 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.
Face-Dubbing++: Lip-Synchronous, Voice Preserving Translation of Videos
Jun 09, 2022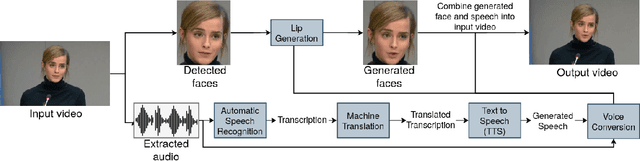
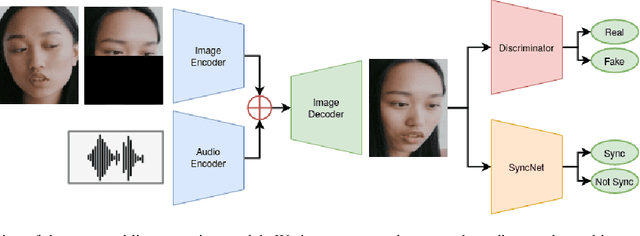
In this paper, we propose a neural end-to-end system for voice preserving, lip-synchronous translation of videos. The system is designed to combine multiple component models and produces a video of the original speaker speaking in the target language that is lip-synchronous with the target speech, yet maintains emphases in speech, voice characteristics, face video of the original speaker. The pipeline starts with automatic speech recognition including emphasis detection, followed by a translation model. The translated text is then synthesized by a Text-to-Speech model that recreates the original emphases mapped from the original sentence. The resulting synthetic voice is then mapped back to the original speakers' voice using a voice conversion model. Finally, to synchronize the lips of the speaker with the translated audio, a conditional generative adversarial network-based model generates frames of adapted lip movements with respect to the input face image as well as the output of the voice conversion model. In the end, the system combines the generated video with the converted audio to produce the final output. The result is a video of a speaker speaking in another language without actually knowing it. To evaluate our design, we present a user study of the complete system as well as separate evaluations of the single components. Since there is no available dataset to evaluate our whole system, we collect a test set and evaluate our system on this test set. The results indicate that our system is able to generate convincing videos of the original speaker speaking the target language while preserving the original speaker's characteristics. The collected dataset will be shared.
Error-correction and extraction in request dialogs
Apr 08, 2020



We propose a component that gets a request and a correction and outputs a corrected request. To get this corrected request, the entities in the correction phrase replace their corresponding entities in the request. In addition, the proposed component outputs these pairs of corresponding reparandum and repair entity. These entity pairs can be used, for example, for learning in a life-long learning component of a dialog system to reduce the need for correction in future dialogs. For the approach described in this work, we fine-tune BERT for sequence labeling. We created a dataset to evaluate our component; for which we got an accuracy of 93.28 %. An accuracy of 88.58 % has been achieved for out-of-domain data. This accuracy shows that the proposed component is learning the concept of corrections and can be developed to be used as an upstream component to avoid the need for collecting data for request corrections for every new domain.
An Interactive Indoor Drone Assistant
Dec 09, 2019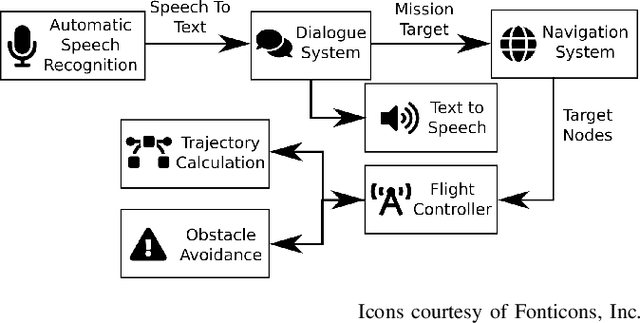

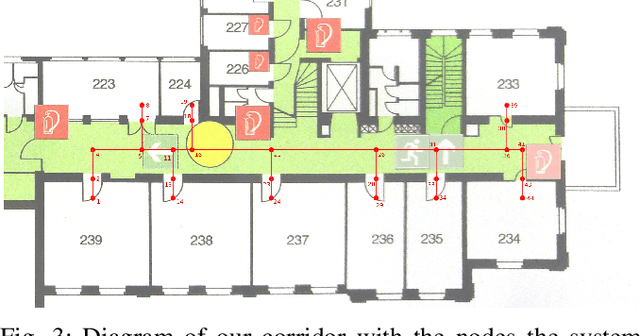
With the rapid advance of sophisticated control algorithms, the capabilities of drones to stabilise, fly and manoeuvre autonomously have dramatically improved, enabling us to pay greater attention to entire missions and the interaction of a drone with humans and with its environment during the course of such a mission. In this paper, we present an indoor office drone assistant that is tasked to run errands and carry out simple tasks at our laboratory, while given instructions from and interacting with humans in the space. To accomplish its mission, the system has to be able to understand verbal instructions from humans, and perform subject to constraints from control and hardware limitations, uncertain localisation information, unpredictable and uncertain obstacles and environmental factors. We combine and evaluate the dialogue, navigation, flight control, depth perception and collision avoidance components. We discuss performance and limitations of our assistant at the component as well as the mission level. A 78% mission success rate was obtained over the course of 27 missions.
