 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKIT's Low-resource Speech Translation Systems for IWSLT2025: System Enhancement with Synthetic Data and Model Regularization
May 26, 2025This paper presents KIT's submissions to the IWSLT 2025 low-resource track. We develop both cascaded systems, consisting of Automatic Speech Recognition (ASR) and Machine Translation (MT) models, and end-to-end (E2E) Speech Translation (ST) systems for three language pairs: Bemba, North Levantine Arabic, and Tunisian Arabic into English. Building upon pre-trained models, we fine-tune our systems with different strategies to utilize resources efficiently. This study further explores system enhancement with synthetic data and model regularization. Specifically, we investigate MT-augmented ST by generating translations from ASR data using MT models. For North Levantine, which lacks parallel ST training data, a system trained solely on synthetic data slightly surpasses the cascaded system trained on real data. We also explore augmentation using text-to-speech models by generating synthetic speech from MT data, demonstrating the benefits of synthetic data in improving both ASR and ST performance for Bemba. Additionally, we apply intra-distillation to enhance model performance. Our experiments show that this approach consistently improves results across ASR, MT, and ST tasks, as well as across different pre-trained models. Finally, we apply Minimum Bayes Risk decoding to combine the cascaded and end-to-end systems, achieving an improvement of approximately 1.5 BLEU points.
Predictive Speech Recognition and End-of-Utterance Detection Towards Spoken Dialog Systems
Sep 30, 2024
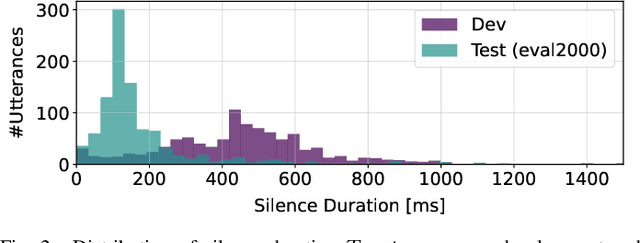
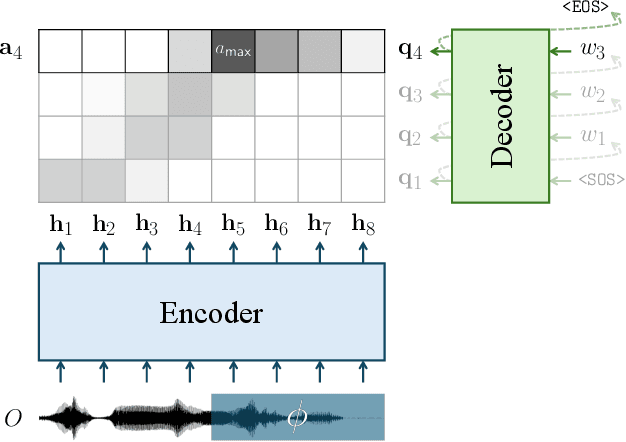
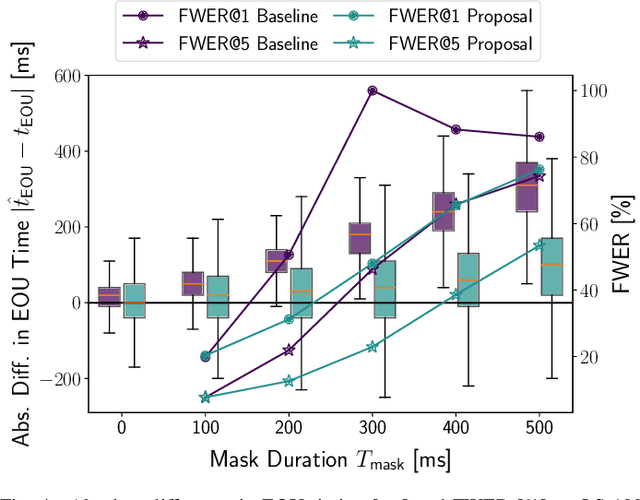
Effective spoken dialog systems should facilitate natural interactions with quick and rhythmic timing, mirroring human communication patterns. To reduce response times, previous efforts have focused on minimizing the latency in automatic speech recognition (ASR) to optimize system efficiency. However, this approach requires waiting for ASR to complete processing until a speaker has finished speaking, which limits the time available for natural language processing (NLP) to formulate accurate responses. As humans, we continuously anticipate and prepare responses even while the other party is still speaking. This allows us to respond appropriately without missing the optimal time to speak. In this work, as a pioneering study toward a conversational system that simulates such human anticipatory behavior, we aim to realize a function that can predict the forthcoming words and estimate the time remaining until the end of an utterance (EOU), using the middle portion of an utterance. To achieve this, we propose a training strategy for an encoder-decoder-based ASR system, which involves masking future segments of an utterance and prompting the decoder to predict the words in the masked audio. Additionally, we develop a cross-attention-based algorithm that incorporates both acoustic and linguistic information to accurately detect the EOU. The experimental results demonstrate the proposed model's ability to predict upcoming words and estimate future EOU events up to 300ms prior to the actual EOU. Moreover, the proposed training strategy exhibits general improvements in ASR performance.
