 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Assisted Lifting Steps For Improved Fully Scalable Lossy Image Compression in JPEG 2000
Mar 04, 2024
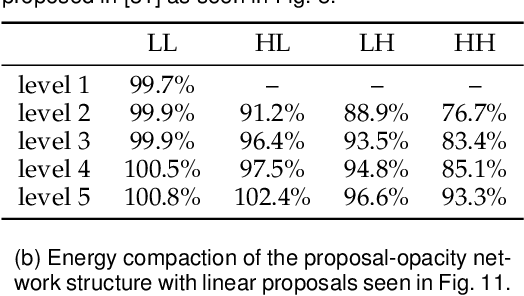


This work proposes to augment the lifting steps of the conventional wavelet transform with additional neural network assisted lifting steps. These additional steps reduce residual redundancy (notably aliasing information) amongst the wavelet subbands, and also improve the visual quality of reconstructed images at reduced resolutions. The proposed approach involves two steps, a high-to-low step followed by a low-to-high step. The high-to-low step suppresses aliasing in the low-pass band by using the detail bands at the same resolution, while the low-to-high step aims to further remove redundancy from detail bands, so as to achieve higher energy compaction. The proposed two lifting steps are trained in an end-to-end fashion; we employ a backward annealing approach to overcome the non-differentiability of the quantization and cost functions during back-propagation. Importantly, the networks employed in this paper are compact and with limited non-linearities, allowing a fully scalable system; one pair of trained network parameters are applied for all levels of decomposition and for all bit-rates of interest. By employing the proposed approach within the JPEG 2000 image coding standard, our method can achieve up to 17.4% average BD bit-rate saving over a wide range of bit-rates, while retaining quality and resolution scalability features of JPEG 2000.
Exploration of Learned Lifting-Based Transform Structures for Fully Scalable and Accessible Wavelet-Like Image Compression
Feb 29, 2024



This paper provides a comprehensive study on features and performance of different ways to incorporate neural networks into lifting-based wavelet-like transforms, within the context of fully scalable and accessible image compression. Specifically, we explore different arrangements of lifting steps, as well as various network architectures for learned lifting operators. Moreover, we examine the impact of the number of learned lifting steps, the number of channels, the number of layers and the support of kernels in each learned lifting operator. To facilitate the study, we investigate two generic training methodologies that are simultaneously appropriate to a wide variety of lifting structures considered. Experimental results ultimately suggest that retaining fixed lifting steps from the base wavelet transform is highly beneficial. Moreover, we demonstrate that employing more learned lifting steps and more layers in each learned lifting operator do not contribute strongly to the compression performance. However, benefits can be obtained by utilizing more channels in each learned lifting operator. Ultimately, the learned wavelet-like transform proposed in this paper achieves over 25% bit-rate savings compared to JPEG 2000 with compact spatial support.
Efficient Motion Modelling with Variable-sized blocks from Hierarchical Cuboidal Partitioning
Aug 28, 2022



Motion modelling with block-based architecture has been widely used in video coding where a frame is divided into fixed-sized blocks that are motion compensated independently. This often leads to coding inefficiency as fixed-sized blocks hardly align with the object boundaries. Although hierarchical block-partitioning has been introduced to address this, the increased number of motion vectors limits the benefit. Recently, approximate segmentation of images with cuboidal partitioning has gained popularity. Not only are the variable-sized rectangular segments (cuboids) readily amenable to block-based image/video coding techniques, but they are also capable of aligning well with the object boundaries. This is because cuboidal partitioning is based on a homogeneity constraint, minimising the sum of squared errors (SSE). In this paper, we have investigated the potential of cuboids in motion modelling against the fixed-sized blocks used in scalable video coding. Specifically, we have constructed motion-compensated current frame using the cuboidal partitioning information of the anchor frame in a group-of-picture (GOP). The predicted current frame has then been used as the base layer while encoding the current frame as an enhancement layer using the scalable HEVC encoder. Experimental results confirm 6.71%-10.90% bitrate savings on 4K video sequences.
Human-Machine Collaborative Video Coding Through Cuboidal Partitioning
Feb 02, 2021


