 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Transcripts: A Renewed Perspective on Audio Chaptering
Feb 09, 2026Audio chaptering, the task of automatically segmenting long-form audio into coherent sections, is increasingly important for navigating podcasts, lectures, and videos. Despite its relevance, research remains limited and text-based, leaving key questions unresolved about leveraging audio information, handling ASR errors, and transcript-free evaluation. We address these gaps through three contributions: (1) a systematic comparison between text-based models with acoustic features, a novel audio-only architecture (AudioSeg) operating on learned audio representations, and multimodal LLMs; (2) empirical analysis of factors affecting performance, including transcript quality, acoustic features, duration, and speaker composition; and (3) formalized evaluation protocols contrasting transcript-dependent text-space protocols with transcript-invariant time-space protocols. Our experiments on YTSeg reveal that AudioSeg substantially outperforms text-based approaches, pauses provide the largest acoustic gains, and MLLMs remain limited by context length and weak instruction following, yet MLLMs are promising on shorter audio.
End-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.
KIT's Multilingual Speech Translation System for IWSLT 2023
Jun 15, 2023



Many existing speech translation benchmarks focus on native-English speech in high-quality recording conditions, which often do not match the conditions in real-life use-cases. In this paper, we describe our speech translation system for the multilingual track of IWSLT 2023, which evaluates translation quality on scientific conference talks. The test condition features accented input speech and terminology-dense contents. The task requires translation into 10 languages of varying amounts of resources. In absence of training data from the target domain, we use a retrieval-based approach (kNN-MT) for effective adaptation (+0.8 BLEU for speech translation). We also use adapters to easily integrate incremental training data from data augmentation, and show that it matches the performance of re-training. We observe that cascaded systems are more easily adaptable towards specific target domains, due to their separate modules. Our cascaded speech system substantially outperforms its end-to-end counterpart on scientific talk translation, although their performance remains similar on TED talks.
Depth-based Sampling and Steering Constraints for Memoryless Local Planners
Nov 06, 2022By utilizing only depth information, the paper introduces a novel but efficient local planning approach that enhances not only computational efficiency but also planning performances for memoryless local planners. The sampling is first proposed to be based on the depth data which can identify and eliminate a specific type of in-collision trajectories in the sampled motion primitive library. More specifically, all the obscured primitives' endpoints are found through querying the depth values and excluded from the sampled set, which can significantly reduce the computational workload required in collision checking. On the other hand, we furthermore propose a steering mechanism also based on the depth information to effectively prevent an autonomous vehicle from getting stuck when facing a large convex obstacle, providing a higher level of autonomy for a planning system. Our steering technique is theoretically proved to be complete in scenarios of convex obstacles. To evaluate effectiveness of the proposed DEpth based both Sampling and Steering (DESS) methods, we implemented them in the synthetic environments where a quadrotor was simulated flying through a cluttered region with multiple size-different obstacles. The obtained results demonstrate that the proposed approach can considerably decrease computing time in local planners, where more trajectories can be evaluated while the best path with much lower cost can be found. More importantly, the success rates calculated by the fact that the robot successfully navigated to the destinations in different testing scenarios are always higher than 99.6% on average.
Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models
Oct 01, 2020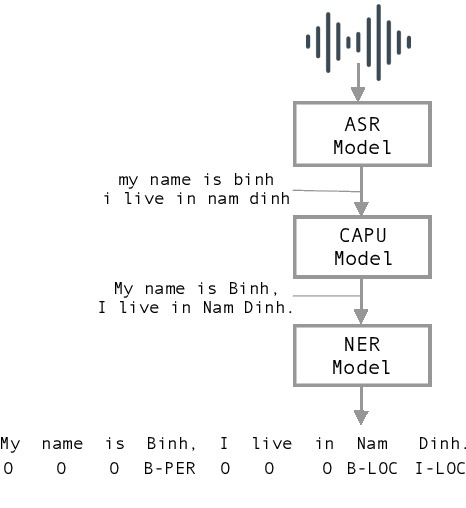

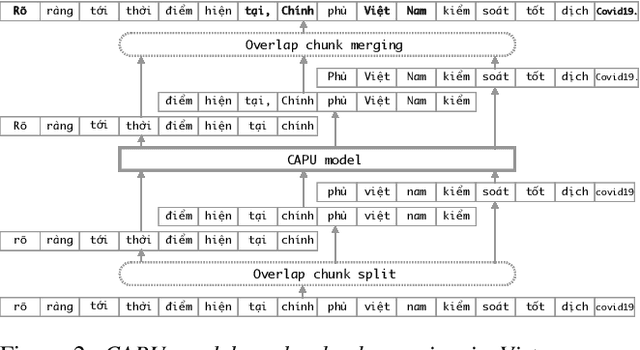
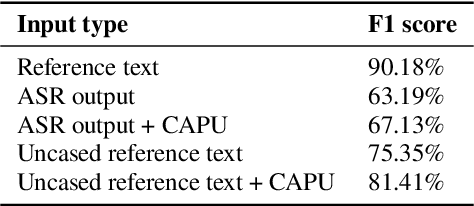
Studies on the Named Entity Recognition (NER) task have shown outstanding results that reach human parity on input texts with correct text formattings, such as with proper punctuation and capitalization. However, such conditions are not available in applications where the input is speech, because the text is generated from a speech recognition system (ASR), and that the system does not consider the text formatting. In this paper, we (1) presented the first Vietnamese speech dataset for NER task, and (2) the first pre-trained public large-scale monolingual language model for Vietnamese that achieved the new state-of-the-art for the Vietnamese NER task by 1.3% absolute F1 score comparing to the latest study. And finally, (3) we proposed a new pipeline for NER task from speech that overcomes the text formatting problem by introducing a text capitalization and punctuation recovery model (CaPu) into the pipeline. The model takes input text from an ASR system and performs two tasks at the same time, producing proper text formatting that helps to improve NER performance. Experimental results indicated that the CaPu model helps to improve by nearly 4% of F1-score.
VAIS Hate Speech Detection System: A Deep Learning based Approach for System Combination
Oct 12, 2019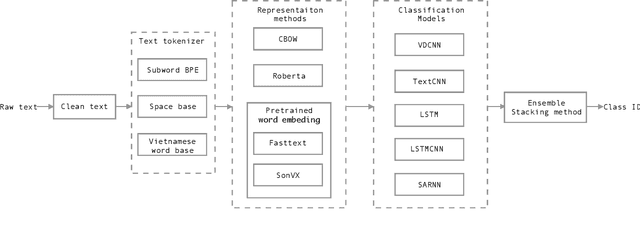
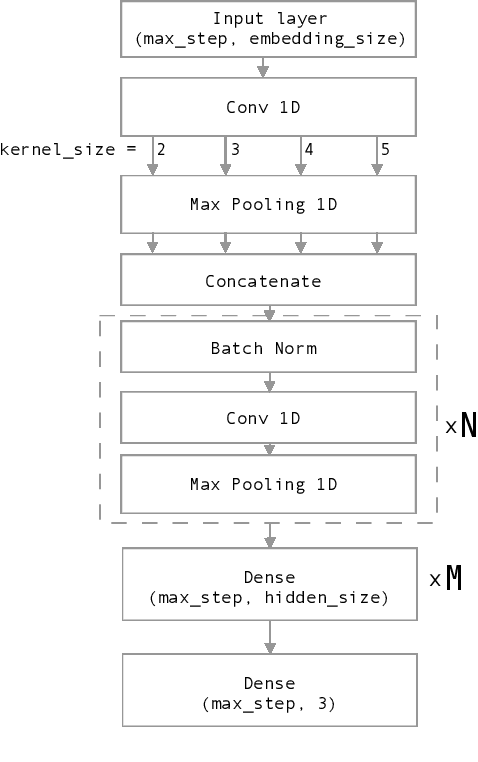
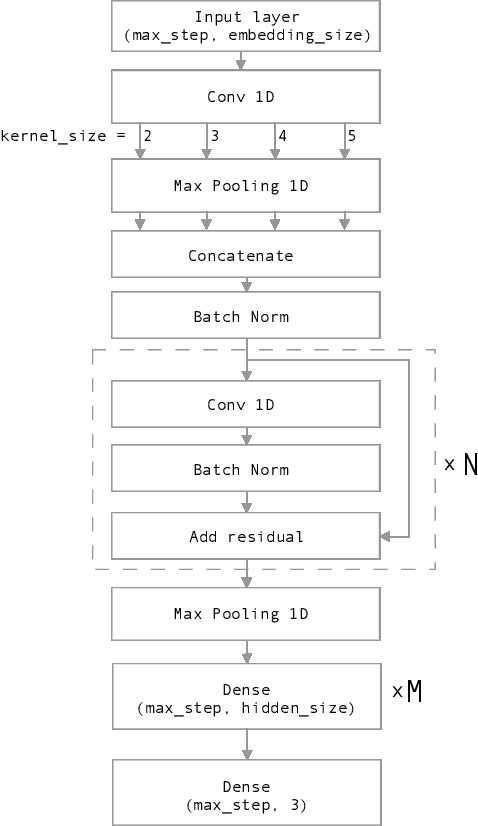
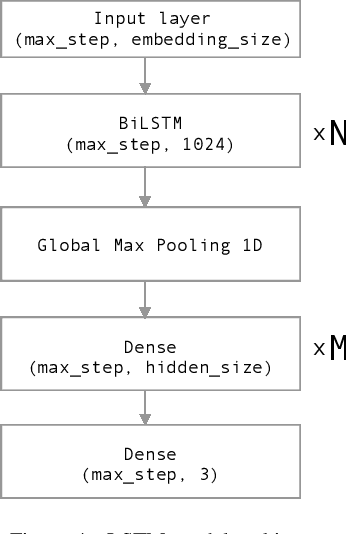