Decoupled Vocabulary Learning Enables Zero-Shot Translation from Unseen Languages
Aug 05, 2024
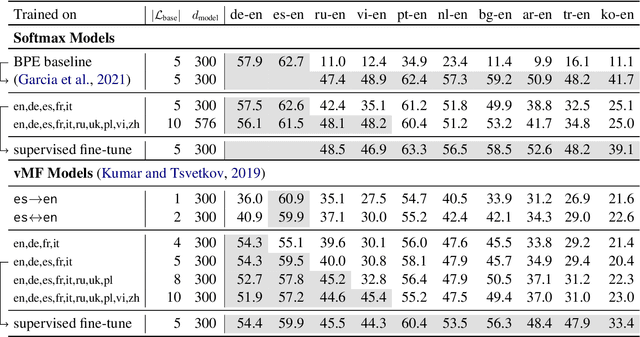

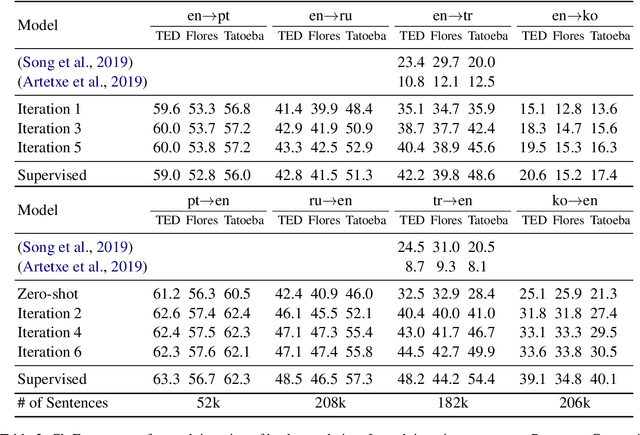
Multilingual neural machine translation systems learn to map sentences of different languages into a common representation space. Intuitively, with a growing number of seen languages the encoder sentence representation grows more flexible and easily adaptable to new languages. In this work, we test this hypothesis by zero-shot translating from unseen languages. To deal with unknown vocabularies from unknown languages we propose a setup where we decouple learning of vocabulary and syntax, i.e. for each language we learn word representations in a separate step (using cross-lingual word embeddings), and then train to translate while keeping those word representations frozen. We demonstrate that this setup enables zero-shot translation from entirely unseen languages. Zero-shot translating with a model trained on Germanic and Romance languages we achieve scores of 42.6 BLEU for Portuguese-English and 20.7 BLEU for Russian-English on TED domain. We explore how this zero-shot translation capability develops with varying number of languages seen by the encoder. Lastly, we explore the effectiveness of our decoupled learning strategy for unsupervised machine translation. By exploiting our model's zero-shot translation capability for iterative back-translation we attain near parity with a supervised setting.
