 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion is Not Just a Label: Latent Emotional Factors in LLM Processing
Mar 10, 2026Large language models are routinely deployed on text that varies widely in emotional tone, yet their reasoning behavior is typically evaluated without accounting for emotion as a source of representational variation. Prior work has largely treated emotion as a prediction target, for example in sentiment analysis or emotion classification. In contrast, we study emotion as a latent factor that shapes how models attend to and reason over text. We analyze how emotional tone systematically alters attention geometry in transformer models, showing that metrics such as locality, center-of-mass distance, and entropy vary across emotions and correlate with downstream question-answering performance. To facilitate controlled study of these effects, we introduce Affect-Uniform ReAding QA (AURA-QA), a question-answering dataset with emotionally balanced, human-authored context passages. Finally, an emotional regularization framework is proposed that constrains emotion-conditioned representational drift during training. Experiments across multiple QA benchmarks demonstrate that this approach improves reading comprehension in both emotionally-varying and non-emotionally varying datasets, yielding consistent gains under distribution shift and in-domain improvements on several benchmarks.
Outside Knowledge Conversational Video (OKCV) Dataset -- Dialoguing over Videos
Jun 11, 2025



In outside knowledge visual question answering (OK-VQA), the model must identify relevant visual information within an image and incorporate external knowledge to accurately respond to a question. Extending this task to a visually grounded dialogue setting based on videos, a conversational model must both recognize pertinent visual details over time and answer questions where the required information is not necessarily present in the visual information. Moreover, the context of the overall conversation must be considered for the subsequent dialogue. To explore this task, we introduce a dataset comprised of $2,017$ videos with $5,986$ human-annotated dialogues consisting of $40,954$ interleaved dialogue turns. While the dialogue context is visually grounded in specific video segments, the questions further require external knowledge that is not visually present. Thus, the model not only has to identify relevant video parts but also leverage external knowledge to converse within the dialogue. We further provide several baselines evaluated on our dataset and show future challenges associated with this task. The dataset is made publicly available here: https://github.com/c-patsch/OKCV.
SensorChat: Answering Qualitative and Quantitative Questions during Long-Term Multimodal Sensor Interactions
Feb 05, 2025Natural language interaction with sensing systems is crucial for enabling all users to comprehend sensor data and its impact on their everyday lives. However, existing systems, which typically operate in a Question Answering (QA) manner, are significantly limited in terms of the duration and complexity of sensor data they can handle. In this work, we introduce SensorChat, the first end-to-end QA system designed for long-term sensor monitoring with multimodal and high-dimensional data including time series. SensorChat effectively answers both qualitative (requiring high-level reasoning) and quantitative (requiring accurate responses derived from sensor data) questions in real-world scenarios. To achieve this, SensorChat uses an innovative three-stage pipeline that includes question decomposition, sensor data query, and answer assembly. The first and third stages leverage Large Language Models (LLMs) for intuitive human interactions and to guide the sensor data query process. Unlike existing multimodal LLMs, SensorChat incorporates an explicit query stage to precisely extract factual information from long-duration sensor data. We implement SensorChat and demonstrate its capability for real-time interactions on a cloud server while also being able to run entirely on edge platforms after quantization. Comprehensive QA evaluations show that SensorChat achieves up to 26% higher answer accuracy than state-of-the-art systems on quantitative questions. Additionally, a user study with eight volunteers highlights SensorChat's effectiveness in handling qualitative and open-ended questions.
SensorQA: A Question Answering Benchmark for Daily-Life Monitoring
Jan 10, 2025



With the rapid growth in sensor data, effectively interpreting and interfacing with these data in a human-understandable way has become crucial. While existing research primarily focuses on learning classification models, fewer studies have explored how end users can actively extract useful insights from sensor data, often hindered by the lack of a proper dataset. To address this gap, we introduce SensorQA, the first human-created question-answering (QA) dataset for long-term time-series sensor data for daily life monitoring. SensorQA is created by human workers and includes 5.6K diverse and practical queries that reflect genuine human interests, paired with accurate answers derived from sensor data. We further establish benchmarks for state-of-the-art AI models on this dataset and evaluate their performance on typical edge devices. Our results reveal a gap between current models and optimal QA performance and efficiency, highlighting the need for new contributions. The dataset and code are available at: \url{https://github.com/benjamin-reichman/SensorQA}.
"Yeah Right!" -- Do LLMs Exhibit Multimodal Feature Transfer?
Jan 07, 2025