Bimodal Speech Emotion Recognition Using Pre-Trained Language Models
Nov 29, 2019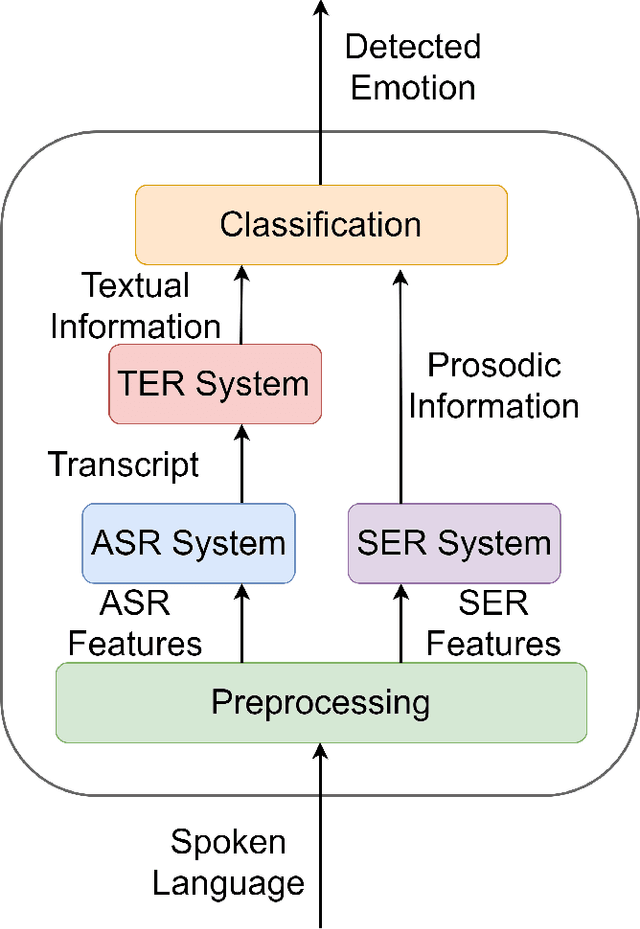
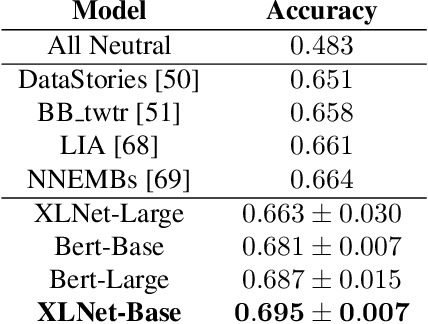

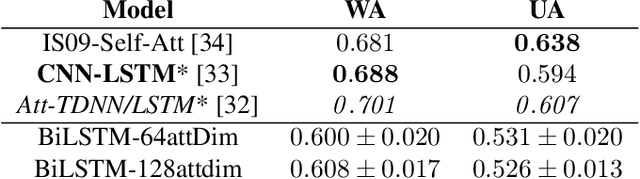
Speech emotion recognition is a challenging task and an important step towards more natural human-machine interaction. We show that pre-trained language models can be fine-tuned for text emotion recognition, achieving an accuracy of 69.5% on Task 4A of SemEval 2017, improving upon the previous state of the art by over 3% absolute. We combine these language models with speech emotion recognition, achieving results of 73.5% accuracy when using provided transcriptions and speech data on a subset of four classes of the IEMOCAP dataset. The use of noise-induced transcriptions and speech data results in an accuracy of 71.4%. For our experiments, we created IEmoNet, a modular and adaptable bimodal framework for speech emotion recognition based on pre-trained language models. Lastly, we discuss the idea of using an emotional classifier as a reward for reinforcement learning as a step towards more successful and convenient human-machine interaction.
