 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Efficacy of Sentinel-2 versus Aerial Imagery in Serrated Tussock Classification
Dec 12, 2025Invasive species pose major global threats to ecosystems and agriculture. Serrated tussock (\textit{Nassella trichotoma}) is a highly competitive invasive grass species that disrupts native grasslands, reduces pasture productivity, and increases land management costs. In Victoria, Australia, it presents a major challenge due to its aggressive spread and ecological impact. While current ground surveys and subsequent management practices are effective at small scales, they are not feasible for landscape-scale monitoring. Although aerial imagery offers high spatial resolution suitable for detailed classification, its high cost limits scalability. Satellite-based remote sensing provides a more cost-effective and scalable alternative, though often with lower spatial resolution. This study evaluates whether multi-temporal Sentinel-2 imagery, despite its lower spatial resolution, can provide a comparable and cost-effective alternative for landscape-scale monitoring of serrated tussock by leveraging its higher spectral resolution and seasonal phenological information. A total of eleven models have been developed using various combinations of spectral bands, texture features, vegetation indices, and seasonal data. Using a random forest classifier, the best-performing Sentinel-2 model (M76*) has achieved an Overall Accuracy (OA) of 68\% and an Overall Kappa (OK) of 0.55, slightly outperforming the best-performing aerial imaging model's OA of 67\% and OK of 0.52 on the same dataset. These findings highlight the potential of multi-seasonal feature-enhanced satellite-based models for scalable invasive species classification.
A Novel Image Similarity Metric for Scene Composition Structure
Aug 07, 2025The rapid advancement of generative AI models necessitates novel methods for evaluating image quality that extend beyond human perception. A critical concern for these models is the preservation of an image's underlying Scene Composition Structure (SCS), which defines the geometric relationships among objects and the background, their relative positions, sizes, orientations, etc. Maintaining SCS integrity is paramount for ensuring faithful and structurally accurate GenAI outputs. Traditional image similarity metrics often fall short in assessing SCS. Pixel-level approaches are overly sensitive to minor visual noise, while perception-based metrics prioritize human aesthetic appeal, neither adequately capturing structural fidelity. Furthermore, recent neural-network-based metrics introduce training overheads and potential generalization issues. We introduce the SCS Similarity Index Measure (SCSSIM), a novel, analytical, and training-free metric that quantifies SCS preservation by exploiting statistical measures derived from the Cuboidal hierarchical partitioning of images, robustly capturing non-object-based structural relationships. Our experiments demonstrate SCSSIM's high invariance to non-compositional distortions, accurately reflecting unchanged SCS. Conversely, it shows a strong monotonic decrease for compositional distortions, precisely indicating when SCS has been altered. Compared to existing metrics, SCSSIM exhibits superior properties for structural evaluation, making it an invaluable tool for developing and evaluating generative models, ensuring the integrity of scene composition.
ReflectGAN: Modeling Vegetation Effects for Soil Carbon Estimation from Satellite Imagery
May 24, 2025


Soil organic carbon (SOC) is a critical indicator of soil health, but its accurate estimation from satellite imagery is hindered in vegetated regions due to spectral contamination from plant cover, which obscures soil reflectance and reduces model reliability. This study proposes the Reflectance Transformation Generative Adversarial Network (ReflectGAN), a novel paired GAN-based framework designed to reconstruct accurate bare soil reflectance from vegetated soil satellite observations. By learning the spectral transformation between vegetated and bare soil reflectance, ReflectGAN facilitates more precise SOC estimation under mixed land cover conditions. Using the LUCAS 2018 dataset and corresponding Landsat 8 imagery, we trained multiple learning-based models on both original and ReflectGAN-reconstructed reflectance inputs. Models trained on ReflectGAN outputs consistently outperformed those using existing vegetation correction methods. For example, the best-performing model (RF) achieved an $R^2$ of 0.54, RMSE of 3.95, and RPD of 2.07 when applied to the ReflectGAN-generated signals, representing a 35\% increase in $R^2$, a 43\% reduction in RMSE, and a 43\% improvement in RPD compared to the best existing method (PMM-SU). The performance of the models with ReflectGAN is also better compared to their counterparts when applied to another dataset, i.e., Sentinel-2 imagery. These findings demonstrate the potential of ReflectGAN to improve SOC estimation accuracy in vegetated landscapes, supporting more reliable soil monitoring.
