 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADL4D: Towards A Contextually Rich Dataset for 4D Activities of Daily Living
Feb 27, 2024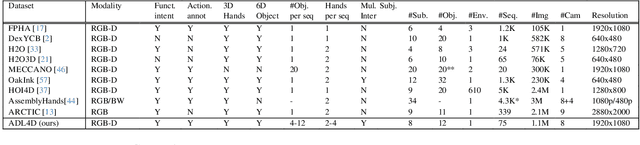



Hand-Object Interactions (HOIs) are conditioned on spatial and temporal contexts like surrounding objects, pre- vious actions, and future intents (for example, grasping and handover actions vary greatly based on objects proximity and trajectory obstruction). However, existing datasets for 4D HOI (3D HOI over time) are limited to one subject inter- acting with one object only. This restricts the generalization of learning-based HOI methods trained on those datasets. We introduce ADL4D, a dataset of up to two subjects inter- acting with different sets of objects performing Activities of Daily Living (ADL) like breakfast or lunch preparation ac- tivities. The transition between multiple objects to complete a certain task over time introduces a unique context lacking in existing datasets. Our dataset consists of 75 sequences with a total of 1.1M RGB-D frames, hand and object poses, and per-hand fine-grained action annotations. We develop an automatic system for multi-view multi-hand 3D pose an- notation capable of tracking hand poses over time. We inte- grate and test it against publicly available datasets. Finally, we evaluate our dataset on the tasks of Hand Mesh Recov- ery (HMR) and Hand Action Segmentation (HAS).
VR-based generation of photorealistic synthetic data for training hand-object tracking models
Feb 02, 2024



Supervised learning models for precise tracking of hand-object interactions (HOI) in 3D require large amounts of annotated data for training. Moreover, it is not intuitive for non-experts to label 3D ground truth (e.g. 6DoF object pose) on 2D images. To address these issues, we present "blender-hoisynth", an interactive synthetic data generator based on the Blender software. Blender-hoisynth can scalably generate and automatically annotate visual HOI training data. Other competing approaches usually generate synthetic HOI data compeletely without human input. While this may be beneficial in some scenarios, HOI applications inherently necessitate direct control over the HOIs as an expression of human intent. With blender-hoisynth, it is possible for users to interact with objects via virtual hands using standard Virtual Reality hardware. The synthetically generated data are characterized by a high degree of photorealism and contain visually plausible and physically realistic videos of hands grasping objects and moving them around in 3D. To demonstrate the efficacy of our data generation, we replace large parts of the training data in the well-known DexYCB dataset with hoisynth data and train a state-of-the-art HOI reconstruction model with it. We show that there is no significant degradation in the model performance despite the data replacement.