Incremental processing of noisy user utterances in the spoken language understanding task
Sep 30, 2019
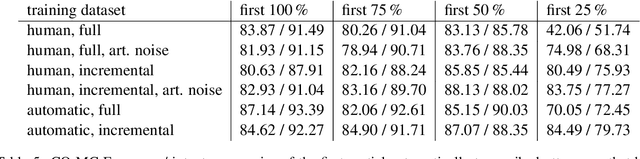
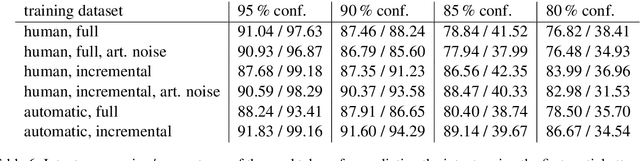
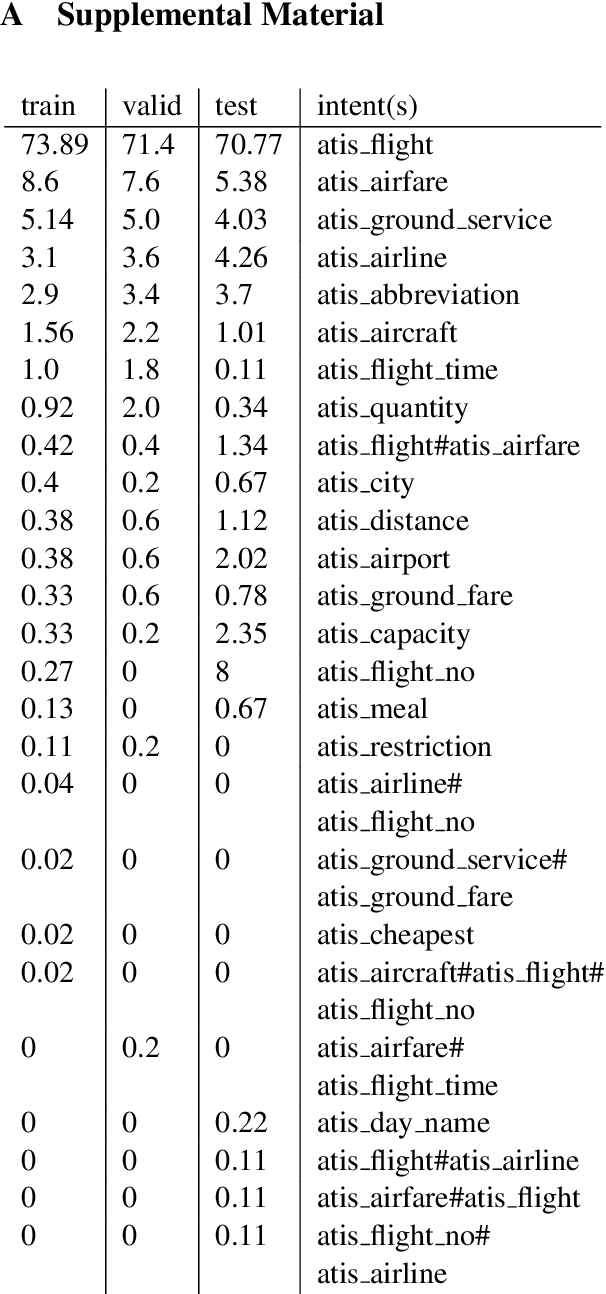
The state-of-the-art neural network architectures make it possible to create spoken language understanding systems with high quality and fast processing time. One major challenge for real-world applications is the high latency of these systems caused by triggered actions with high executions times. If an action can be separated into subactions, the reaction time of the systems can be improved through incremental processing of the user utterance and starting subactions while the utterance is still being uttered. In this work, we present a model-agnostic method to achieve high quality in processing incrementally produced partial utterances. Based on clean and noisy versions of the ATIS dataset, we show how to create datasets with our method to create low-latency natural language understanding components. We get improvements of up to 47.91 absolute percentage points in the metric F1-score.
