 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion is Not Just a Label: Latent Emotional Factors in LLM Processing
Mar 10, 2026Large language models are routinely deployed on text that varies widely in emotional tone, yet their reasoning behavior is typically evaluated without accounting for emotion as a source of representational variation. Prior work has largely treated emotion as a prediction target, for example in sentiment analysis or emotion classification. In contrast, we study emotion as a latent factor that shapes how models attend to and reason over text. We analyze how emotional tone systematically alters attention geometry in transformer models, showing that metrics such as locality, center-of-mass distance, and entropy vary across emotions and correlate with downstream question-answering performance. To facilitate controlled study of these effects, we introduce Affect-Uniform ReAding QA (AURA-QA), a question-answering dataset with emotionally balanced, human-authored context passages. Finally, an emotional regularization framework is proposed that constrains emotion-conditioned representational drift during training. Experiments across multiple QA benchmarks demonstrate that this approach improves reading comprehension in both emotionally-varying and non-emotionally varying datasets, yielding consistent gains under distribution shift and in-domain improvements on several benchmarks.
Unlearning in LLMs: Methods, Evaluation, and Open Challenges
Jan 19, 2026Large language models (LLMs) have achieved remarkable success across natural language processing tasks, yet their widespread deployment raises pressing concerns around privacy, copyright, security, and bias. Machine unlearning has emerged as a promising paradigm for selectively removing knowledge or data from trained models without full retraining. In this survey, we provide a structured overview of unlearning methods for LLMs, categorizing existing approaches into data-centric, parameter-centric, architecture-centric, hybrid, and other strategies. We also review the evaluation ecosystem, including benchmarks, metrics, and datasets designed to measure forgetting effectiveness, knowledge retention, and robustness. Finally, we outline key challenges and open problems, such as scalable efficiency, formal guarantees, cross-language and multimodal unlearning, and robustness against adversarial relearning. By synthesizing current progress and highlighting open directions, this paper aims to serve as a roadmap for developing reliable and responsible unlearning techniques in large language models.
Evaluating Cross-Lingual Unlearning in Multilingual Language Models
Jan 10, 2026We present the first comprehensive evaluation of cross-lingual unlearning in multilingual LLMs. Using translated TOFU benchmarks in seven language/script variants, we test major unlearning algorithms and show that most fail to remove facts outside the training language, even when utility remains high. However, subspace-projection consistently outperforms the other methods, achieving strong cross-lingual forgetting with minimal degradation. Analysis of learned task subspaces reveals a shared interlingua structure: removing this shared subspace harms all languages, while removing language-specific components selectively affects one. These results demonstrate that multilingual forgetting depends on geometry in weight space, motivating subspace-based approaches for future unlearning systems.
FLEx: Language Modeling with Few-shot Language Explanations
Jan 07, 2026Language models have become effective at a wide range of tasks, from math problem solving to open-domain question answering. However, they still make mistakes, and these mistakes are often repeated across related queries. Natural language explanations can help correct these errors, but collecting them at scale may be infeasible, particularly in domains where expert annotators are required. To address this issue, we introduce FLEx ($\textbf{F}$ew-shot $\textbf{L}$anguage $\textbf{Ex}$planations), a method for improving model behavior using a small number of explanatory examples. FLEx selects representative model errors using embedding-based clustering, verifies that the associated explanations correct those errors, and summarizes them into a prompt prefix that is prepended at inference-time. This summary guides the model to avoid similar errors on new inputs, without modifying model weights. We evaluate FLEx on CounterBench, GSM8K, and ReasonIF. We find that FLEx consistently outperforms chain-of-thought (CoT) prompting across all three datasets and reduces up to 83\% of CoT's remaining errors.
