 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperLiDAR: Adaptive Post-Deployment LiDAR Segmentation via Hyperdimensional Computing
Apr 14, 2026LiDAR semantic segmentation plays a pivotal role in 3D scene understanding for edge applications such as autonomous driving. However, significant challenges remain for real-world deployments, particularly for on-device post-deployment adaptation. Real-world environments can shift as the system navigates through different locations, leading to substantial performance degradation without effective and timely model adaptation. Furthermore, edge systems operate under strict computational and energy constraints, making it infeasible to adapt conventional segmentation models (based on large neural networks) directly on-device. To address the above challenges, we introduce HyperLiDAR, the first lightweight, post-deployment LiDAR segmentation framework based on Hyperdimensional Computing (HDC). The design of HyperLiDAR fully leverages the fast learning and high efficiency of HDC, inspired by how the human brain processes information. To further improve the adaptation efficiency, we identify the high data volume per scan as a key bottleneck and introduce a buffer selection strategy that focuses learning on the most informative points. We conduct extensive evaluations on two state-of-the-art LiDAR segmentation benchmarks and two representative devices. Our results show that HyperLiDAR outperforms or achieves comparable adaptation performance to state-of-the-art segmentation methods, while achieving up to a 13.8x speedup in retraining.
KLDrive: Fine-Grained 3D Scene Reasoning for Autonomous Driving based on Knowledge Graph
Mar 22, 2026Autonomous driving requires reliable reasoning over fine-grained 3D scene facts. Fine-grained question answering over multi-modal driving observations provides a natural way to evaluate this capability, yet existing perception pipelines and driving-oriented large language model (LLM) methods still suffer from unreliable scene facts, hallucinations, opaque reasoning, and heavy reliance on task-specific training. We present KLDrive, the first knowledge-graph-augmented LLM reasoning framework for fine-grained question answering in autonomous driving. KLDrive addresses this problem through designing two tightly coupled components: an energy-based scene fact construction module that consolidates multi-source evidence into a reliable scene knowledge graph, and an LLM agent that performs fact-grounded reasoning over a constrained action space under explicit structural constraints. By combining structured prompting with few-shot in-context exemplars, the framework adapts to diverse reasoning tasks without heavy task-specific fine-tuning. Experiments on two large-scale autonomous-driving QA benchmarks show that KLDrive outperforms prior state-of-the-art methods, achieving the best overall accuracy of 65.04% on NuScenes-QA and the best SPICE score of 42.45 on GVQA. On counting, the most challenging factual reasoning task, it improves over the strongest baseline by 46.01 percentage points, demonstrating substantially reduced hallucinations and the benefit of coupling reliable scene fact construction with explicit reasoning.
Sim2Radar: Toward Bridging the Radar Sim-to-Real Gap with VLM-Guided Scene Reconstruction
Feb 10, 2026Millimeter-wave (mmWave) radar provides reliable perception in visually degraded indoor environments (e.g., smoke, dust, and low light), but learning-based radar perception is bottlenecked by the scarcity and cost of collecting and annotating large-scale radar datasets. We present Sim2Radar, an end-to-end framework that synthesizes training radar data directly from single-view RGB images, enabling scalable data generation without manual scene modeling. Sim2Radar reconstructs a material-aware 3D scene by combining monocular depth estimation, segmentation, and vision-language reasoning to infer object materials, then simulates mmWave propagation with a configurable physics-based ray tracer using Fresnel reflection models parameterized by ITU-R electromagnetic properties. Evaluated on real-world indoor scenes, Sim2Radar improves downstream 3D radar perception via transfer learning: pre-training a radar point-cloud object detection model on synthetic data and fine-tuning on real radar yields up to +3.7 3D AP (IoU 0.3), with gains driven primarily by improved spatial localization. These results suggest that physics-based, vision-driven radar simulation can provide effective geometric priors for radar learning and measurably improve performance under limited real-data supervision.
