 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Compressors in Distributed Mean Estimation with Limited Communication Budget
Jan 26, 2026Distributed high dimensional mean estimation is a common aggregation routine used often in distributed optimization methods. Most of these applications call for a communication-constrained setting where vectors, whose mean is to be estimated, have to be compressed before sharing. One could independently encode and decode these to achieve compression, but that overlooks the fact that these vectors are often close to each other. To exploit these similarities, recently Suresh et al., 2022, Jhunjhunwala et al., 2021, Jiang et al, 2023, proposed multiple correlation-aware compression schemes. However, in most cases, the correlations have to be known for these schemes to work. Moreover, a theoretical analysis of graceful degradation of these correlation-aware compression schemes with increasing dissimilarity is limited to only the $\ell_2$-error in the literature. In this paper, we propose four different collaborative compression schemes that agnostically exploit the similarities among vectors in a distributed setting. Our schemes are all simple to implement and computationally efficient, while resulting in big savings in communication. The analysis of our proposed schemes show how the $\ell_2$, $\ell_\infty$ and cosine estimation error varies with the degree of similarity among vectors.
LocalKMeans: Convergence of Lloyd's Algorithm with Distributed Local Iterations
May 23, 2025In this paper, we analyze the classical $K$-means alternating-minimization algorithm, also known as Lloyd's algorithm (Lloyd, 1956), for a mixture of Gaussians in a data-distributed setting that incorporates local iteration steps. Assuming unlabeled data distributed across multiple machines, we propose an algorithm, LocalKMeans, that performs Lloyd's algorithm in parallel in the machines by running its iterations on local data, synchronizing only every $L$ of such local steps. We characterize the cost of these local iterations against the non-distributed setting, and show that the price paid for the local steps is a higher required signal-to-noise ratio. While local iterations were theoretically studied in the past for gradient-based learning methods, the analysis of unsupervised learning methods is more involved owing to the presence of latent variables, e.g. cluster identities, than that of an iterative gradient-based algorithm. To obtain our results, we adapt a virtual iterate method to work with a non-convex, non-smooth objective function, in conjunction with a tight statistical analysis of Lloyd steps.
Learning and Generalization with Mixture Data
Apr 29, 2025In many, if not most, machine learning applications the training data is naturally heterogeneous (e.g. federated learning, adversarial attacks and domain adaptation in neural net training). Data heterogeneity is identified as one of the major challenges in modern day large-scale learning. A classical way to represent heterogeneous data is via a mixture model. In this paper, we study generalization performance and statistical rates when data is sampled from a mixture distribution. We first characterize the heterogeneity of the mixture in terms of the pairwise total variation distance of the sub-population distributions. Thereafter, as a central theme of this paper, we characterize the range where the mixture may be treated as a single (homogeneous) distribution for learning. In particular, we study the generalization performance under the classical PAC framework and the statistical error rates for parametric (linear regression, mixture of hyperplanes) as well as non-parametric (Lipschitz, convex and H\"older-smooth) regression problems. In order to do this, we obtain Rademacher complexity and (local) Gaussian complexity bounds with mixture data, and apply them to get the generalization and convergence rates respectively. We observe that as the (regression) function classes get more complex, the requirement on the pairwise total variation distance gets stringent, which matches our intuition. We also do a finer analysis for the case of mixed linear regression and provide a tight bound on the generalization error in terms of heterogeneity.
Client Selection in Federated Learning with Data Heterogeneity and Network Latencies
Apr 02, 2025


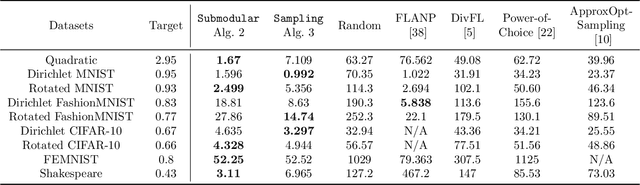
Federated learning (FL) is a distributed machine learning paradigm where multiple clients conduct local training based on their private data, then the updated models are sent to a central server for global aggregation. The practical convergence of FL is challenged by multiple factors, with the primary hurdle being the heterogeneity among clients. This heterogeneity manifests as data heterogeneity concerning local data distribution and latency heterogeneity during model transmission to the server. While prior research has introduced various efficient client selection methods to alleviate the negative impacts of either of these heterogeneities individually, efficient methods to handle real-world settings where both these heterogeneities exist simultaneously do not exist. In this paper, we propose two novel theoretically optimal client selection schemes that can handle both these heterogeneities. Our methods involve solving simple optimization problems every round obtained by minimizing the theoretical runtime to convergence. Empirical evaluations on 9 datasets with non-iid data distributions, 2 practical delay distributions, and non-convex neural network models demonstrate that our algorithms are at least competitive to and at most 20 times better than best existing baselines.