Nowadays, Social network sites (SNSs) such as Facebook, Twitter are common places where people show their opinions, sentiments and share information with others. However, some people use SNSs to post abuse and harassment threats in order to prevent other SNSs users from expressing themselves as well as seeking different opinions. To deal with this problem, SNSs have to use a lot of resources including people to clean the aforementioned content. In this paper, we propose a supervised learning model based on the ensemble method to solve the problem of detecting hate content on SNSs in order to make conversations on SNSs more effective. Our proposed model got the first place for public dashboard with 0.730 F1 macro-score and the third place with 0.584 F1 macro-score for private dashboard at the sixth international workshop on Vietnamese Language and Speech Processing 2019.
VAIS ASR: Building a conversational speech recognition system using language model combination
Oct 12, 2019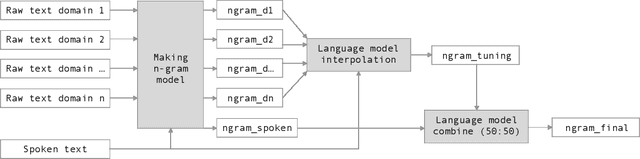

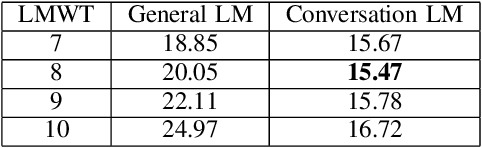
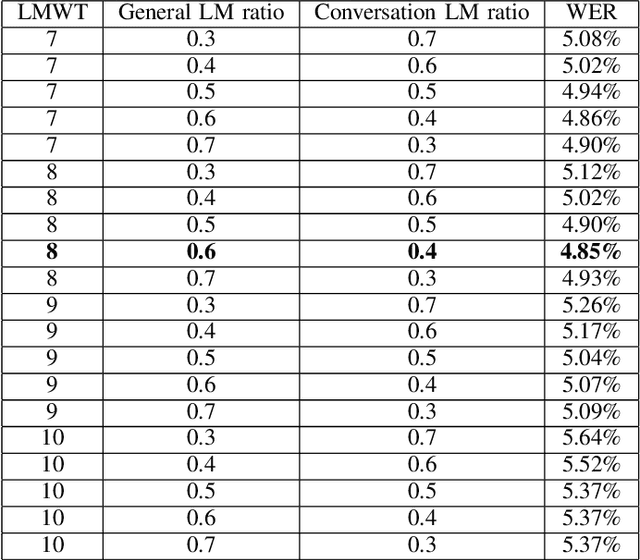
Automatic Speech Recognition (ASR) systems have been evolving quickly and reaching human parity in certain cases. The systems usually perform pretty well on reading style and clean speech, however, most of the available systems suffer from situation where the speaking style is conversation and in noisy environments. It is not straight-forward to tackle such problems due to difficulties in data collection for both speech and text. In this paper, we attempt to mitigate the problems using language models combination techniques that allows us to utilize both large amount of writing style text and small number of conversation text data. Evaluation on the VLSP 2019 ASR challenges showed that our system achieved 4.85% WER on the VLSP 2018 and 15.09% WER on the VLSP 2019 data sets.