. 2011; Bahmani et al. 2016), BIHT does not require knowledge of the GLM's link function, offering flexibility and generality in allowing the algorithm to learn arbitrary binary GLMs. As two applications, logistic and probit regression are additionally studied. In this regard, it is shown that in logistic regression, the algorithm is in fact statistically optimal in the sense that the order-wise sample complexity matches (up to logarithmic factors) the lower bound obtained previously. To the best of our knowledge, this is the first work achieving statistical optimality for logistic regression in all noise regimes with a computationally efficient algorithm. Moreover, for probit regression, our sample complexity is on the same order as that obtained for logistic regression.
Exact Recovery of Sparse Binary Vectors from Generalized Linear Measurements
Feb 21, 2025We consider the problem of exact recovery of a $k$-sparse binary vector from generalized linear measurements (such as logistic regression). We analyze the linear estimation algorithm (Plan, Vershynin, Yudovina, 2017), and also show information theoretic lower bounds on the number of required measurements. As a consequence of our results, for noisy one bit quantized linear measurements ($\mathsf{1bCSbinary}$), we obtain a sample complexity of $O((k+\sigma^2)\log{n})$, where $\sigma^2$ is the noise variance. This is shown to be optimal due to the information theoretic lower bound. We also obtain tight sample complexity characterization for logistic regression. Since $\mathsf{1bCSbinary}$ is a strictly harder problem than noisy linear measurements ($\mathsf{SparseLinearReg}$) because of added quantization, the same sample complexity is achievable for $\mathsf{SparseLinearReg}$. While this sample complexity can be obtained via the popular lasso algorithm, linear estimation is computationally more efficient. Our lower bound holds for any set of measurements for $\mathsf{SparseLinearReg}$, (similar bound was known for Gaussian measurement matrices) and is closely matched by the maximum-likelihood upper bound. For $\mathsf{SparseLinearReg}$, it was conjectured in Gamarnik and Zadik, 2017 that there is a statistical-computational gap and the number of measurements should be at least $(2k+\sigma^2)\log{n}$ for efficient algorithms to exist. It is worth noting that our results imply that there is no such statistical-computational gap for $\mathsf{1bCSbinary}$ and logistic regression.
Distributed Hybrid Sketching for $\ell_2$-Embeddings
Dec 29, 2024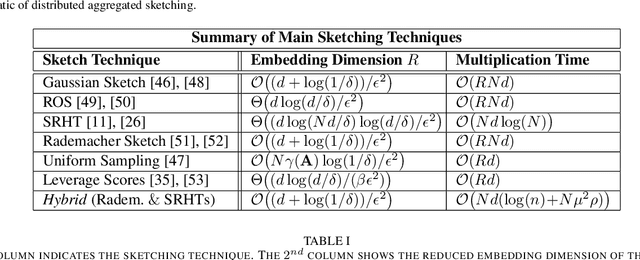
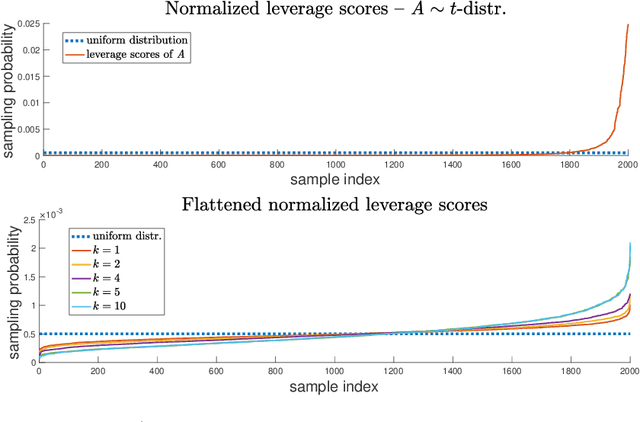
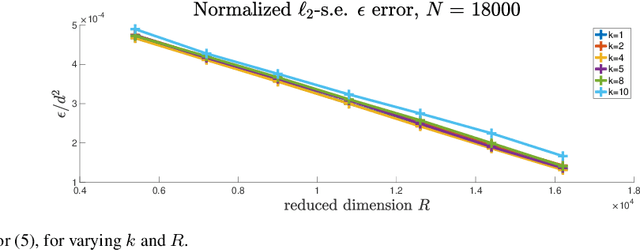
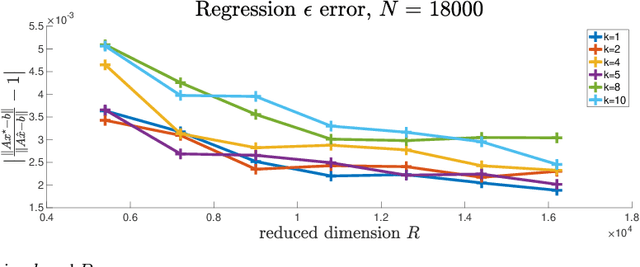
