 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutside Knowledge Conversational Video (OKCV) Dataset -- Dialoguing over Videos
Jun 11, 2025



In outside knowledge visual question answering (OK-VQA), the model must identify relevant visual information within an image and incorporate external knowledge to accurately respond to a question. Extending this task to a visually grounded dialogue setting based on videos, a conversational model must both recognize pertinent visual details over time and answer questions where the required information is not necessarily present in the visual information. Moreover, the context of the overall conversation must be considered for the subsequent dialogue. To explore this task, we introduce a dataset comprised of $2,017$ videos with $5,986$ human-annotated dialogues consisting of $40,954$ interleaved dialogue turns. While the dialogue context is visually grounded in specific video segments, the questions further require external knowledge that is not visually present. Thus, the model not only has to identify relevant video parts but also leverage external knowledge to converse within the dialogue. We further provide several baselines evaluated on our dataset and show future challenges associated with this task. The dataset is made publicly available here: https://github.com/c-patsch/OKCV.
SensorQA: A Question Answering Benchmark for Daily-Life Monitoring
Jan 10, 2025



With the rapid growth in sensor data, effectively interpreting and interfacing with these data in a human-understandable way has become crucial. While existing research primarily focuses on learning classification models, fewer studies have explored how end users can actively extract useful insights from sensor data, often hindered by the lack of a proper dataset. To address this gap, we introduce SensorQA, the first human-created question-answering (QA) dataset for long-term time-series sensor data for daily life monitoring. SensorQA is created by human workers and includes 5.6K diverse and practical queries that reflect genuine human interests, paired with accurate answers derived from sensor data. We further establish benchmarks for state-of-the-art AI models on this dataset and evaluate their performance on typical edge devices. Our results reveal a gap between current models and optimal QA performance and efficiency, highlighting the need for new contributions. The dataset and code are available at: \url{https://github.com/benjamin-reichman/SensorQA}.
ScribeAgent: Towards Specialized Web Agents Using Production-Scale Workflow Data
Nov 22, 2024



Large Language Model (LLM) agents are rapidly improving to handle increasingly complex web-based tasks. Most of these agents rely on general-purpose, proprietary models like GPT-4 and focus on designing better prompts to improve their planning abilities. However, general-purpose LLMs are not specifically trained to understand specialized web contexts such as HTML, and they often struggle with long-horizon planning. We explore an alternative approach that fine-tunes open-source LLMs using production-scale workflow data collected from over 250 domains corresponding to 6 billion tokens. This simple yet effective approach shows substantial gains over prompting-based agents on existing benchmarks -- ScribeAgent achieves state-of-the-art direct generation performance on Mind2Web and improves the task success rate by 14.1% over the previous best text-only web agents on WebArena. We further perform detailed ablation studies on various fine-tuning design choices and provide insights into LLM selection, training recipes, context window optimization, and effect of dataset sizes.
Language Models Get a Gender Makeover: Mitigating Gender Bias with Few-Shot Data Interventions
Jun 07, 2023



Societal biases present in pre-trained large language models are a critical issue as these models have been shown to propagate biases in countless downstream applications, rendering them unfair towards specific groups of people. Since large-scale retraining of these models from scratch is both time and compute-expensive, a variety of approaches have been previously proposed that de-bias a pre-trained model. While the majority of current state-of-the-art debiasing methods focus on changes to the training regime, in this paper, we propose data intervention strategies as a powerful yet simple technique to reduce gender bias in pre-trained models. Specifically, we empirically show that by fine-tuning a pre-trained model on only 10 de-biased (intervened) training examples, the tendency to favor any gender is significantly reduced. Since our proposed method only needs a few training examples, our few-shot debiasing approach is highly feasible and practical. Through extensive experimentation, we show that our debiasing technique performs better than competitive state-of-the-art baselines with minimal loss in language modeling ability.
Fake News Early Detection: A Theory-driven Model
Apr 26, 2019
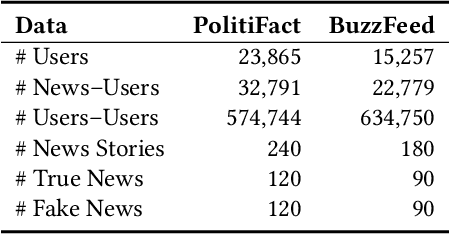

The explosive growth of fake news and its erosion of democracy, justice, and public trust has significantly increased the demand for accurate fake news detection. Recent advancements in this area have proposed novel techniques that aim to detect fake news by exploring how it propagates on social networks. However, to achieve fake news early detection, one is only provided with limited to no information on news propagation; hence, motivating the need to develop approaches that can detect fake news by focusing mainly on news content. In this paper, a theory-driven model is proposed for fake news detection. The method investigates news content at various levels: lexicon-level, syntax-level, semantic-level and discourse-level. We represent news at each level, relying on well-established theories in social and forensic psychology. Fake news detection is then conducted within a supervised machine learning framework. As an interdisciplinary research, our work explores potential fake news patterns, enhances the interpretability in fake news feature engineering, and studies the relationships among fake news, deception/disinformation, and clickbaits. Experiments conducted on two real-world datasets indicate that the proposed method can outperform the state-of-the-art and enable fake news early detection, even when there is limited content information.
AI in Game Playing: Sokoban Solver
Jun 29, 2018



Artificial Intelligence is becoming instrumental in a variety of applications. Games serve as a good breeding ground for trying and testing these algorithms in a sandbox with simpler constraints in comparison to real life. In this project, we aim to develop an AI agent that can solve the classical Japanese game of Sokoban using various algorithms and heuristics and compare their performances through standard metrics.
Automatic 3D Reconstruction for Symmetric Shapes
Jun 18, 2016


Generic 3D reconstruction from a single image is a difficult problem. A lot of data loss occurs in the projection. A domain based approach to reconstruction where we solve a smaller set of problems for a particular use case lead to greater returns. The project provides a way to automatically generate full 3-D renditions of actual symmetric images that have some prior information provided in the pipeline by a recognition algorithm. We provide a critical analysis on how this can be enhanced and improved to provide a general reconstruction framework for automatic reconstruction for any symmetric shape.