 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Acoustic Audience Feedback in Large Virtual Events
Oct 27, 2023

The COVID-19 pandemic shifted many events in our daily lives into the virtual domain. While virtual conference systems provide an alternative to physical meetings, larger events require a muted audience to avoid an accumulation of background noise and distorted audio. However, performing artists strongly rely on the feedback of their audience. We propose a concept for a virtual audience framework which supports all participants with the ambience of a real audience. Audience feedback is collected locally, allowing users to express enthusiasm or discontent by selecting means such as clapping, whistling, booing, and laughter. This feedback is sent as abstract information to a virtual audience server. We broadcast the combined virtual audience feedback information to all participants, which can be synthesized as a single acoustic feedback by the client. The synthesis can be done by turning the collective audience feedback into a prompt that is fed to state-of-the-art models such as AudioGen. This way, each user hears a single acoustic feedback sound of the entire virtual event, without requiring to unmute or risk hearing distorted, unsynchronized feedback.
Transform Quantization for CNN Compression
Sep 02, 2020
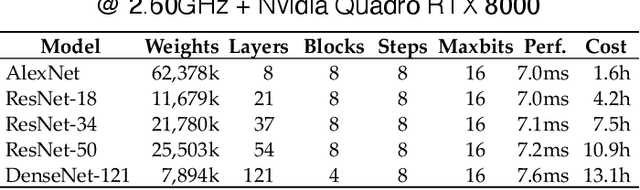
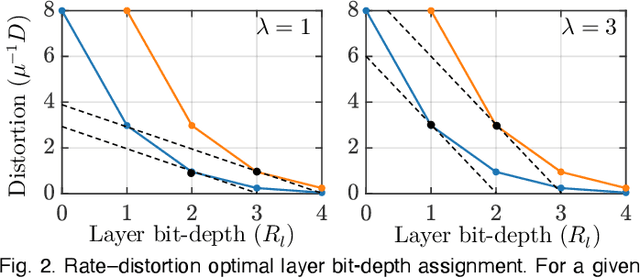
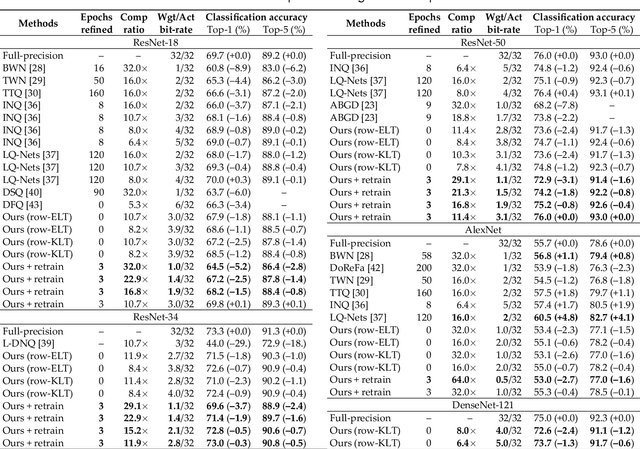
In this paper, we compress convolutional neural network (CNN) weights post-training via transform quantization. Previous CNN quantization techniques tend to ignore the joint statistics of weights and activations, producing sub-optimal CNN performance at a given quantization bit-rate, or consider their joint statistics during training only and do not facilitate efficient compression of already trained CNN models. We optimally transform (decorrelate) and quantize the weights post-training using a rate-distortion framework to improve compression at any given quantization bit-rate. Transform quantization unifies quantization and dimensionality reduction (decorrelation) techniques in a single framework to facilitate low bit-rate compression of CNNs and efficient inference in the transform domain. We first introduce a theory of rate and distortion for CNN quantization, and pose optimum quantization as a rate-distortion optimization problem. We then show that this problem can be solved using optimal bit-depth allocation following decorrelation by the optimal End-to-end Learned Transform (ELT) we derive in this paper. Experiments demonstrate that transform quantization advances the state of the art in CNN compression in both retrained and non-retrained quantization scenarios. In particular, we find that transform quantization with retraining is able to compress CNN models such as AlexNet, ResNet and DenseNet to very low bit-rates (1-2 bits).