Hyperspectral Imaging-Based Grain Quality Assessment With Limited Labelled Data
Nov 17, 2024



Recently hyperspectral imaging (HSI)-based grain quality assessment has gained research attention. However, unlike other imaging modalities, HSI data lacks sufficient labelled samples required to effectively train deep convolutional neural network (DCNN)-based classifiers. In this paper, we present a novel approach to grain quality assessment using HSI combined with few-shot learning (FSL) techniques. Traditional methods for grain quality evaluation, while reliable, are invasive, time-consuming, and costly. HSI offers a non-invasive, real-time alternative by capturing both spatial and spectral information. However, a significant challenge in applying DCNNs for HSI-based grain classification is the need for large labelled databases, which are often difficult to obtain. To address this, we explore the use of FSL, which enables models to perform well with limited labelled data, making it a practical solution for real-world applications where rapid deployment is required. We also explored the application of FSL for the classification of hyperspectral images of bulk grains to enable rapid quality assessment at various receival points in the grain supply chain. We evaluated the performance of few-shot classifiers in two scenarios: first, classification of grain types seen during training, and second, generalisation to unseen grain types, a crucial feature for real-world applications. In the first scenario, we introduce a novel approach using pre-computed collective class prototypes (CCPs) to enhance inference efficiency and robustness. In the second scenario, we assess