 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Computer Vision based Human Analysis in the COVID-19 Era
Nov 07, 2022



The emergence of COVID-19 has had a global and profound impact, not only on society as a whole, but also on the lives of individuals. Various prevention measures were introduced around the world to limit the transmission of the disease, including face masks, mandates for social distancing and regular disinfection in public spaces, and the use of screening applications. These developments also triggered the need for novel and improved computer vision techniques capable of (i) providing support to the prevention measures through an automated analysis of visual data, on the one hand, and (ii) facilitating normal operation of existing vision-based services, such as biometric authentication schemes, on the other. Especially important here, are computer vision techniques that focus on the analysis of people and faces in visual data and have been affected the most by the partial occlusions introduced by the mandates for facial masks. Such computer vision based human analysis techniques include face and face-mask detection approaches, face recognition techniques, crowd counting solutions, age and expression estimation procedures, models for detecting face-hand interactions and many others, and have seen considerable attention over recent years. The goal of this survey is to provide an introduction to the problems induced by COVID-19 into such research and to present a comprehensive review of the work done in the computer vision based human analysis field. Particular attention is paid to the impact of facial masks on the performance of various methods and recent solutions to mitigate this problem. Additionally, a detailed review of existing datasets useful for the development and evaluation of methods for COVID-19 related applications is also provided. Finally, to help advance the field further, a discussion on the main open challenges and future research direction is given.
Bias-Aware Face Mask Detection Dataset
Nov 02, 2022In December 2019, a novel coronavirus (COVID-19) spread so quickly around the world that many countries had to set mandatory face mask rules in public areas to reduce the transmission of the virus. To monitor public adherence, researchers aimed to rapidly develop efficient systems that can detect faces with masks automatically. However, the lack of representative and novel datasets proved to be the biggest challenge. Early attempts to collect face mask datasets did not account for potential race, gender, and age biases. Therefore, the resulting models show inherent biases toward specific race groups, such as Asian or Caucasian. In this work, we present a novel face mask detection dataset that contains images posted on Twitter during the pandemic from around the world. Unlike previous datasets, the proposed Bias-Aware Face Mask Detection (BAFMD) dataset contains more images from underrepresented race and age groups to mitigate the problem for the face mask detection task. We perform experiments to investigate potential biases in widely used face mask detection datasets and illustrate that the BAFMD dataset yields models with better performance and generalization ability. The dataset is publicly available at https://github.com/Alpkant/BAFMD.
Face-Dubbing++: Lip-Synchronous, Voice Preserving Translation of Videos
Jun 09, 2022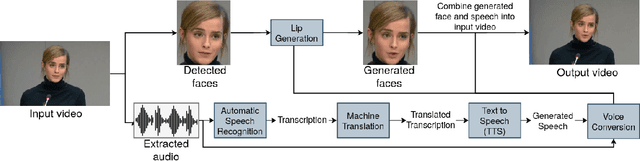
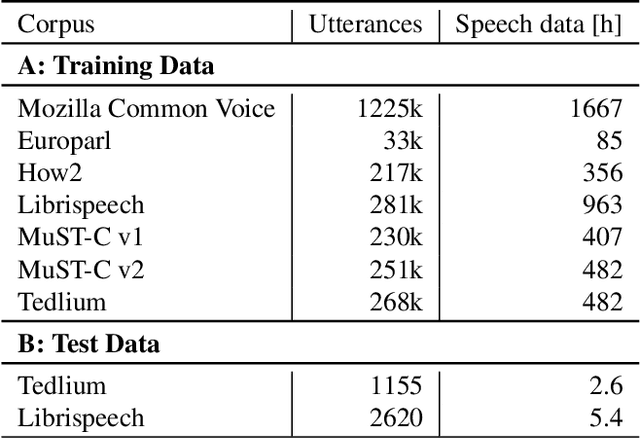
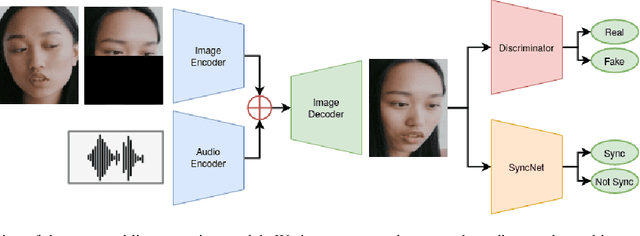
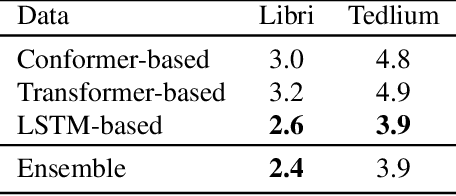
In this paper, we propose a neural end-to-end system for voice preserving, lip-synchronous translation of videos. The system is designed to combine multiple component models and produces a video of the original speaker speaking in the target language that is lip-synchronous with the target speech, yet maintains emphases in speech, voice characteristics, face video of the original speaker. The pipeline starts with automatic speech recognition including emphasis detection, followed by a translation model. The translated text is then synthesized by a Text-to-Speech model that recreates the original emphases mapped from the original sentence. The resulting synthetic voice is then mapped back to the original speakers' voice using a voice conversion model. Finally, to synchronize the lips of the speaker with the translated audio, a conditional generative adversarial network-based model generates frames of adapted lip movements with respect to the input face image as well as the output of the voice conversion model. In the end, the system combines the generated video with the converted audio to produce the final output. The result is a video of a speaker speaking in another language without actually knowing it. To evaluate our design, we present a user study of the complete system as well as separate evaluations of the single components. Since there is no available dataset to evaluate our whole system, we collect a test set and evaluate our system on this test set. The results indicate that our system is able to generate convincing videos of the original speaker speaking the target language while preserving the original speaker's characteristics. The collected dataset will be shared.
Shuffled Patch-Wise Supervision for Presentation Attack Detection
Sep 09, 2021