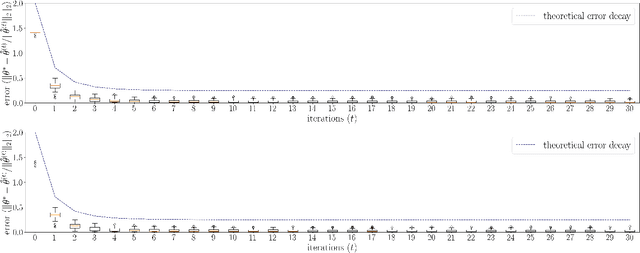
Linear algebraic operations are ubiquitous in engineering applications, and arise often in a variety of fields including statistical signal processing and machine learning. With contemporary large datasets, to perform linear algebraic methods and regression tasks, it is necessary to resort to both distributed computations as well as data compression. In this paper, we study \textit{distributed} $\ell_2$-subspace embeddings, a common technique used to efficiently perform linear regression. In our setting, data is distributed across multiple computing nodes and a goal is to minimize communication between the nodes and the coordinator in the distributed centralized network, while maintaining the geometry of the dataset. Furthermore, there is also the concern of keeping the data private and secure from potential adversaries. In this work, we address these issues through randomized sketching, where the key idea is to apply distinct sketching matrices on the local datasets. A novelty of this work is that we also consider \textit{hybrid sketching}, \textit{i.e.} a second sketch is applied on the aggregated locally sketched datasets, for enhanced embedding results. One of the main takeaways of this work is that by hybrid sketching, we can interpolate between the trade-offs that arise in off-the-shelf sketching matrices. That is, we can obtain gains in terms of embedding dimension or multiplication time. Our embedding arguments are also justified numerically.
Distributed Gradient Descent with Many Local Steps in Overparameterized Models
Dec 10, 2024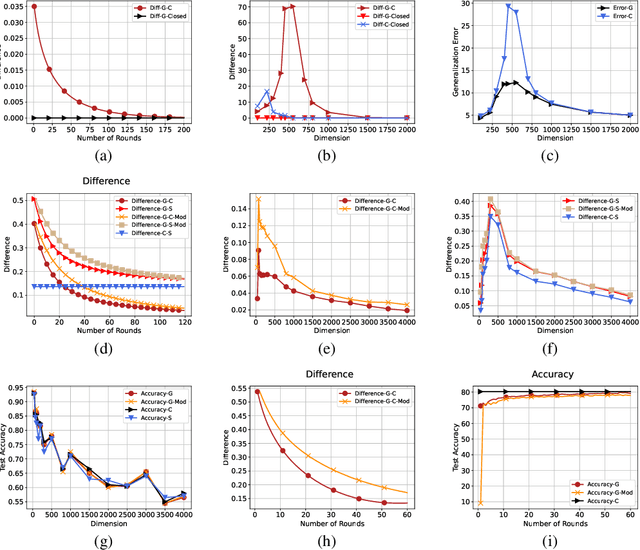
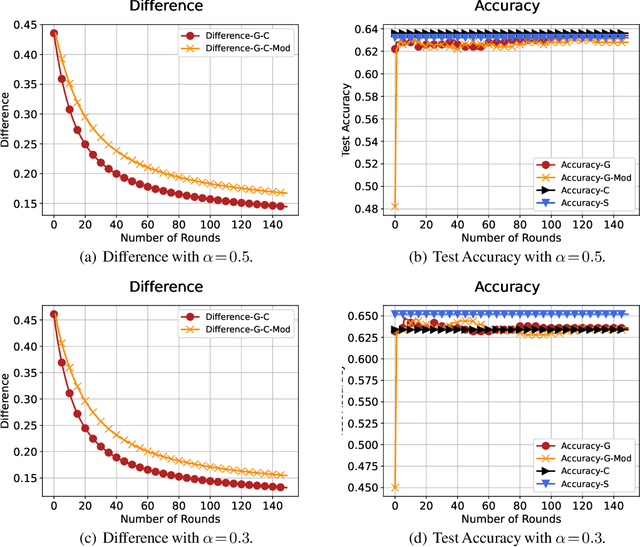
In distributed training of machine learning models, gradient descent with local iterative steps is a very popular method, variants of which are commonly known as Local-SGD or the Federated Averaging (FedAvg). In this method, gradient steps based on local datasets are taken independently in distributed compute nodes to update the local models, which are then aggregated intermittently. Although the existing convergence analysis suggests that with heterogeneous data, FedAvg encounters quick performance degradation as the number of local steps increases, it is shown to work quite well in practice, especially in the distributed training of large language models. In this work we try to explain this good performance from a viewpoint of implicit bias in Local Gradient Descent (Local-GD) with a large number of local steps. In overparameterized regime, the gradient descent at each compute node would lead the model to a specific direction locally. We characterize the dynamics of the aggregated global model