SciEx: Benchmarking Large Language Models on Scientific Exams with Human Expert Grading and Automatic Grading
Jun 14, 2024
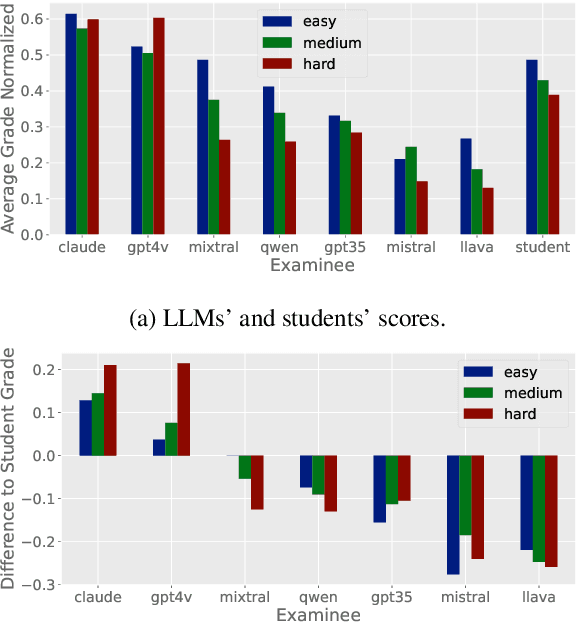

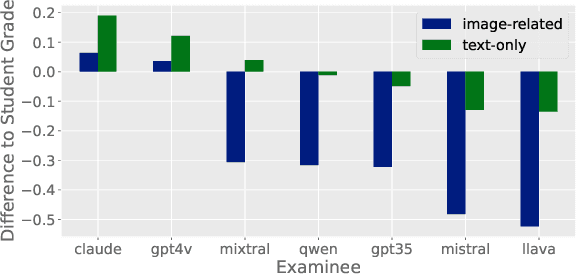
With the rapid development of Large Language Models (LLMs), it is crucial to have benchmarks which can evaluate the ability of LLMs on different domains. One common use of LLMs is performing tasks on scientific topics, such as writing algorithms, querying databases or giving mathematical proofs. Inspired by the way university students are evaluated on such tasks, in this paper, we propose SciEx - a benchmark consisting of university computer science exam questions, to evaluate LLMs ability on solving scientific tasks. SciEx is (1) multilingual, containing both English and German exams, and (2) multi-modal, containing questions that involve images, and (3) contains various types of freeform questions with different difficulty levels, due to the nature of university exams. We evaluate the performance of various state-of-the-art LLMs on our new benchmark. Since SciEx questions are freeform, it is not straightforward to evaluate LLM performance. Therefore, we provide human expert grading of the LLM outputs on SciEx. We show that the free-form exams in SciEx remain challenging for the current LLMs, where the best LLM only achieves 59.4\% exam grade on average. We also provide detailed comparisons between LLM performance and student performance on SciEx. To enable future evaluation of new LLMs, we propose using LLM-as-a-judge to grade the LLM answers on SciEx. Our experiments show that, although they do not perform perfectly on solving the exams, LLMs are decent as graders, achieving 0.948 Pearson correlation with expert grading.
End-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.
KIT's Multilingual Speech Translation System for IWSLT 2023
Jun 15, 2023



Many existing speech translation benchmarks focus on native-English speech in high-quality recording conditions, which often do not match the conditions in real-life use-cases. In this paper, we describe our speech translation system for the multilingual track of IWSLT 2023, which evaluates translation quality on scientific conference talks. The test condition features accented input speech and terminology-dense contents. The task requires translation into 10 languages of varying amounts of resources. In absence of training data from the target domain, we use a retrieval-based approach (kNN-MT) for effective adaptation (+0.8 BLEU for speech translation). We also use adapters to easily integrate incremental training data from data augmentation, and show that it matches the performance of re-training. We observe that cascaded systems are more easily adaptable towards specific target domains, due to their separate modules. Our cascaded speech system substantially outperforms its end-to-end counterpart on scientific talk translation, although their performance remains similar on TED talks.