Client Selection in Federated Learning with Data Heterogeneity and Network Latencies
Apr 02, 2025


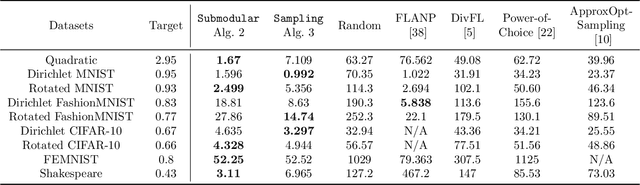
Federated learning (FL) is a distributed machine learning paradigm where multiple clients conduct local training based on their private data, then the updated models are sent to a central server for global aggregation. The practical convergence of FL is challenged by multiple factors, with the primary hurdle being the heterogeneity among clients. This heterogeneity manifests as data heterogeneity concerning local data distribution and latency heterogeneity during model transmission to the server. While prior research has introduced various efficient client selection methods to alleviate the negative impacts of either of these heterogeneities individually, efficient methods to handle real-world settings where both these heterogeneities exist simultaneously do not exist. In this paper, we propose two novel theoretically optimal client selection schemes that can handle both these heterogeneities. Our methods involve solving simple optimization problems every round obtained by minimizing the theoretical runtime to convergence. Empirical evaluations on 9 datasets with non-iid data distributions, 2 practical delay distributions, and non-convex neural network models demonstrate that our algorithms are at least competitive to and at most 20 times better than best existing baselines.
Orthogonal Calibration for Asynchronous Federated Learning
Feb 21, 2025Asynchronous federated learning mitigates the inefficiency of conventional synchronous aggregation by integrating updates as they arrive and adjusting their influence based on staleness. Due to asynchrony and data heterogeneity, learning objectives at the global and local levels are inherently inconsistent -- global optimization trajectories may conflict with ongoing local updates. Existing asynchronous methods simply distribute the latest global weights to clients, which can overwrite local progress and cause model drift. In this paper, we propose OrthoFL, an orthogonal calibration framework that decouples global and local learning progress and adjusts global shifts to minimize interference before merging them into local models. In OrthoFL, clients and the server maintain separate model weights. Upon receiving an update, the server aggregates it into the global weights via a moving average. For client weights, the server computes the global weight shift accumulated during the client's delay and removes the components aligned with the direction of the received update. The resulting parameters lie in a subspace orthogonal to the client update and preserve the maximal information from the global progress. The calibrated global shift is then merged into the client weights for further training. Extensive experiments show that OrthoFL improves accuracy by 9.6% and achieves a 12$\times$ speedup compared to synchronous methods. Moreover, it consistently outperforms state-of-the-art asynchronous baselines under various delay patterns and heterogeneity scenarios.
SensorChat: Answering Qualitative and Quantitative Questions during Long-Term Multimodal Sensor Interactions
Feb 05, 2025Natural language interaction with sensing systems is crucial for enabling all users to comprehend sensor data and its impact on their everyday lives. However, existing systems, which typically operate in a Question Answering (QA) manner, are significantly limited in terms of the duration and complexity of sensor data they can handle. In this work, we introduce SensorChat, the first end-to-end QA system designed for long-term sensor monitoring with multimodal and high-dimensional data including time series. SensorChat effectively answers both qualitative (requiring high-level reasoning) and quantitative (requiring accurate responses derived from sensor data) questions in real-world scenarios. To achieve this, SensorChat uses an innovative three-stage pipeline that includes question decomposition, sensor data query, and answer assembly. The first and third stages leverage Large Language Models (LLMs) for intuitive human interactions and to guide the sensor data query process. Unlike existing multimodal LLMs, SensorChat incorporates an explicit query stage to precisely extract factual information from long-duration sensor data. We implement SensorChat and demonstrate its capability for real-time interactions on a cloud server while also being able to run entirely on edge platforms after quantization. Comprehensive QA evaluations show that SensorChat achieves up to 26% higher answer accuracy than state-of-the-art systems on quantitative questions. Additionally, a user study with eight volunteers highlights SensorChat's effectiveness in handling qualitative and open-ended questions.