and compare it to the centralized model trained with all of the data in one place. In particular, we analyze the implicit bias of gradient descent on linear models, for both regression and classification tasks. Our analysis shows that the aggregated global model converges exactly to the centralized model for regression tasks, and converges (in direction) to the same feasible set as centralized model for classification tasks. We further propose a Modified Local-GD with a refined aggregation and theoretically show it converges to the centralized model in direction for linear classification. We empirically verified our theoretical findings in linear models and also conducted experiments on distributed fine-tuning of pretrained neural networks to further apply our theory.
Sharper Guarantees for Learning Neural Network Classifiers with Gradient Methods
Oct 13, 2024

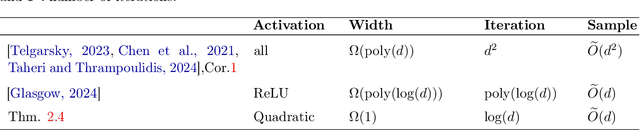

In this paper, we study the data-dependent convergence and generalization behavior of gradient methods for neural networks with smooth activation. Our first result is a novel bound on the excess risk of deep networks trained by the logistic loss, via an alogirthmic stability analysis. Compared to previous works, our results improve upon the shortcomings of the well-established Rademacher complexity-based bounds. Importantly, the bounds we derive in this paper are tighter, hold even for neural networks of small width, do not scale unfavorably with width, are algorithm-dependent, and consequently capture the role of initialization on the sample complexity of gradient descent for deep nets. Specialized to noiseless data separable with margin $\gamma$ by neural tangent kernel (NTK) features of a network of width $\Omega(\poly(\log(n)))$, we show the test-error rate to be $e^{O(L)}/{\gamma^2 n}$, where $n$ is the training set size and $L$ denotes the number of hidden layers. This is an improvement in the test loss bound compared to previous works while maintaining the poly-logarithmic width conditions. We further investigate excess risk bounds for deep nets trained with noisy data, establishing that under a polynomial condition on the network width, gradient descent can achieve the optimal excess risk. Finally, we show that a large step-size significantly improves upon the NTK regime's results in classifying the XOR distribution. In particular, we show for a one-hidden-layer neural network of constant width $m$ with quadratic activation and standard Gaussian initialization that mini-batch SGD with linear sample complexity and with a large step-size $\eta=m$ reaches the perfect test accuracy after only $\ceil{\log(d)}$ iterations, where $d$ is the data dimension.