Outside Knowledge Conversational Video (OKCV) Dataset -- Dialoguing over Videos
Jun 11, 2025



In outside knowledge visual question answering (OK-VQA), the model must identify relevant visual information within an image and incorporate external knowledge to accurately respond to a question. Extending this task to a visually grounded dialogue setting based on videos, a conversational model must both recognize pertinent visual details over time and answer questions where the required information is not necessarily present in the visual information. Moreover, the context of the overall conversation must be considered for the subsequent dialogue. To explore this task, we introduce a dataset comprised of $2,017$ videos with $5,986$ human-annotated dialogues consisting of $40,954$ interleaved dialogue turns. While the dialogue context is visually grounded in specific video segments, the questions further require external knowledge that is not visually present. Thus, the model not only has to identify relevant video parts but also leverage external knowledge to converse within the dialogue. We further provide several baselines evaluated on our dataset and show future challenges associated with this task. The dataset is made publicly available here: https://github.com/c-patsch/OKCV.
Weight-of-Thought Reasoning: Exploring Neural Network Weights for Enhanced LLM Reasoning
Apr 14, 2025



Large language models (LLMs) have demonstrated remarkable reasoning capabilities when prompted with strategies such as Chain-of-Thought (CoT). However, these approaches focus on token-level output without considering internal weight dynamics. We introduce Weight-of-Thought (WoT) reasoning, a novel approach that examines neural network weights before inference to identify reasoning pathways. Unlike existing methods, WoT explores the weight space through graph-based message passing, multi-step reasoning processes, and attention mechanisms. Our implementation creates an interconnected graph of reasoning nodes. Experiments on diverse reasoning tasks (syllogistic, mathematical, algebraic, combinatorial, and geometric) demonstrate that WoT achieves superior performance compared to traditional methods, particularly for complex problems. This approach leads to both improved performance and greater interpretability of the reasoning process, offering a promising direction for enhancing LLM reasoning capabilities.
SensorChat: Answering Qualitative and Quantitative Questions during Long-Term Multimodal Sensor Interactions
Feb 05, 2025Natural language interaction with sensing systems is crucial for enabling all users to comprehend sensor data and its impact on their everyday lives. However, existing systems, which typically operate in a Question Answering (QA) manner, are significantly limited in terms of the duration and complexity of sensor data they can handle. In this work, we introduce SensorChat, the first end-to-end QA system designed for long-term sensor monitoring with multimodal and high-dimensional data including time series. SensorChat effectively answers both qualitative (requiring high-level reasoning) and quantitative (requiring accurate responses derived from sensor data) questions in real-world scenarios. To achieve this, SensorChat uses an innovative three-stage pipeline that includes question decomposition, sensor data query, and answer assembly. The first and third stages leverage Large Language Models (LLMs) for intuitive human interactions and to guide the sensor data query process. Unlike existing multimodal LLMs, SensorChat incorporates an explicit query stage to precisely extract factual information from long-duration sensor data. We implement SensorChat and demonstrate its capability for real-time interactions on a cloud server while also being able to run entirely on edge platforms after quantization. Comprehensive QA evaluations show that SensorChat achieves up to 26% higher answer accuracy than state-of-the-art systems on quantitative questions. Additionally, a user study with eight volunteers highlights SensorChat's effectiveness in handling qualitative and open-ended questions.
SensorQA: A Question Answering Benchmark for Daily-Life Monitoring
Jan 10, 2025



With the rapid growth in sensor data, effectively interpreting and interfacing with these data in a human-understandable way has become crucial. While existing research primarily focuses on learning classification models, fewer studies have explored how end users can actively extract useful insights from sensor data, often hindered by the lack of a proper dataset. To address this gap, we introduce SensorQA, the first human-created question-answering (QA) dataset for long-term time-series sensor data for daily life monitoring. SensorQA is created by human workers and includes 5.6K diverse and practical queries that reflect genuine human interests, paired with accurate answers derived from sensor data. We further establish benchmarks for state-of-the-art AI models on this dataset and evaluate their performance on typical edge devices. Our results reveal a gap between current models and optimal QA performance and efficiency, highlighting the need for new contributions. The dataset and code are available at: \url{https://github.com/benjamin-reichman/SensorQA}.