Multi-task learning to improve natural language understanding
Dec 17, 2018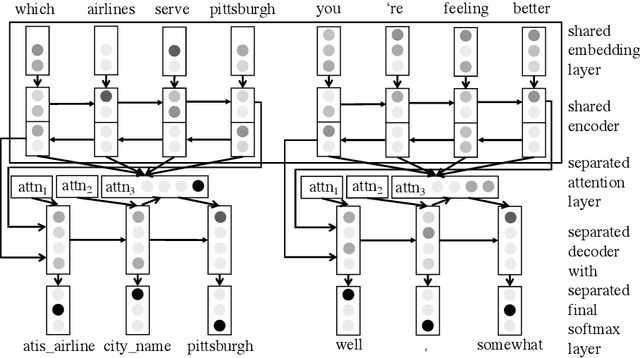
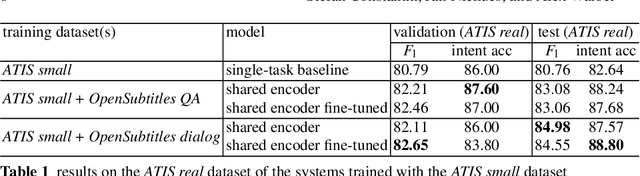

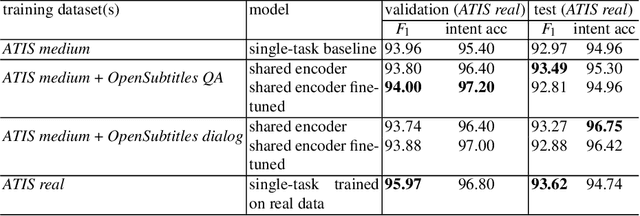
Recently advancements in sequence-to-sequence neural network architectures have led to an improved natural language understanding. When building a neural network-based Natural Language Understanding component, one main challenge is to collect enough training data. The generation of a synthetic dataset is an inexpensive and quick way to collect data. Since this data often has less variety than real natural language, neural networks often have problems to generalize to unseen utterances during testing. In this work, we address this challenge by using multi-task learning. We train out-of-domain real data alongside in-domain synthetic data to improve natural language understanding. We evaluate this approach in the domain of airline travel information with two synthetic datasets. As out-of-domain real data, we test two datasets based on the subtitles of movies and series. By using an attention-based encoder-decoder model, we were able to improve the F1-score over strong baselines from 80.76 % to 84.98 % in the smaller synthetic dataset.
An End-to-End Goal-Oriented Dialog System with a Generative Natural Language Response Generation
Mar 15, 2018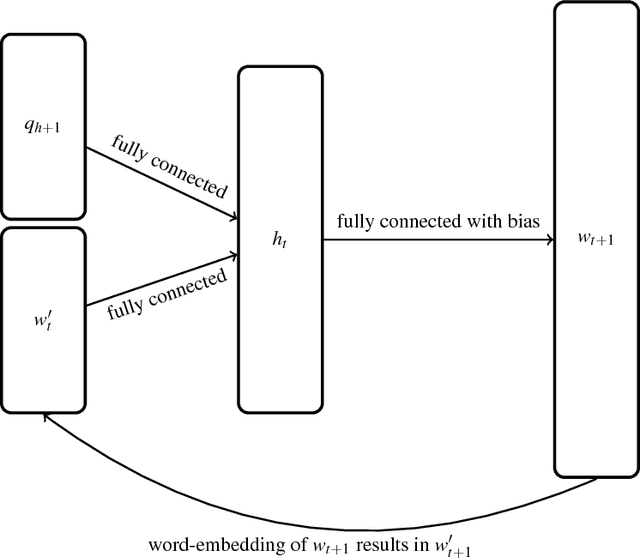
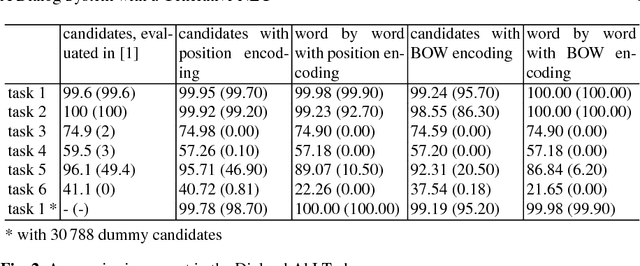

Recently advancements in deep learning allowed the development of end-to-end trained goal-oriented dialog systems. Although these systems already achieve good performance, some simplifications limit their usage in real-life scenarios. In this work, we address two of these limitations: ignoring positional information and a fixed number of possible response candidates. We propose to use positional encodings in the input to model the word order of the user utterances. Furthermore, by using a feedforward neural network, we are able to generate the output word by word and are no longer restricted to a fixed number of possible response candidates. Using the positional encoding, we were able to achieve better accuracies in the Dialog bAbI Tasks and using the feedforward neural network for generating the response, we were able to save computation time and space consumption.