Face anti-spoofing is essential to prevent false facial verification by using a photo, video, mask, or a different substitute for an authorized person's face. Most of the state-of-the-art presentation attack detection (PAD) systems suffer from overfitting, where they achieve near-perfect scores on a single dataset but fail on a different dataset with more realistic data. This problem drives researchers to develop models that perform well under real-world conditions. This is an especially challenging problem for frame-based presentation attack detection systems that use convolutional neural networks (CNN). To this end, we propose a new PAD approach, which combines pixel-wise binary supervision with patch-based CNN. We believe that training a CNN with face patches allows the model to distinguish spoofs without learning background or dataset-specific traces. We tested the proposed method both on the standard benchmark datasets -- Replay-Mobile, OULU-NPU -- and on a real-world dataset. The proposed approach shows its superiority on challenging experimental setups. Namely, it achieves higher performance on OULU-NPU protocol 3, 4 and on inter-dataset real-world experiments.
Offline Signature Verification on Real-World Documents
Apr 25, 2020
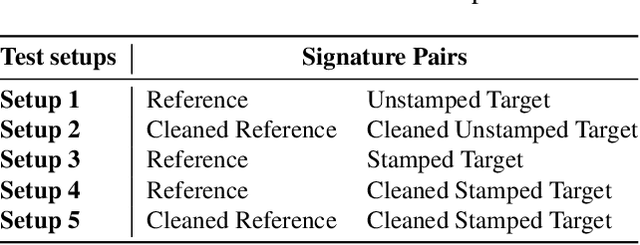

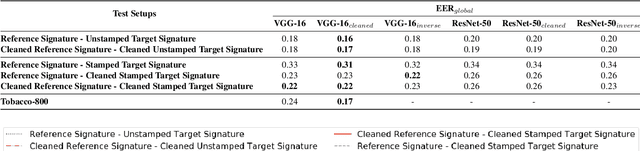
Research on offline signature verification has explored a large variety of methods on multiple signature datasets, which are collected under controlled conditions. However, these datasets may not fully reflect the characteristics of the signatures in some practical use cases. Real-world signatures extracted from the formal documents may contain different types of occlusions, for example, stamps, company seals, ruling lines, and signature boxes. Moreover, they may have very high intra-class variations, where even genuine signatures resemble forgeries. In this paper, we address a real-world writer independent offline signature verification problem, in which, a bank's customers' transaction request documents that contain their occluded signatures are compared with their clean reference signatures. Our proposed method consists of two main components, a stamp cleaning method based on CycleGAN and signature representation based on CNNs. We extensively evaluate different verification setups, fine-tuning strategies, and signature representation approaches to have a thorough analysis of the problem. Moreover, we conduct a human evaluation to show the challenging nature of the problem. We run experiments both on our custom dataset, as well as on the publicly available Tobacco-800 dataset. The experimental results validate the difficulty of offline signature verification on real-world documents. However, by employing the stamp cleaning process, we improve the signature verification performance significantly.
Thermal to Visible Face Recognition Using Deep Autoencoders
Feb 10, 2020



Visible face recognition systems achieve nearly perfect recognition accuracies using deep learning. However, in lack of light, these systems perform poorly. A way to deal with this problem is thermal to visible cross-domain face matching. This is a desired technology because of its usefulness in night time surveillance. Nevertheless, due to differences between two domains, it is a very challenging face recognition problem. In this paper, we present a deep autoencoder based system to learn the mapping between visible and thermal face images. Also, we assess the impact of alignment in thermal to visible face recognition. For this purpose, we manually annotate the facial landmarks on the Carl and EURECOM datasets. The proposed approach is extensively tested on three publicly available datasets: Carl, UND-X1, and EURECOM. Experimental results show that the proposed approach improves the state-of-the-art significantly. We observe that alignment increases the performance by around 2%. Annotated facial landmark positions in this study can be downloaded from the following link: github.com/Alpkant/Thermal-to-Visible-Face-Recognition-Using-Deep-Autoencoders .