the model's ability to classify novel grain types using limited support examples. Our experimental results show that despite using very limited labelled data for training, our FSL classifiers accuracy is comparable to that of a fully trained classifier trained using a significantly larger labelled database.
FSDR: A Novel Deep Learning-based Feature Selection Algorithm for Pseudo Time-Series Data using Discrete Relaxation
Mar 13, 2024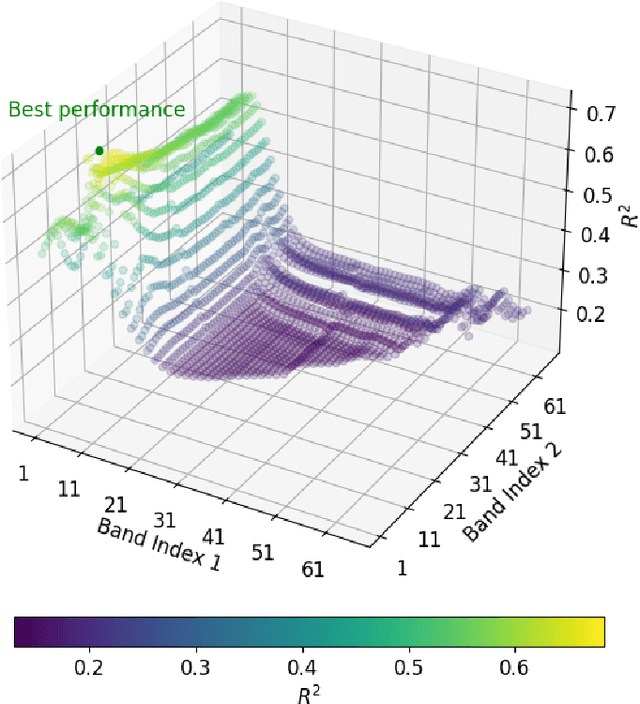
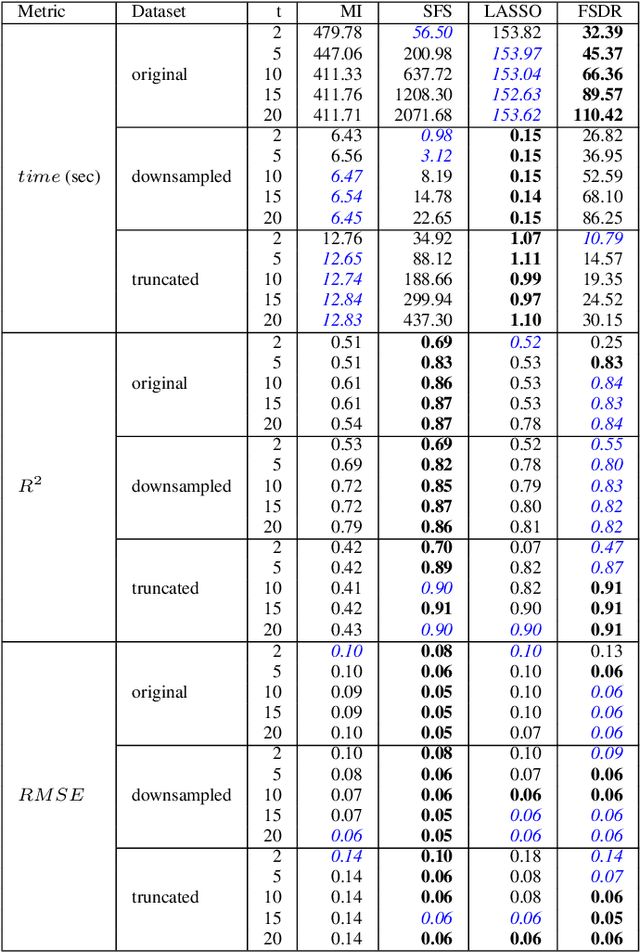
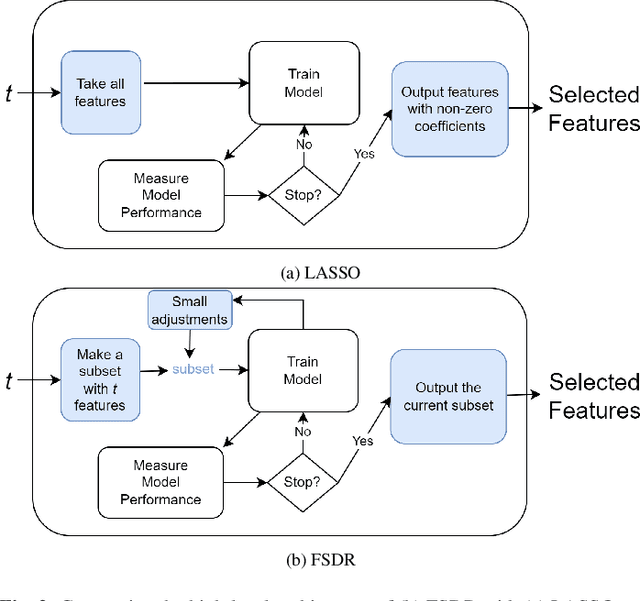
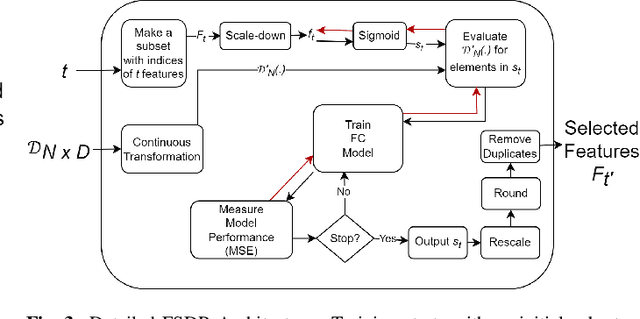
Conventional feature selection algorithms applied to Pseudo Time-Series (PTS) data, which consists of observations arranged in sequential order without adhering to a conventional temporal dimension, often exhibit impractical computational complexities with high dimensional data. To address this challenge, we introduce a Deep Learning (DL)-based feature selection algorithm: Feature Selection through Discrete Relaxation (FSDR), tailored for PTS data. Unlike the existing feature selection algorithms, FSDR learns the important features as model parameters using discrete relaxation, which refers to the process of approximating a discrete optimisation problem with a continuous one. FSDR is capable of accommodating a high number of feature dimensions, a capability beyond the reach of existing DL-based or traditional methods. Through testing on a hyperspectral dataset (i.e., a type of PTS data), our experimental results demonstrate that FSDR outperforms three commonly used feature selection algorithms, taking into account a balance among execution time, $R^2$, and $RMSE$.