Face-Dubbing++: Lip-Synchronous, Voice Preserving Translation of Videos
Jun 09, 2022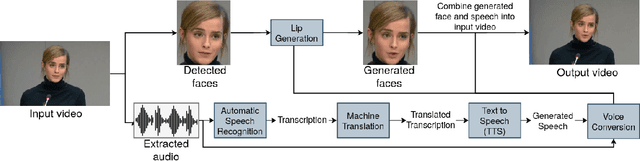
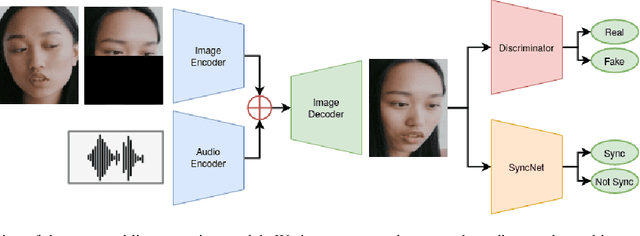
In this paper, we propose a neural end-to-end system for voice preserving, lip-synchronous translation of videos. The system is designed to combine multiple component models and produces a video of the original speaker speaking in the target language that is lip-synchronous with the target speech, yet maintains emphases in speech, voice characteristics, face video of the original speaker. The pipeline starts with automatic speech recognition including emphasis detection, followed by a translation model. The translated text is then synthesized by a Text-to-Speech model that recreates the original emphases mapped from the original sentence. The resulting synthetic voice is then mapped back to the original speakers' voice using a voice conversion model. Finally, to synchronize the lips of the speaker with the translated audio, a conditional generative adversarial network-based model generates frames of adapted lip movements with respect to the input face image as well as the output of the voice conversion model. In the end, the system combines the generated video with the converted audio to produce the final output. The result is a video of a speaker speaking in another language without actually knowing it. To evaluate our design, we present a user study of the complete system as well as separate evaluations of the single components. Since there is no available dataset to evaluate our whole system, we collect a test set and evaluate our system on this test set. The results indicate that our system is able to generate convincing videos of the original speaker speaking the target language while preserving the original speaker's characteristics. The collected dataset will be shared.
CUNI-KIT System for Simultaneous Speech Translation Task at IWSLT 2022
Apr 12, 2022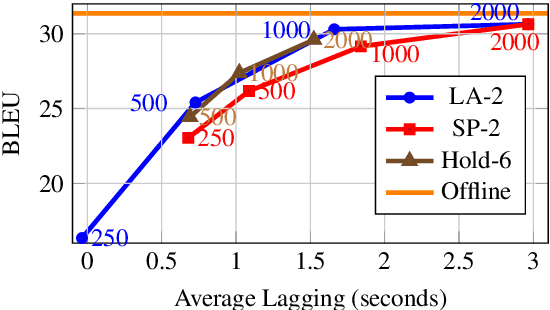
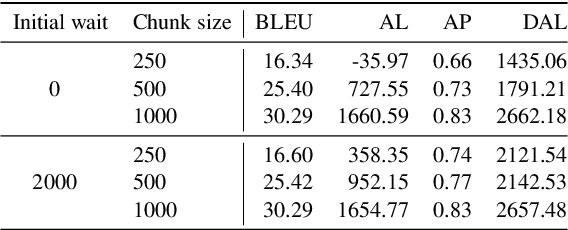
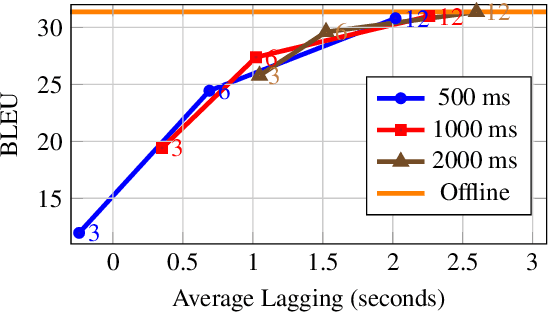
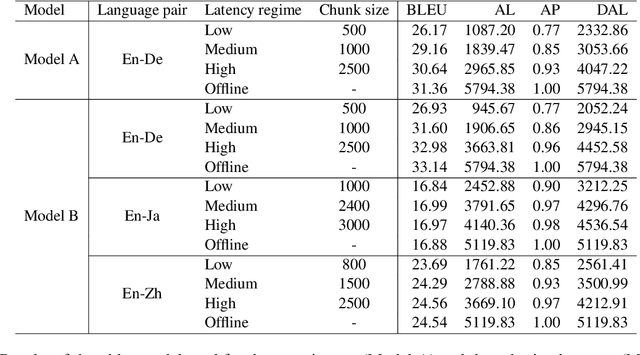
In this paper, we describe our submission to the Simultaneous Speech Translation at IWSLT 2022. We explore strategies to utilize an offline model in a simultaneous setting without the need to modify the original model. In our experiments, we show that our onlinization algorithm is almost on par with the offline setting while being 3x faster than offline in terms of latency on the test set. We make our system publicly available.
