 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACCOR: Attention-Enhanced Complex-Valued Contrastive Learning for Occluded Object Classification Using mmWave Radar IQ Signals
Dec 12, 2025



Millimeter-wave (mmWave) radar has emerged as a robust sensing modality for several areas, offering reliable operation under adverse environmental conditions. Its ability to penetrate lightweight materials such as packaging or thin walls enables non-visual sensing in industrial and automated environments and can provide robotic platforms with enhanced environmental perception when used alongside optical sensors. Recent work with MIMO mmWave radar has demonstrated its ability to penetrate cardboard packaging for occluded object classification. However, existing models leave room for improvement and warrant a more thorough evaluation across different sensing frequencies. In this paper, we propose ACCOR, an attention-enhanced complex-valued contrastive learning approach for radar, enabling robust occluded object classification. We process complex-valued IQ radar signals using a complex-valued CNN backbone, followed by a multi-head attention layer and a hybrid loss. Our proposed loss combines a weighted cross-entropy term with a supervised contrastive term. We further extend an existing 64 GHz dataset with a 67 GHz subset of the occluded objects and evaluate our model using both center frequencies. Performance evaluation demonstrates that our approach outperforms prior radar-specific models and image classification models with adapted input, achieving classification accuracies of 96.60% at 64 GHz and 93.59% at 67 GHz for ten different objects. These results demonstrate the benefits of complex-valued deep learning with attention and contrastive learning for mmWave radar-based occluded object classification in industrial and automated environments.
Outside Knowledge Conversational Video (OKCV) Dataset -- Dialoguing over Videos
Jun 11, 2025



In outside knowledge visual question answering (OK-VQA), the model must identify relevant visual information within an image and incorporate external knowledge to accurately respond to a question. Extending this task to a visually grounded dialogue setting based on videos, a conversational model must both recognize pertinent visual details over time and answer questions where the required information is not necessarily present in the visual information. Moreover, the context of the overall conversation must be considered for the subsequent dialogue. To explore this task, we introduce a dataset comprised of $2,017$ videos with $5,986$ human-annotated dialogues consisting of $40,954$ interleaved dialogue turns. While the dialogue context is visually grounded in specific video segments, the questions further require external knowledge that is not visually present. Thus, the model not only has to identify relevant video parts but also leverage external knowledge to converse within the dialogue. We further provide several baselines evaluated on our dataset and show future challenges associated with this task. The dataset is made publicly available here: https://github.com/c-patsch/OKCV.
Technical Report for Egocentric Mistake Detection for the HoloAssist Challenge
Jun 06, 2025In this report, we address the task of online mistake detection, which is vital in domains like industrial automation and education, where real-time video analysis allows human operators to correct errors as they occur. While previous work focuses on procedural errors involving action order, broader error types must be addressed for real-world use. We introduce an online mistake detection framework that handles both procedural and execution errors (e.g., motor slips or tool misuse). Upon detecting an error, we use a large language model (LLM) to generate explanatory feedback. Experiments on the HoloAssist benchmark confirm the effectiveness of our approach, where our approach is placed second on the mistake detection task.
Watch and Learn: Leveraging Expert Knowledge and Language for Surgical Video Understanding
Mar 14, 2025Automated surgical workflow analysis is crucial for education, research, and clinical decision-making, but the lack of annotated datasets hinders the development of accurate and comprehensive workflow analysis solutions. We introduce a novel approach for addressing the sparsity and heterogeneity of annotated training data inspired by the human learning procedure of watching experts and understanding their explanations. Our method leverages a video-language model trained on alignment, denoising, and generative tasks to learn short-term spatio-temporal and multimodal representations. A task-specific temporal model is then used to capture relationships across entire videos. To achieve comprehensive video-language understanding in the surgical domain, we introduce a data collection and filtering strategy to construct a large-scale pretraining dataset from educational YouTube videos. We then utilize parameter-efficient fine-tuning by projecting downstream task annotations from publicly available surgical datasets into the language domain. Extensive experiments in two surgical domains demonstrate the effectiveness of our approach, with performance improvements of up to 7% in phase segmentation tasks, 8% in zero-shot phase segmentation, and comparable capabilities to fully-supervised models in few-shot settings. Harnessing our model's capabilities for long-range temporal localization and text generation, we present the first comprehensive solution for dense video captioning (DVC) of surgical videos, addressing this task despite the absence of existing DVC datasets in the surgical domain. We introduce a novel approach to surgical workflow understanding that leverages video-language pretraining, large-scale video pretraining, and optimized fine-tuning. Our method improves performance over state-of-the-art techniques and enables new downstream tasks for surgical video understanding.
ADL4D: Towards A Contextually Rich Dataset for 4D Activities of Daily Living
Feb 27, 2024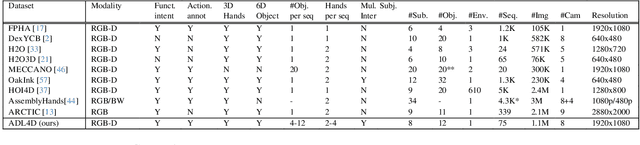



Hand-Object Interactions (HOIs) are conditioned on spatial and temporal contexts like surrounding objects, pre- vious actions, and future intents (for example, grasping and handover actions vary greatly based on objects proximity and trajectory obstruction). However, existing datasets for 4D HOI (3D HOI over time) are limited to one subject inter- acting with one object only. This restricts the generalization of learning-based HOI methods trained on those datasets. We introduce ADL4D, a dataset of up to two subjects inter- acting with different sets of objects performing Activities of Daily Living (ADL) like breakfast or lunch preparation ac- tivities. The transition between multiple objects to complete a certain task over time introduces a unique context lacking in existing datasets. Our dataset consists of 75 sequences with a total of 1.1M RGB-D frames, hand and object poses, and per-hand fine-grained action annotations. We develop an automatic system for multi-view multi-hand 3D pose an- notation capable of tracking hand poses over time. We inte- grate and test it against publicly available datasets. Finally, we evaluate our dataset on the tasks of Hand Mesh Recov- ery (HMR) and Hand Action Segmentation (HAS).