Depth-based Sampling and Steering Constraints for Memoryless Local Planners
Nov 06, 2022By utilizing only depth information, the paper introduces a novel but efficient local planning approach that enhances not only computational efficiency but also planning performances for memoryless local planners. The sampling is first proposed to be based on the depth data which can identify and eliminate a specific type of in-collision trajectories in the sampled motion primitive library. More specifically, all the obscured primitives' endpoints are found through querying the depth values and excluded from the sampled set, which can significantly reduce the computational workload required in collision checking. On the other hand, we furthermore propose a steering mechanism also based on the depth information to effectively prevent an autonomous vehicle from getting stuck when facing a large convex obstacle, providing a higher level of autonomy for a planning system. Our steering technique is theoretically proved to be complete in scenarios of convex obstacles. To evaluate effectiveness of the proposed DEpth based both Sampling and Steering (DESS) methods, we implemented them in the synthetic environments where a quadrotor was simulated flying through a cluttered region with multiple size-different obstacles. The obtained results demonstrate that the proposed approach can considerably decrease computing time in local planners, where more trajectories can be evaluated while the best path with much lower cost can be found. More importantly, the success rates calculated by the fact that the robot successfully navigated to the destinations in different testing scenarios are always higher than 99.6% on average.
Efficient Motion Modelling with Variable-sized blocks from Hierarchical Cuboidal Partitioning
Aug 28, 2022



Motion modelling with block-based architecture has been widely used in video coding where a frame is divided into fixed-sized blocks that are motion compensated independently. This often leads to coding inefficiency as fixed-sized blocks hardly align with the object boundaries. Although hierarchical block-partitioning has been introduced to address this, the increased number of motion vectors limits the benefit. Recently, approximate segmentation of images with cuboidal partitioning has gained popularity. Not only are the variable-sized rectangular segments (cuboids) readily amenable to block-based image/video coding techniques, but they are also capable of aligning well with the object boundaries. This is because cuboidal partitioning is based on a homogeneity constraint, minimising the sum of squared errors (SSE). In this paper, we have investigated the potential of cuboids in motion modelling against the fixed-sized blocks used in scalable video coding. Specifically, we have constructed motion-compensated current frame using the cuboidal partitioning information of the anchor frame in a group-of-picture (GOP). The predicted current frame has then been used as the base layer while encoding the current frame as an enhancement layer using the scalable HEVC encoder. Experimental results confirm 6.71%-10.90% bitrate savings on 4K video sequences.
