 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGFVR: Reference-Guided Face Video Restoration with Flow Matching
Jun 15, 2026Face video restoration from degraded observations is challenging, as it requires simultaneously recovering visual fidelity, temporal consistency, and subject identity. Existing approaches are often either reference-free, which can lead to identity loss when person-specific facial details are lost, or subject-specific, which limits generalization to unseen identities. We propose a subject-agnostic, reference-guided framework for identity-preserving face video restoration. Our method introduces bimodal perceptual-descriptive identity conditioning into a pretrained flow-based text-to-video generator and employs a two-stage training strategy to strengthen identity guidance during restoration. Experiments show that our approach improves restoration fidelity, temporal consistency, and identity preservation, achieving superior performance under challenging video degradations, including downsampling, blur, noise, and compression artifacts. The code is available under: https://github.com/batuhanntosun/RG-FVR.
DinoComplete: 3D Shape Completion with Distilled Semantic Priors and State Space Models
May 26, 20263D shape completion from partial scans remains challenging for unseen categories and noisy real-world observations, where geometry alone is often insufficient for inferring missing structure. We present DinoComplete, a deterministic and efficient shape completion framework that augments geometric reconstruction with voxel-aligned semantic priors distilled from DINO features. First, we construct multi-view DINO feature volumes aligned with ShapeNet data and train a student network to predict dense semantic features directly from incomplete shapes. These predicted features capture global structure and part-aware semantic context while remaining aligned with the underlying geometry. We then integrate these distilled features into a completion network, where geometric and semantic voxel representations are fused through voxel state-space modeling. To enable efficient long-range reasoning without sacrificing resolution, we introduce a multi-scale voxel Mamba module that refines the fused features by combining full-grid and chunk-wise sequence modeling. Experiments on unseen ShapeNet categories and ScanNet objects show that DinoComplete achieves stronger completion quality than prior deterministic and generative based completion methods while using fewer parameters, requiring lower memory, and achieving faster inference. Our results demonstrate that distilling semantic priors from visual foundation models improves generalization and robustness in 3D shape completion.
RadarCNN: Learning-based Indoor Object Classification from IQ Imaging Radar Data
Apr 08, 2026Radar sensors operating in the mmWave frequency range face challenges when used as indoor perception and imaging devices, primarily due to noise and multipath signal distortions. These distortions often impair the sensors' ability to accurately perceive and image the indoor environment. Nevertheless, this sensor offers distinct advantages over camera and LiDAR sensors. This encompasses the estimation of object reflectivity, known as radar cross-section (RCS), and the ability to penetrate through objects that are thin or have low reflectivity. This results in a 'through-the-wall' sensing capability. Due to the aforementioned disadvantages, most research in the field of imaging radar tends to exclude indoor areas. We introduce a machine learning-based mmWave MIMO FMCW imaging radar object classifier designed to identify small, hand-sized objects in indoor settings, utilizing only radar IQ samples as input. This system achieves 97-99 % accuracy on our test set and maintains approximately 50 % accuracy even under challenging conditions, such as increased background noise and occlusion of sample objects, without the need for adjusting training or pre-processing. This demonstrates the robustness of our approach and offers insights into what needs to be improved in the future to achieve generalization and very high accuracy even in the presence of significant indoor perturbations.
SMCNet: Supervised Surface Material Classification Using mmWave Radar IQ Signals and Complex-valued CNNs
Apr 08, 2026Understanding surface material properties is crucial for enhancing indoor robot perception and indoor digital twinning. However, not all sensor modalities typically employed for this task are capable of reliably capturing detailed surface material characteristics. By analyzing the reflected RF signal from a mmWave radar sensor, it is possible to extract information about the reflective material and its composition from a certain surface. We introduce a mmWave MIMO FMCW radar-based surface material classifier SMCNet, employing a complex-valued Convolutional Neural Network (CNN) and complex radar IQ signal input for classifying indoor surface materials. While current radar-based material estimation approaches rely on a fixed sensing distance and constrained setups, our approach incorporates a setup with multiple sensing distances. We trained SMCNet using data from three distinct distances and subsequently tested it on these distances, as well as on two more unseen distances. We reached an overall accuracy of 99.12-99.53 % on our test set. Notably, range FFT pre-processing improved accuracy on unknown distances from 25.25 % to 58.81 % without re-training.