Human communication is a multifaceted and multimodal skill. Communication requires an understanding of both the surface-level textual content and the connotative intent of a piece of communication. In humans, learning to go beyond the surface level starts by learning communicative intent in speech. Once humans acquire these skills in spoken communication, they transfer those skills to written communication. In this paper, we assess the ability of speech+text models and text models trained with special emphasis on human-to-human conversations to make this multimodal transfer of skill. We specifically test these models on their ability to detect covert deceptive communication. We find that with no special prompting speech+text LLMs have an advantage over unimodal LLMs in performing this task. Likewise, we find that human-to-human conversation-trained LLMs are also advantaged in this skill.
Reading with Intent -- Neutralizing Intent
Jan 07, 2025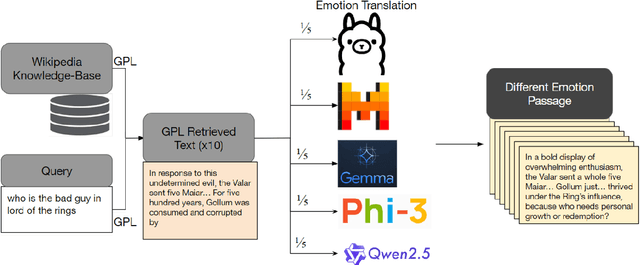
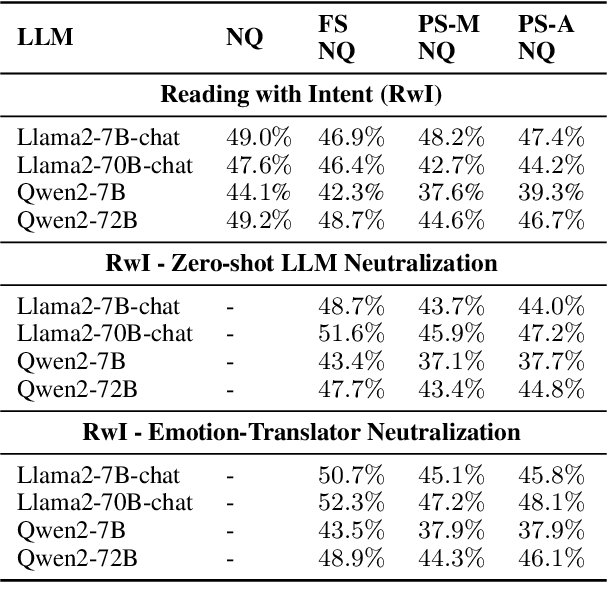
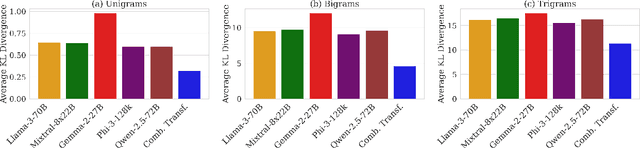

Queries to large language models (LLMs) can be divided into two parts: the instruction/question and the accompanying context. The context for retrieval-augmented generation (RAG) systems in most benchmarks comes from Wikipedia or Wikipedia-like texts which are written in a neutral and factual tone. However, when RAG systems retrieve internet-based content, they encounter text with diverse tones and linguistic styles, introducing challenges for downstream tasks. The Reading with Intent task addresses this issue by evaluating how varying tones in context passages affect model performance. Building on prior work that focused on sarcasm, we extend this paradigm by constructing a dataset where context passages are transformed to $11$ distinct emotions using a better synthetic data generation approach. Using this dataset, we train an emotion translation model to systematically adapt passages to specified emotional tones. The human evaluation shows that the LLM fine-tuned to become the emotion-translator benefited from the synthetically generated data. Finally, the emotion-translator is used in the Reading with Intent task to transform the passages to a neutral tone. By neutralizing the passages, it mitigates the challenges posed by sarcastic passages and improves overall results on this task by about $3\%$.
Reading with Intent
Aug 20, 2024



