 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharper Guarantees for Learning Neural Network Classifiers with Gradient Methods
Paper and Code
Oct 13, 2024

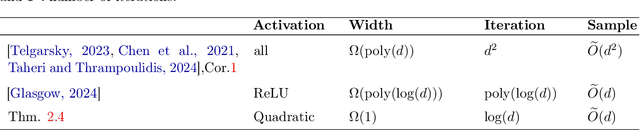

In this paper, we study the data-dependent convergence and generalization behavior of gradient methods for neural networks with smooth activation. Our first result is a novel bound on the excess risk of deep networks trained by the logistic loss, via an alogirthmic stability analysis. Compared to previous works, our results improve upon the shortcomings of the well-established Rademacher complexity-based bounds. Importantly, the bounds we derive in this paper are tighter, hold even for neural networks of small width, do not scale unfavorably with width, are algorithm-dependent, and consequently capture the role of initialization on the sample complexity of gradient descent for deep nets. Specialized to noiseless data separable with margin $\gamma$ by neural tangent kernel (NTK) features of a network of width $\Omega(\poly(\log(n)))$, we show the test-error rate to be $e^{O(L)}/{\gamma^2 n}$, where $n$ is the training set size and $L$ denotes the number of hidden layers. This is an improvement in the test loss bound compared to previous works while maintaining the poly-logarithmic width conditions. We further investigate excess risk bounds for deep nets trained with noisy data, establishing that under a polynomial condition on the network width, gradient descent can achieve the optimal excess risk. Finally, we show that a large step-size significantly improves upon the NTK regime's results in classifying the XOR distribution. In particular, we show for a one-hidden-layer neural network of constant width $m$ with quadratic activation and standard Gaussian initialization that mini-batch SGD with linear sample complexity and with a large step-size $\eta=m$ reaches the perfect test accuracy after only $\ceil{\log(d)}$ iterations, where $d$ is the data dimension.