High-Fidelity Causal Video Diffusion Models for Real-Time Ultra-Low-Bitrate Semantic Communication
Feb 14, 2026We introduce a video diffusion model for high-fidelity, causal, and real-time video generation under ultra-low-bitrate semantic communication constraints. Our approach utilizes lossy semantic video coding to transmit the semantic scene structure, complemented by a stream of highly compressed, low-resolution frames that provide sufficient texture information to preserve fidelity. Building on these inputs, we introduce a modular video diffusion model that contains Semantic Control, Restoration Adapter, and Temporal Adapter. We further introduce an efficient temporal distillation procedure that enables extension to real-time and causal synthesis, reducing trainable parameters by 300x and training time by 2x, while adhering to communication constraints. Evaluated across diverse datasets, the framework achieves strong perceptual quality, semantic fidelity, and temporal consistency at ultra-low bitrates (< 0.0003 bpp), outperforming classical, neural, and generative baselines in extensive quantitative, qualitative, and subjective evaluations.
REVNET: Rotation-Equivariant Point Cloud Completion via Vector Neuron Anchor Transformer
Jan 13, 2026Incomplete point clouds captured by 3D sensors often result in the loss of both geometric and semantic information. Most existing point cloud completion methods are built on rotation-variant frameworks trained with data in canonical poses, limiting their applicability in real-world scenarios. While data augmentation with random rotations can partially mitigate this issue, it significantly increases the learning burden and still fails to guarantee robust performance under arbitrary poses. To address this challenge, we propose the Rotation-Equivariant Anchor Transformer (REVNET), a novel framework built upon the Vector Neuron (VN) network for robust point cloud completion under arbitrary rotations. To preserve local details, we represent partial point clouds as sets of equivariant anchors and design a VN Missing Anchor Transformer to predict the positions and features of missing anchors. Furthermore, we extend VN networks with a rotation-equivariant bias formulation and a ZCA-based layer normalization to improve feature expressiveness. Leveraging the flexible conversion between equivariant and invariant VN features, our model can generate point coordinates with greater stability. Experimental results show that our method outperforms state-of-the-art approaches on the synthetic MVP dataset in the equivariant setting. On the real-world KITTI dataset, REVNET delivers competitive results compared to non-equivariant networks, without requiring input pose alignment. The source code will be released on GitHub under URL: https://github.com/nizhf/REVNET.
FOODER: Real-time Facial Authentication and Expression Recognition
Dec 19, 2025

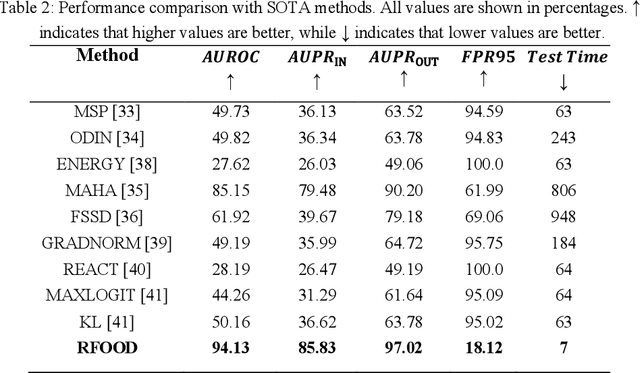

Out-of-distribution (OOD) detection is essential for the safe deployment of neural networks, as it enables the identification of samples outside the training domain. We present FOODER, a real-time, privacy-preserving radar-based framework that integrates OOD-based facial authentication with facial expression recognition. FOODER operates using low-cost frequency-modulated continuous-wave (FMCW) radar and exploits both range-Doppler and micro range-Doppler representations. The authentication module employs a multi-encoder multi-decoder architecture with Body Part (BP) and Intermediate Linear Encoder-Decoder (ILED) components to classify a single enrolled individual as in-distribution while detecting all other faces as OOD. Upon successful authentication, an expression recognition module is activated. Concatenated radar representations are processed by a ResNet block to distinguish between dynamic and static facial expressions. Based on this categorization, two specialized MobileViT networks are used to classify dynamic expressions (smile, shock) and static expressions (neutral, anger). This hierarchical design enables robust facial authentication and fine-grained expression recognition while preserving user privacy by relying exclusively on radar data. Experiments conducted on a dataset collected with a 60 GHz short-range FMCW radar demonstrate that FOODER achieves an AUROC of 94.13% and an FPR95 of 18.12% for authentication, along with an average expression recognition accuracy of 94.70%. FOODER outperforms state-of-the-art OOD detection methods and several transformer-based architectures while operating efficiently in real time.