An Integrated Attribute Guided Dense Attention Model for Fine-Grained Generalized Zero-Shot Learning
Feb 05, 2021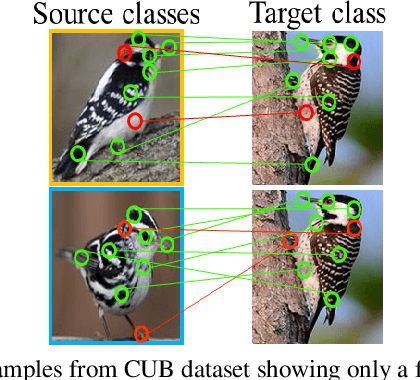
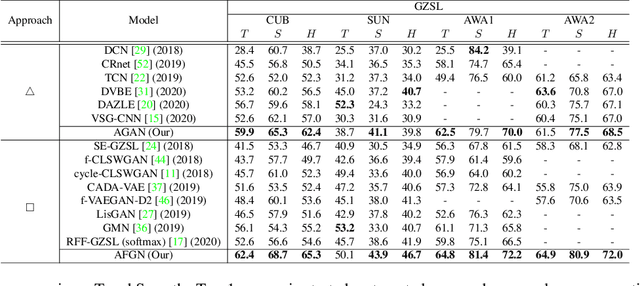
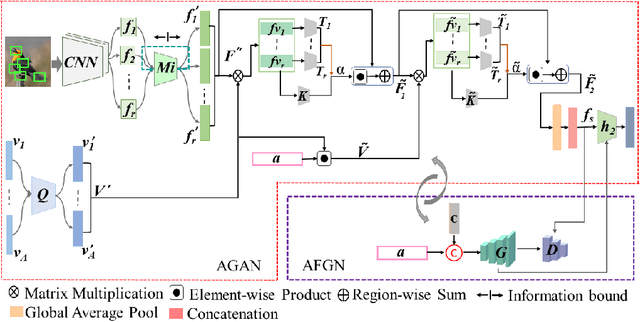
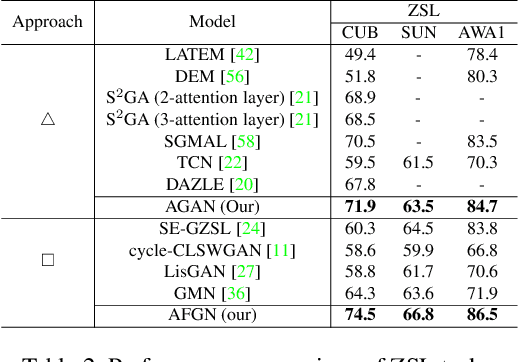
Embedding learning (EL) and feature synthesizing (FS) are two of the popular categories of fine-grained GZSL methods. The global feature exploring EL or FS methods do not explore fine distinction as they ignore local details. And, the local detail exploring EL or FS methods either neglect direct attribute guidance or global information. Consequently, neither method performs well. In this paper, we propose to explore global and direct attribute-supervised local visual features for both EL and FS categories in an integrated manner for fine-grained GZSL. The proposed integrated network has an EL sub-network and a FS sub-network. Consequently, the proposed integrated network can be tested in two ways. We propose a novel two-step dense attention mechanism to discover attribute-guided local visual features. We introduce new mutual learning between the sub-networks to exploit mutually beneficial information for optimization. Moreover, to reduce bias towards the source domain during testing, we propose to compute source-target class similarity based on mutual information and transfer-learn the target classes. We demonstrate that our proposed method outperforms contemporary methods on benchmark datasets.
Human-Machine Collaborative Video Coding Through Cuboidal Partitioning
Feb 02, 2021


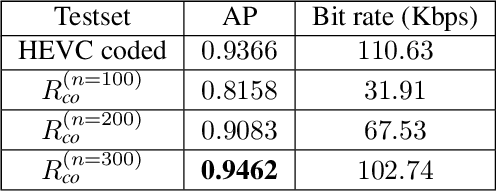
Video coding algorithms encode and decode an entire video frame while feature coding techniques only preserve and communicate the most critical information needed for a given application. This is because video coding targets human perception, while feature coding aims for machine vision tasks. Recently, attempts are being made to bridge the gap between these two domains. In this work, we propose a video coding framework by leveraging on to the commonality that exists between human vision and machine vision applications using cuboids. This is because cuboids, estimated rectangular regions over a video frame, are computationally efficient, has a compact representation and object centric. Such properties are already shown to add value to traditional video coding systems. Herein cuboidal feature descriptors are extracted from the current frame and then employed for accomplishing a machine vision task in the form of object detection. Experimental results show that a trained classifier yields superior average precision when equipped with cuboidal features oriented representation of the current test frame. Additionally, this representation costs 7% less in bit rate if the captured frames are need be communicated to a receiver.