Distributed Gradient Descent with Many Local Steps in Overparameterized Models
Dec 10, 2024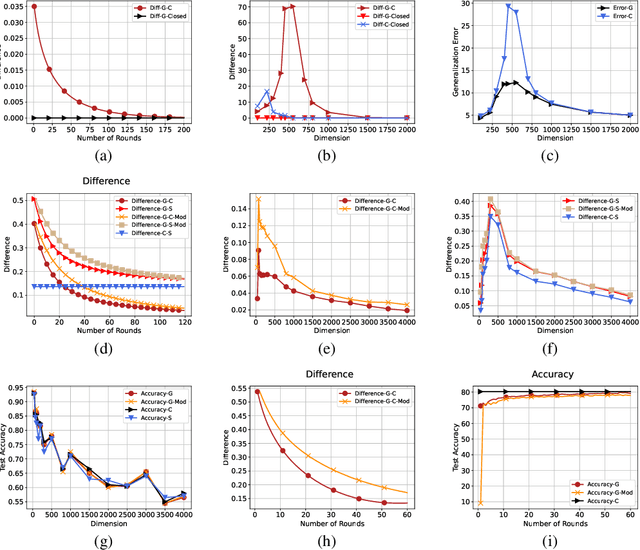
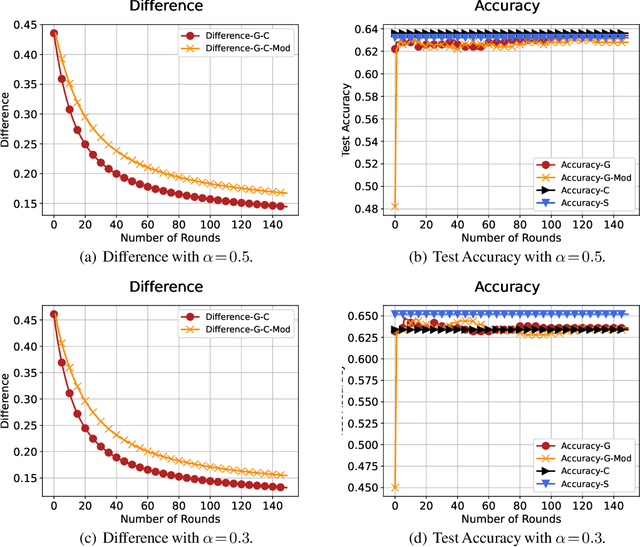
In distributed training of machine learning models, gradient descent with local iterative steps is a very popular method, variants of which are commonly known as Local-SGD or the Federated Averaging (FedAvg). In this method, gradient steps based on local datasets are taken independently in distributed compute nodes to update the local models, which are then aggregated intermittently. Although the existing convergence analysis suggests that with heterogeneous data, FedAvg encounters quick performance degradation as the number of local steps increases, it is shown to work quite well in practice, especially in the distributed training of large language models. In this work we try to explain this good performance from a viewpoint of implicit bias in Local Gradient Descent (Local-GD) with a large number of local steps. In overparameterized regime, the gradient descent at each compute node would lead the model to a specific direction locally. We characterize the dynamics of the aggregated global model and compare it to the centralized model trained with all of the data in one place. In particular, we analyze the implicit bias of gradient descent on linear models, for both regression and classification tasks. Our analysis shows that the aggregated global model converges exactly to the centralized model for regression tasks, and converges (in direction) to the same feasible set as centralized model for classification tasks. We further propose a Modified Local-GD with a refined aggregation and theoretically show it converges to the centralized model in direction for linear classification. We empirically verified our theoretical findings in linear models and also conducted experiments on distributed fine-tuning of pretrained neural networks to further apply our theory.