LiFF: Light Field Features in Scale and Depth
Jan 13, 2019


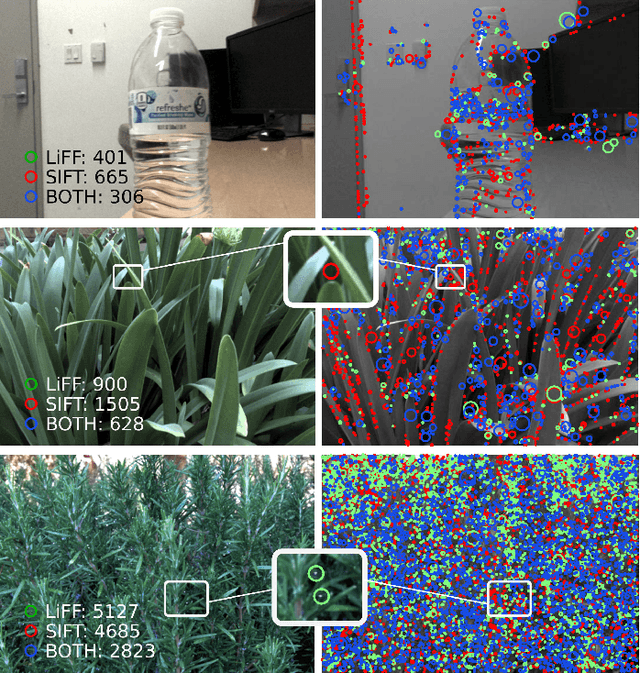
Feature detectors and descriptors are key low-level vision tools that many higher-level tasks build on. Unfortunately these fail in the presence of challenging light transport effects including partial occlusion, low contrast, and reflective or refractive surfaces. Building on spatio-angular imaging modalities offered by emerging light field cameras, we introduce a new and computationally efficient 4D light field feature detector and descriptor: LiFF. LiFF is scale invariant and utilizes the full 4D light field to detect features that are robust to changes in perspective. This is particularly useful for structure from motion (SfM) and other tasks that match features across viewpoints of a scene. We demonstrate significantly improved 3D reconstructions via SfM when using LiFF instead of the leading 2D or 4D features, and show that LiFF runs an order of magnitude faster than the leading 4D approach. Finally, LiFF inherently estimates depth for each feature, opening a path for future research in light field-based SfM.
Recurrent Neural Networks for Person Re-identification Revisited
Apr 10, 2018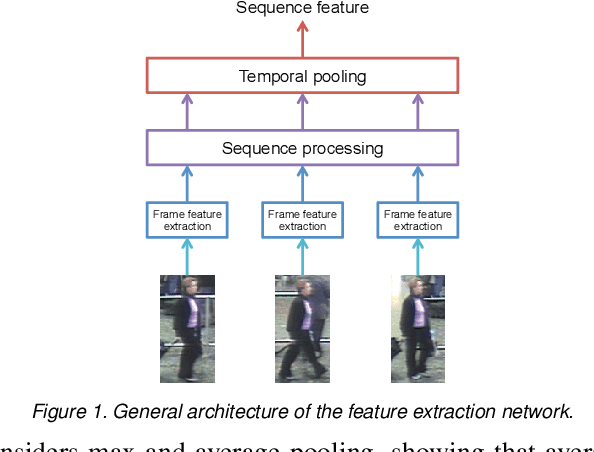
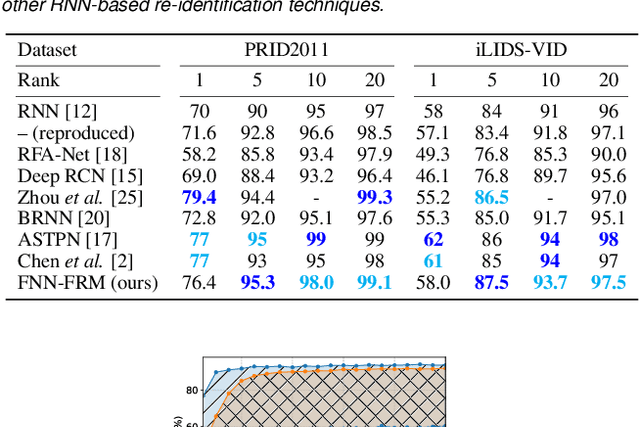
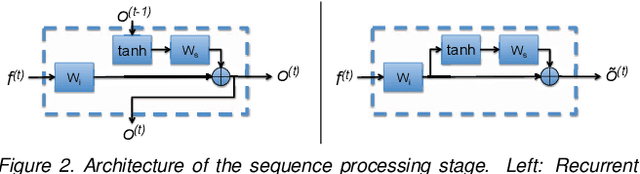
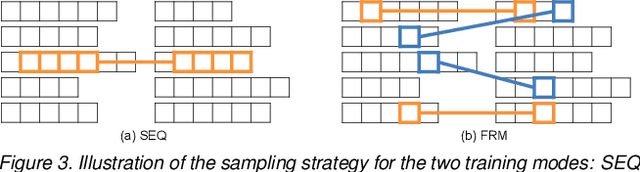
The task of person re-identification has recently received rising attention due to the high performance achieved by new methods based on deep learning. In particular, in the context of video-based re-identification, many state-of-the-art works have explored the use of Recurrent Neural Networks (RNNs) to process input sequences. In this work, we revisit this tool by deriving an approximation which reveals the small effect of recurrent connections, leading to a much simpler feed-forward architecture. Using the same parameters as the recurrent version, our proposed feed-forward architecture obtains very similar accuracy. More importantly, our model can be combined with a new training process to significantly improve re-identification performance. Our experiments demonstrate that the proposed models converge substantially faster than recurrent ones, with accuracy improvements by up to 5% on two datasets. The performance achieved is better or on par with other RNN-based person re-identification techniques.