Bidirectional Mapping Coupled GAN for Generalized Zero-Shot Learning
Dec 30, 2020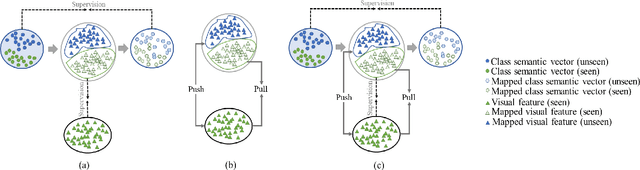
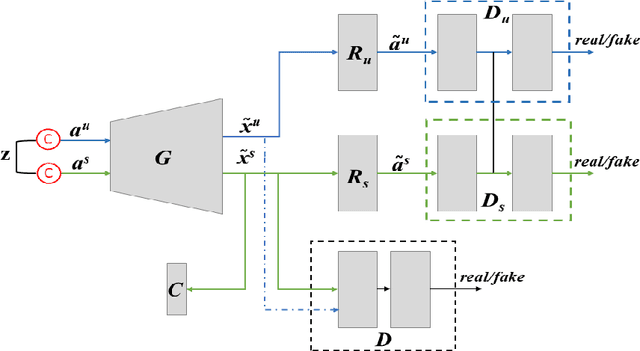

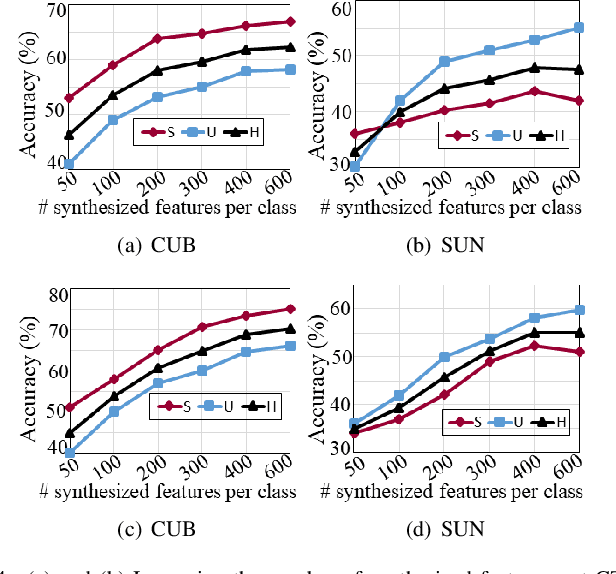
Bidirectional mapping-based generative models have achieved remarkable performance for the generalized zero-shot learning (GZSL) recognition by learning to construct visual features from class semantics and reconstruct class semantics back from generated visual features. The performance of these models relies on the quality of synthesized features. This depends on the ability of the model to capture the underlying seen data distribution by relating semantic-visual spaces, learning discriminative information, and re-purposing the learned distribution to recognize unseen data. This means learning the seen-unseen domains joint distribution is crucial for GZSL tasks. However, existing models only learn the underlying distribution of the seen domain as unseen data is inaccessible. In this work, we propose to utilize the available unseen class semantics along with seen class semantics and learn dual-domain joint distribution through a strong visual-semantic coupling. Therefore, we propose a bidirectional mapping coupled generative adversarial network (BMCoGAN) by extending the coupled generative adversarial network (CoGAN) into a dual-domain learning bidirectional mapping model. We further integrate a Wasserstein generative adversarial optimization to supervise the joint distribution learning. For retaining distinctive information in the synthesized visual space and reducing bias towards seen classes, we design an optimization, which pushes synthesized seen features towards real seen features and pulls synthesized unseen features away from real seen features. We evaluate BMCoGAN on several benchmark datasets against contemporary methods and show its superior performance. Also, we present ablative analysis to demonstrate the importance of different components in BMCoGAN.