ACCOR: Attention-Enhanced Complex-Valued Contrastive Learning for Occluded Object Classification Using mmWave Radar IQ Signals
Dec 12, 2025



Millimeter-wave (mmWave) radar has emerged as a robust sensing modality for several areas, offering reliable operation under adverse environmental conditions. Its ability to penetrate lightweight materials such as packaging or thin walls enables non-visual sensing in industrial and automated environments and can provide robotic platforms with enhanced environmental perception when used alongside optical sensors. Recent work with MIMO mmWave radar has demonstrated its ability to penetrate cardboard packaging for occluded object classification. However, existing models leave room for improvement and warrant a more thorough evaluation across different sensing frequencies. In this paper, we propose ACCOR, an attention-enhanced complex-valued contrastive learning approach for radar, enabling robust occluded object classification. We process complex-valued IQ radar signals using a complex-valued CNN backbone, followed by a multi-head attention layer and a hybrid loss. Our proposed loss combines a weighted cross-entropy term with a supervised contrastive term. We further extend an existing 64 GHz dataset with a 67 GHz subset of the occluded objects and evaluate our model using both center frequencies. Performance evaluation demonstrates that our approach outperforms prior radar-specific models and image classification models with adapted input, achieving classification accuracies of 96.60% at 64 GHz and 93.59% at 67 GHz for ten different objects. These results demonstrate the benefits of complex-valued deep learning with attention and contrastive learning for mmWave radar-based occluded object classification in industrial and automated environments.
RadarFuseNet: Complex-Valued Attention-Based Fusion of IQ Time- and Frequency-Domain Radar Features for Classification Tasks
Dec 12, 2025Millimeter-wave (mmWave) radar has emerged as a compact and powerful sensing modality for advanced perception tasks that leverage machine learning techniques. It is particularly effective in scenarios where vision-based sensors fail to capture reliable information, such as detecting occluded objects or distinguishing between different surface materials in indoor environments. Due to the non-linear characteristics of mmWave radar signals, deep learning-based methods are well suited for extracting relevant information from in-phase and quadrature (IQ) data. However, the current state of the art in IQ signal-based occluded-object and material classification still offers substantial potential for further improvement. In this paper, we propose a bidirectional cross-attention fusion network that combines IQ-signal and FFT-transformed radar features obtained by distinct complex-valued convolutional neural networks (CNNs). The proposed method achieves improved performance and robustness compared to standalone complex-valued CNNs. We achieve a near-perfect material classification accuracy of 99.92% on samples collected at same sensor-to-surface distances used during training, and an improved accuracy of 67.38% on samples measured at previously unseen distances, demonstrating improved generalization ability across varying measurement conditions. Furthermore, the accuracy for occluded object classification improves from 91.99% using standalone complex-valued CNNs to 94.20% using our proposed approach.
BIR-Adapter: A Low-Complexity Diffusion Model Adapter for Blind Image Restoration
Sep 08, 2025This paper introduces BIR-Adapter, a low-complexity blind image restoration adapter for diffusion models. The BIR-Adapter enables the utilization of the prior of pre-trained large-scale diffusion models on blind image restoration without training any auxiliary feature extractor. We take advantage of the robustness of pretrained models. We extract features from degraded images via the model itself and extend the self-attention mechanism with these degraded features. We introduce a sampling guidance mechanism to reduce hallucinations. We perform experiments on synthetic and real-world degradations and demonstrate that BIR-Adapter achieves competitive or better performance compared to state-of-the-art methods while having significantly lower complexity. Additionally, its adapter-based design enables integration into other diffusion models, enabling broader applications in image restoration tasks. We showcase this by extending a super-resolution-only model to perform better under additional unknown degradations.