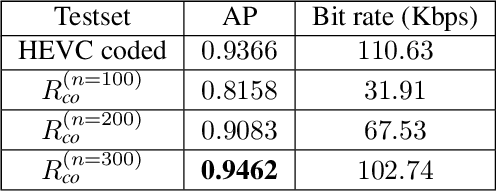
Video coding algorithms encode and decode an entire video frame while feature coding techniques only preserve and communicate the most critical information needed for a given application. This is because video coding targets human perception, while feature coding aims for machine vision tasks. Recently, attempts are being made to bridge the gap between these two domains. In this work, we propose a video coding framework by leveraging on to the commonality that exists between human vision and machine vision applications using cuboids. This is because cuboids, estimated rectangular regions over a video frame, are computationally efficient, has a compact representation and object centric. Such properties are already shown to add value to traditional video coding systems. Herein cuboidal feature descriptors are extracted from the current frame and then employed for accomplishing a machine vision task in the form of object detection. Experimental results show that a trained classifier yields superior average precision when equipped with cuboidal features oriented representation of the current test frame. Additionally, this representation costs 7% less in bit rate if the captured frames are need be communicated to a receiver.
Transform Quantization for CNN Compression
Sep 02, 2020
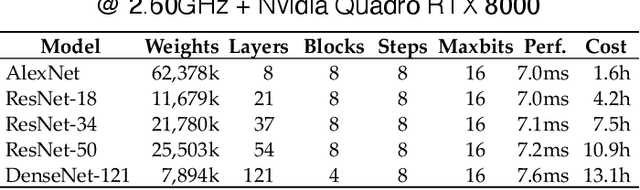
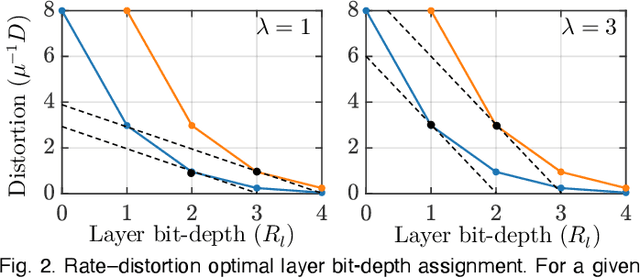
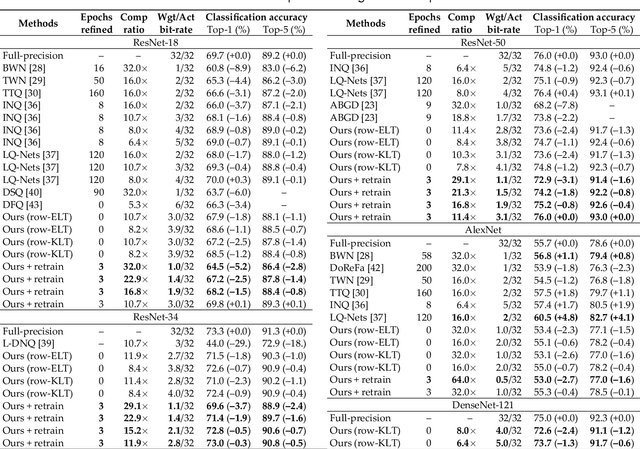
In this paper, we compress convolutional neural network (CNN) weights post-training via transform quantization. Previous CNN quantization techniques tend to ignore the joint statistics of weights and activations, producing sub-optimal CNN performance at a given quantization bit-rate, or consider their joint statistics during training only and do not facilitate efficient compression of already trained CNN models. We optimally transform (decorrelate) and quantize the weights post-training using a rate-distortion framework to improve compression at any given quantization bit-rate. Transform quantization unifies quantization and dimensionality reduction (decorrelation) techniques in a single framework to facilitate low bit-rate compression of CNNs and efficient inference in the transform domain. We first introduce a theory of rate and distortion for CNN quantization, and pose optimum quantization as a rate-distortion optimization problem. We then show that this problem can be solved using optimal bit-depth allocation following decorrelation by the optimal End-to-end Learned Transform (ELT) we derive in this paper. Experiments demonstrate that transform quantization advances the state of the art in CNN compression in both retrained and non-retrained quantization scenarios. In particular, we find that transform quantization with retraining is able to compress CNN models such as AlexNet, ResNet and DenseNet to very low bit-rates (1-2 bits).