Reading with Intent -- Neutralizing Intent
Jan 07, 2025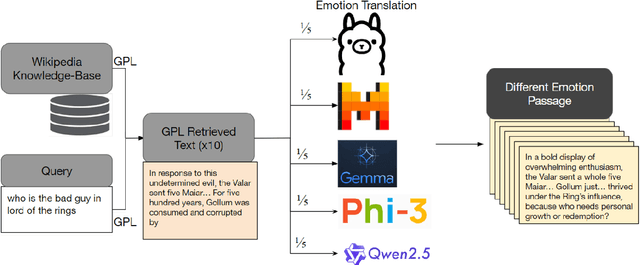
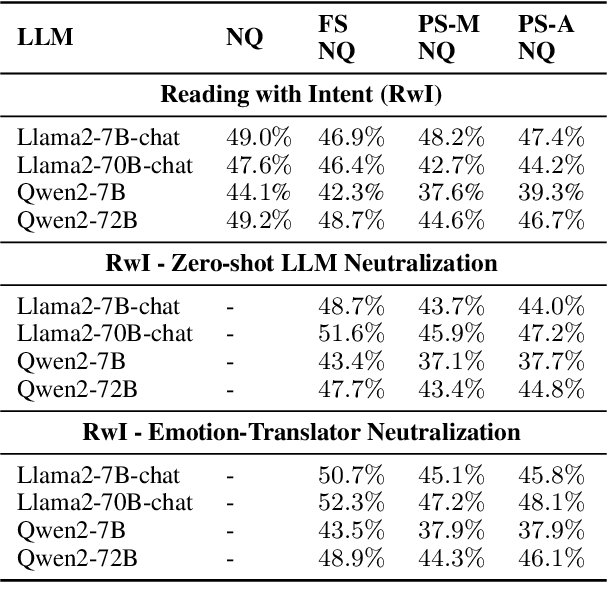
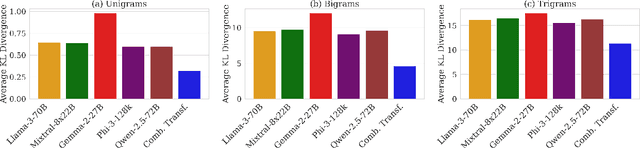

Queries to large language models (LLMs) can be divided into two parts: the instruction/question and the accompanying context. The context for retrieval-augmented generation (RAG) systems in most benchmarks comes from Wikipedia or Wikipedia-like texts which are written in a neutral and factual tone. However, when RAG systems retrieve internet-based content, they encounter text with diverse tones and linguistic styles, introducing challenges for downstream tasks. The Reading with Intent task addresses this issue by evaluating how varying tones in context passages affect model performance. Building on prior work that focused on sarcasm, we extend this paradigm by constructing a dataset where context passages are transformed to $11$ distinct emotions using a better synthetic data generation approach. Using this dataset, we train an emotion translation model to systematically adapt passages to specified emotional tones. The human evaluation shows that the LLM fine-tuned to become the emotion-translator benefited from the synthetically generated data. Finally, the emotion-translator is used in the Reading with Intent task to transform the passages to a neutral tone. By neutralizing the passages, it mitigates the challenges posed by sarcastic passages and improves overall results on this task by about $3\%$.
LEGO: Language Model Building Blocks
Oct 23, 2024Large language models (LLMs) are essential in natural language processing (NLP) but are costly in data collection, pre-training, fine-tuning, and inference. Task-specific small language models (SLMs) offer a cheaper alternative but lack robustness and generalization. This paper proposes LEGO, a novel technique to extract SLMs from an LLM and recombine them. Using state-of-the-art LLM pruning strategies, we can create task- and user-specific SLM building blocks that are efficient for fine-tuning and inference while also preserving user data privacy. LEGO utilizes Federated Learning and a novel aggregation scheme for the LLM reconstruction, maintaining robustness without high costs and preserving user data privacy. We experimentally demonstrate the versatility of LEGO, showing its ability to enable model heterogeneity and mitigate the effects of data heterogeneity while maintaining LLM robustness.