SensorQA: A Question Answering Benchmark for Daily-Life Monitoring
Jan 10, 2025



With the rapid growth in sensor data, effectively interpreting and interfacing with these data in a human-understandable way has become crucial. While existing research primarily focuses on learning classification models, fewer studies have explored how end users can actively extract useful insights from sensor data, often hindered by the lack of a proper dataset. To address this gap, we introduce SensorQA, the first human-created question-answering (QA) dataset for long-term time-series sensor data for daily life monitoring. SensorQA is created by human workers and includes 5.6K diverse and practical queries that reflect genuine human interests, paired with accurate answers derived from sensor data. We further establish benchmarks for state-of-the-art AI models on this dataset and evaluate their performance on typical edge devices. Our results reveal a gap between current models and optimal QA performance and efficiency, highlighting the need for new contributions. The dataset and code are available at: \url{https://github.com/benjamin-reichman/SensorQA}.
Lifelong Intelligence Beyond the Edge using Hyperdimensional Computing
Mar 07, 2024
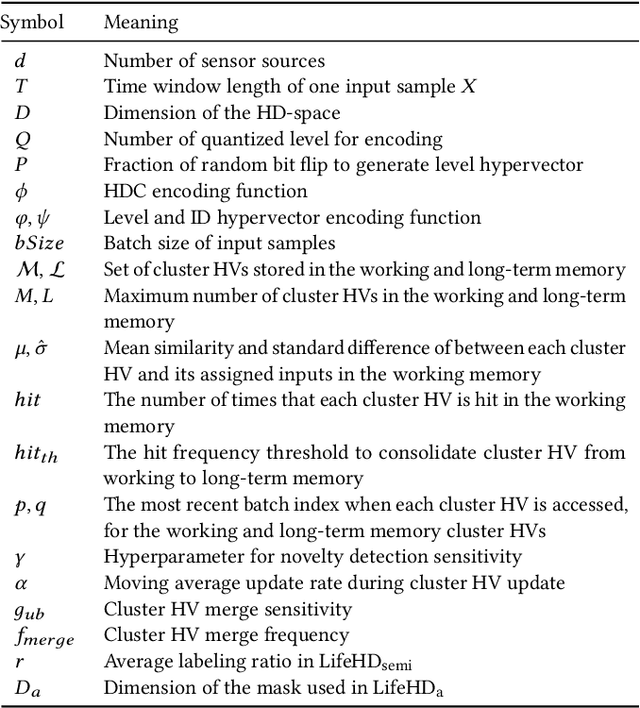

On-device learning has emerged as a prevailing trend that avoids the slow response time and costly communication of cloud-based learning. The ability to learn continuously and indefinitely in a changing environment, and with resource constraints, is critical for real sensor deployments. However, existing designs are inadequate for practical scenarios with (i) streaming data input, (ii) lack of supervision and (iii) limited on-board resources. In this paper, we design and deploy the first on-device lifelong learning system called LifeHD for general IoT applications with limited supervision. LifeHD is designed based on a novel neurally-inspired and lightweight learning paradigm called Hyperdimensional Computing (HDC). We utilize a two-tier associative memory organization to intelligently store and manage high-dimensional, low-precision vectors, which represent the historical patterns as cluster centroids. We additionally propose two variants of LifeHD to cope with scarce labeled inputs and power constraints. We implement LifeHD on off-the-shelf edge platforms and perform extensive evaluations across three scenarios. Our measurements show that LifeHD improves the unsupervised clustering accuracy by up to 74.8% compared to the state-of-the-art NN-based unsupervised lifelong learning baselines with as much as 34.3x better energy efficiency. Our code is available at https://github.com/Orienfish/LifeHD.
Async-HFL: Efficient and Robust Asynchronous Federated Learning in Hierarchical IoT Networks
Jan 17, 2023



Federated Learning (FL) has gained increasing interest in recent years as a distributed on-device learning paradigm. However, multiple challenges remain to be addressed for deploying FL in real-world Internet-of-Things (IoT) networks with hierarchies. Although existing works have proposed various approaches to account data heterogeneity, system heterogeneity, unexpected stragglers and scalibility, none of them provides a systematic solution to address all of the challenges in a hierarchical and unreliable IoT network. In this paper, we propose an asynchronous and hierarchical framework (Async-HFL) for performing FL in a common three-tier IoT network architecture. In response to the largely varied delays, Async-HFL employs asynchronous aggregations at both the gateway and the cloud levels thus avoids long waiting time. To fully unleash the potential of Async-HFL in converging speed under system heterogeneities and stragglers, we design device selection at the gateway level and device-gateway association at the cloud level. Device selection chooses edge devices to trigger local training in real-time while device-gateway association determines the network topology periodically after several cloud epochs, both satisfying bandwidth limitation. We evaluate Async-HFL's convergence speedup using large-scale simulations based on ns-3 and a network topology from NYCMesh. Our results show that Async-HFL converges 1.08-1.31x faster in wall-clock time and saves up to 21.6% total communication cost compared to state-of-the-art asynchronous FL algorithms (with client selection). We further validate Async-HFL on a physical deployment and observe robust convergence under unexpected stragglers.