Anvil: An integration of artificial intelligence, sampling techniques, and a combined CAD-CFD tool
Jun 24, 2024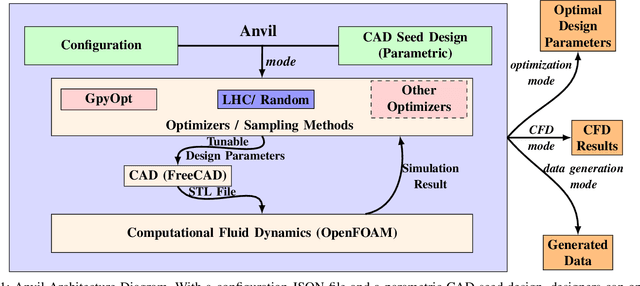
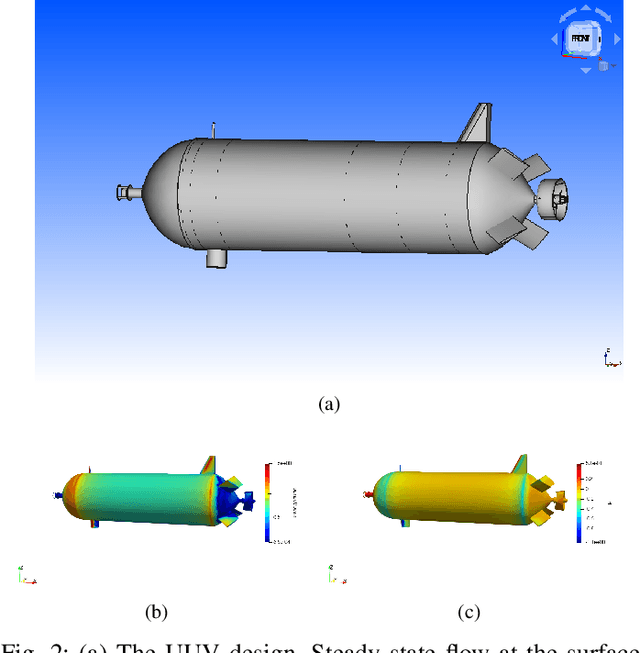
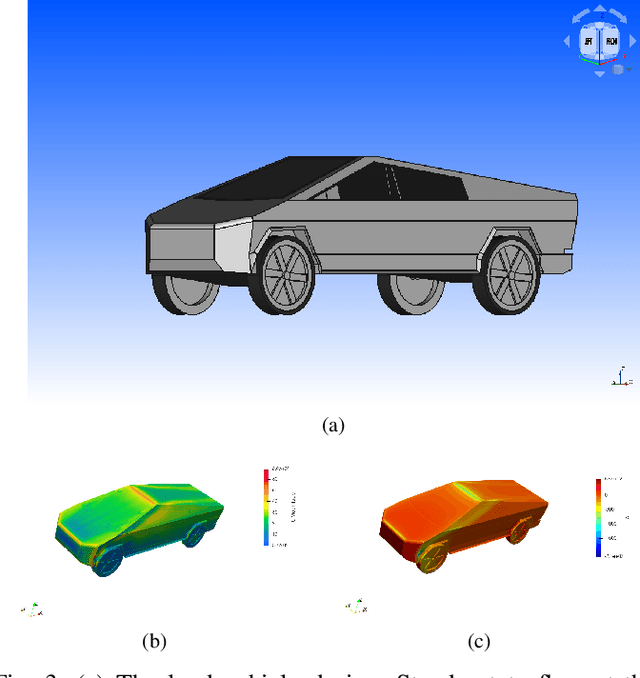
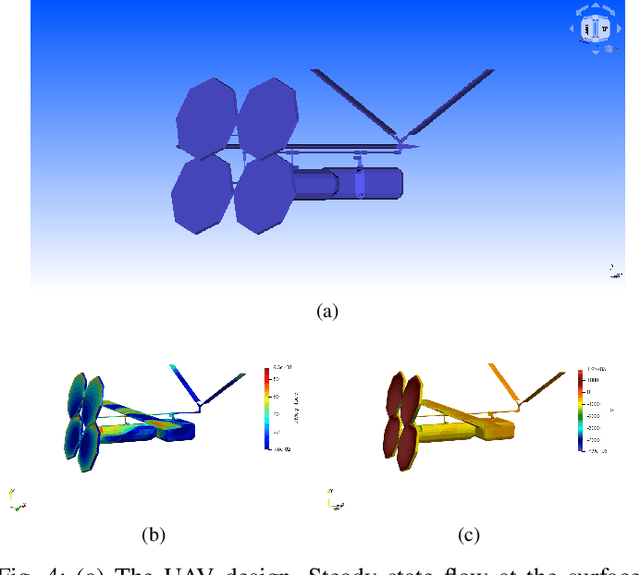
In this work, we introduce an open-source integrated CAD-CFD tool, Anvil, which combines FreeCAD for CAD modeling and OpenFOAM for CFD analysis, along with an AI-based optimization method (Bayesian optimization) and other sampling algorithms. Anvil serves as a scientific machine learning tool for shape optimization in three modes: data generation, CFD evaluation, and shape optimization. In data generation mode, it automatically runs CFD evaluations and generates data for training a surrogate model. In optimization mode, it searches for the optimal design under given requirements and optimization metrics. In CFD mode, a single CAD file can be evaluated with a single OpenFOAM run. To use Anvil, experimenters provide a JSON configuration file and a parametric CAD seed design. Anvil can be used to study solid-fluid dynamics for any subsonic flow conditions and has been demonstrated in various simulation and optimization use cases. The open-source code for the tool, installation process, artifacts (such as CAD seed designs and example STL models), experimentation results, and detailed documentation can be found at \url{https://github.com/symbench/Anvil}.