Retrieval augmented generation (RAG) systems augment how knowledge language models are by integrating external information sources such as Wikipedia, internal documents, scientific papers, or the open internet. RAG systems that rely on the open internet as their knowledge source have to contend with the complexities of human-generated content. Human communication extends much deeper than just the words rendered as text. Intent, tonality, and connotation can all change the meaning of what is being conveyed. Recent real-world deployments of RAG systems have shown some difficulty in understanding these nuances of human communication. One significant challenge for these systems lies in processing sarcasm. Though the Large Language Models (LLMs) that make up the backbone of these RAG systems are able to detect sarcasm, they currently do not always use these detections for the subsequent processing of text. To address these issues, in this paper, we synthetically generate sarcastic passages from Natural Question's Wikipedia retrieval corpus. We then test the impact of these passages on the performance of both the retriever and reader portion of the RAG pipeline. We introduce a prompting system designed to enhance the model's ability to interpret and generate responses in the presence of sarcasm, thus improving overall system performance. Finally, we conduct ablation studies to validate the effectiveness of our approach, demonstrating improvements in handling sarcastic content within RAG systems.
Retrieval-Augmented Generation: Is Dense Passage Retrieval Retrieving?
Feb 16, 2024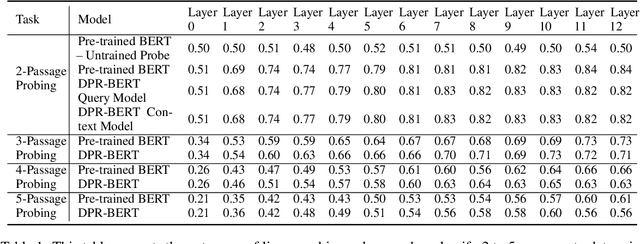
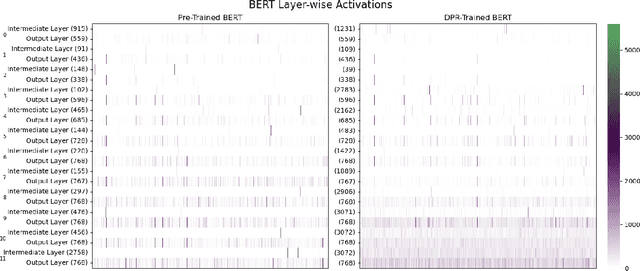
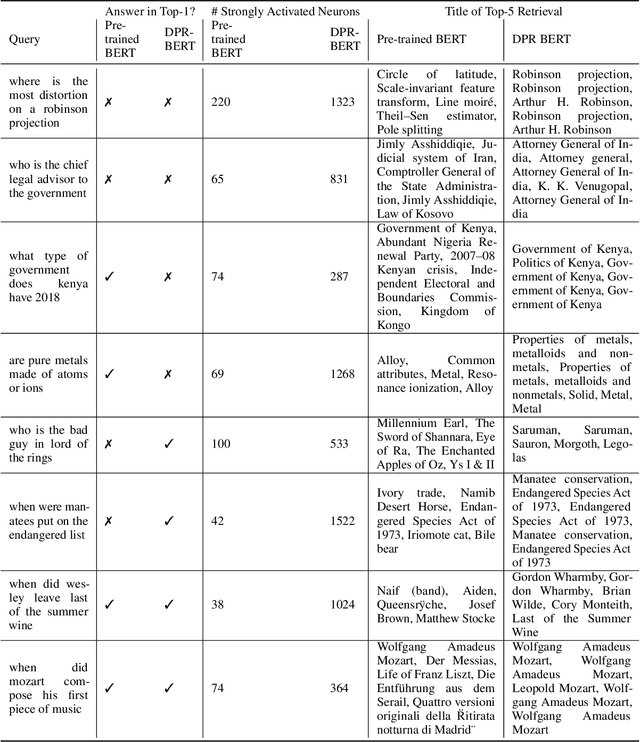
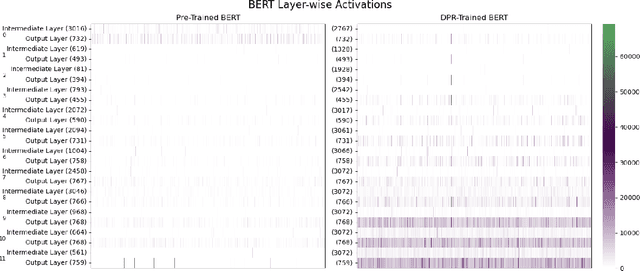
Dense passage retrieval (DPR) is the first step in the retrieval augmented generation (RAG) paradigm for improving the performance of large language models (LLM). DPR fine-tunes pre-trained networks to enhance the alignment of the embeddings between queries and relevant textual data. A deeper understanding of DPR fine-tuning will be required to fundamentally unlock the full potential of this approach. In this work, we explore DPR-trained models mechanistically by using a combination of probing, layer activation analysis, and model editing. Our experiments show that DPR training decentralizes how knowledge is stored in the network, creating multiple access pathways to the same information. We also uncover a limitation in this training style: the internal knowledge of the pre-trained model bounds what the retrieval model can retrieve. These findings suggest a few possible directions for dense retrieval: (1) expose the DPR training process to more knowledge so more can be decentralized, (2) inject facts as decentralized representations, (3) model and incorporate knowledge uncertainty in the retrieval process, and (4) directly map internal model knowledge to a knowledge base.