Unsupervised Transfer Learning in Multilingual Neural Machine Translation with Cross-Lingual Word Embeddings
Mar 11, 2021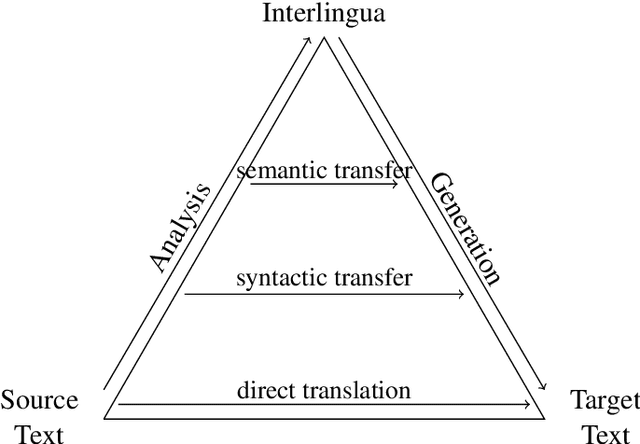
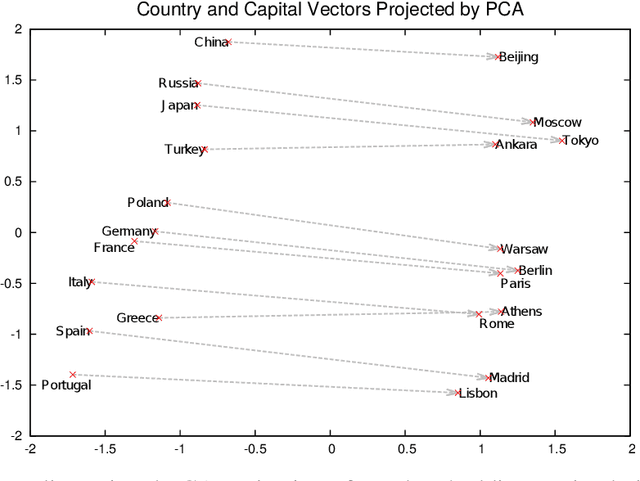
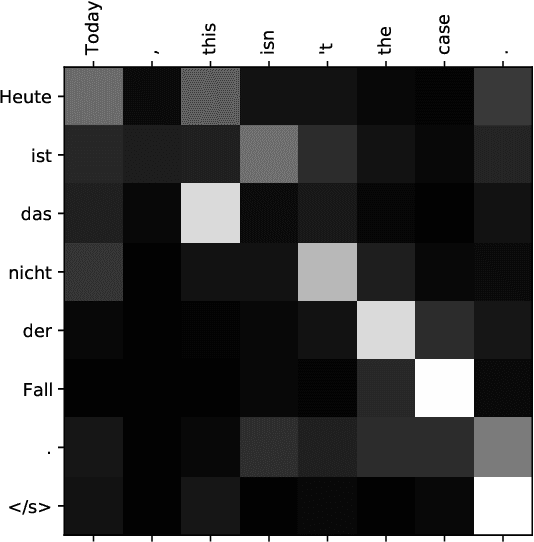
In this work we look into adding a new language to a multilingual NMT system in an unsupervised fashion. Under the utilization of pre-trained cross-lingual word embeddings we seek to exploit a language independent multilingual sentence representation to easily generalize to a new language. While using cross-lingual embeddings for word lookup we decode from a yet entirely unseen source language in a process we call blind decoding. Blindly decoding from Portuguese using a basesystem containing several Romance languages we achieve scores of 36.4 BLEU for Portuguese-English and 12.8 BLEU for Russian-English. In an attempt to train the mapping from the encoder sentence representation to a new target language we use our model as an autoencoder. Merely training to translate from Portuguese to Portuguese while freezing the encoder we achieve 26 BLEU on English-Portuguese, and up to 28 BLEU when adding artificial noise to the input. Lastly we explore a more practical adaptation approach through non-iterative backtranslation, exploiting our model's ability to produce high quality translations through blind decoding. This yields us up to 34.6 BLEU on English-Portuguese, attaining near parity with a model adapted on real bilingual data.