Sample-Efficient and Surrogate-Based Design Optimization of Underwater Vehicle Hulls
Apr 24, 2023Physics simulations are a computational bottleneck in computer-aided design (CAD) optimization processes. Hence, in order to make accurate (computationally expensive) simulations feasible for use in design optimization, one requires either an optimization framework that is highly sample-efficient or fast data-driven proxies (surrogate models) for long running simulations. In this work, we leverage recent advances in optimization and artificial intelligence (AI) to address both of these potential solutions, in the context of designing an optimal unmanned underwater vehicle (UUV). We first investigate and compare the sample efficiency and convergence behavior of different optimization techniques with a standard computational fluid dynamics (CFD) solver in the optimization loop. We then develop a deep neural network (DNN) based surrogate model to approximate drag forces that would otherwise be computed via direct numerical simulation with the CFD solver. The surrogate model is in turn used in the optimization loop of the hull design. Our study finds that the Bayesian Optimization Lower Condition Bound (BO LCB) algorithm is the most sample-efficient optimization framework and has the best convergence behavior of those considered. Subsequently, we show that our DNN-based surrogate model predicts drag force on test data in tight agreement with CFD simulations, with a mean absolute percentage error (MAPE) of 1.85%. Combining these results, we demonstrate a two-orders-of-magnitude speedup (with comparable accuracy) for the design optimization process when the surrogate model is used. To our knowledge, this is the first study applying Bayesian optimization and DNN-based surrogate modeling to the problem of UUV design optimization, and we share our developments as open-source software.
Constrained Bayesian Optimization for Automatic Underwater Vehicle Hull Design
Mar 15, 2023Automatic underwater vehicle hull Design optimization is a complex engineering process for generating a UUV hull with optimized properties on a given requirement. First, it involves the integration of involved computationally complex engineering simulation tools. Second, it needs integration of a sample efficient optimization framework with the integrated toolchain. To this end, we integrated the CAD tool called FreeCAD with CFD tool openFoam for automatic design evaluation. For optimization, we chose Bayesian optimization (BO), which is a well-known technique developed for optimizing time-consuming expensive engineering simulations and has proven to be very sample efficient in a variety of problems, including hyper-parameter tuning and experimental design. During the optimization process, we can handle infeasible design as constraints integrated into the optimization process. By integrating domain-specific toolchain with AI-based optimization, we executed the automatic design optimization of underwater vehicle hull design. For empirical evaluation, we took two different use cases of real-world underwater vehicle design to validate the execution of our tool.
Fusion of ML with numerical simulation for optimized propeller design
Feb 28, 2023In computer-aided engineering design, the goal of a designer is to find an optimal design on a given requirement using the numerical simulator in loop with an optimization method. In this design optimization process, a good design optimization process is one that can reduce the time from inception to design. In this work, we take a class of design problem, that is computationally cheap to evaluate but has high dimensional design space. In such cases, traditional surrogate-based optimization does not offer any benefits. In this work, we propose an alternative way to use ML model to surrogate the design process that formulates the search problem as an inverse problem and can save time by finding the optimal design or at least a good initial seed design for optimization. By using this trained surrogate model with the traditional optimization method, we can get the best of both worlds. We call this as Surrogate Assisted Optimization (SAO)- a hybrid approach by mixing ML surrogate with the traditional optimization method. Empirical evaluations of propeller design problems show that a better efficient design can be found in fewer evaluations using SAO.
Search for universal minimum drag resistance underwater vehicle hull using CFD
Feb 18, 2023In Autonomous Underwater Vehicles (AUVs) design, hull resistance is an important factor in determining the power requirements and range of vehicle and consequently affect battery size, weight, and volume requirement of the design. In this paper, we leverage on AI-based optimization algorithm along with Computational Fluid Dynamics (CFD) simulation to study the optimal hull design that minimizing the resistance. By running the CFD-based optimization at different operating velocities and turbulence intensity, we want to study/search the possibility of a universal design that will provide least resistance/near-optimal design across all operating conditions (operating velocity) and environmental conditions (turbulence intensity). Early result demonstrated that the optimal design found at low velocity and low turbulence condition performs very poor at high velocity and high turbulence conditions. However, a design that is optimal at high velocity and high turbulence conditions performs near-optimal across many considered velocity and turbulence conditions.