SCALE: Online Self-Supervised Lifelong Learning without Prior Knowledge
Aug 24, 2022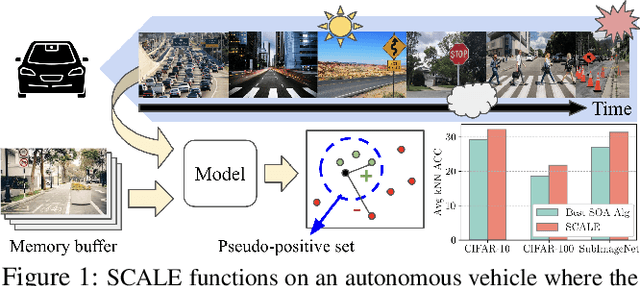
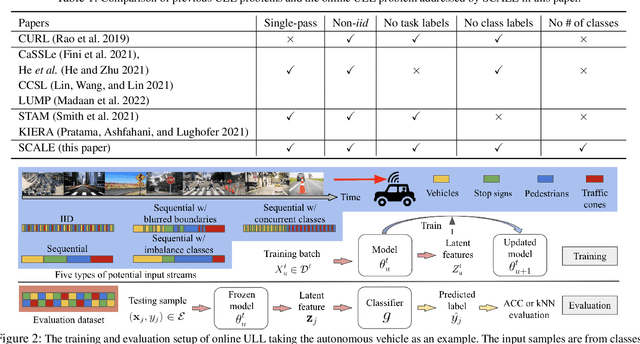
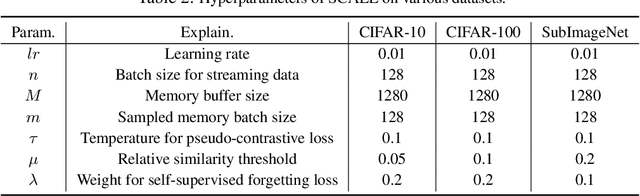
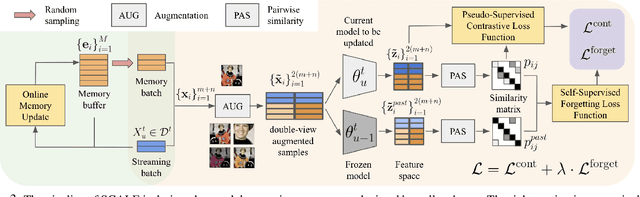
Unsupervised lifelong learning refers to the ability to learn over time while memorizing previous patterns without supervision. Previous works assumed strong prior knowledge about the incoming data (e.g., knowing the class boundaries) which can be impossible to obtain in complex and unpredictable environments. In this paper, motivated by real-world scenarios, we formally define the online unsupervised lifelong learning problem with class-incremental streaming data, which is non-iid and single-pass. The problem is more challenging than existing lifelong learning problems due to the absence of labels and prior knowledge. To address the issue, we propose Self-Supervised ContrAstive Lifelong LEarning (SCALE) which extracts and memorizes knowledge on-the-fly. SCALE is designed around three major components: a pseudo-supervised contrastive loss, a self-supervised forgetting loss, and an online memory update for uniform subset selection. All three components are designed to work collaboratively to maximize learning performance. Our loss functions leverage pairwise similarity thus remove the dependency on supervision or prior knowledge. We perform comprehensive experiments of SCALE under iid and four non-iid data streams. SCALE outperforms the best state-of-the-art algorithm on all settings with improvements of up to 6.43%, 5.23% and 5.86% kNN accuracy on CIFAR-10, CIFAR-100 and SubImageNet datasets.