 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciEx: Benchmarking Large Language Models on Scientific Exams with Human Expert Grading and Automatic Grading
Paper and Code

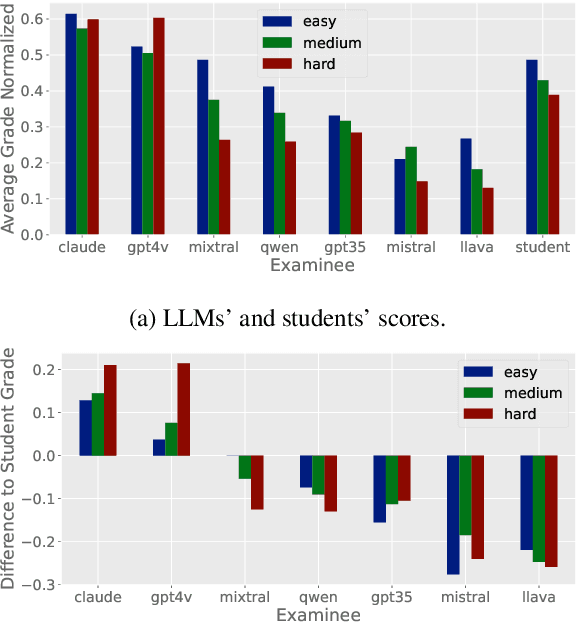

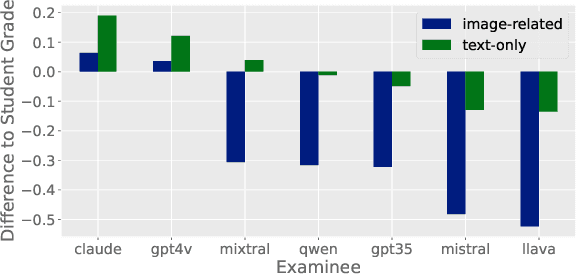
With the rapid development of Large Language Models (LLMs), it is crucial to have benchmarks which can evaluate the ability of LLMs on different domains. One common use of LLMs is performing tasks on scientific topics, such as writing algorithms, querying databases or giving mathematical proofs. Inspired by the way university students are evaluated on such tasks, in this paper, we propose SciEx - a benchmark consisting of university computer science exam questions, to evaluate LLMs ability on solving scientific tasks. SciEx is (1) multilingual, containing both English and German exams, and (2) multi-modal, containing questions that involve images, and (3) contains various types of freeform questions with different difficulty levels, due to the nature of university exams. We evaluate the performance of various state-of-the-art LLMs on our new benchmark. Since SciEx questions are freeform, it is not straightforward to evaluate LLM performance. Therefore, we provide human expert grading of the LLM outputs on SciEx. We show that the free-form exams in SciEx remain challenging for the current LLMs, where the best LLM only achieves 59.4\% exam grade on average. We also provide detailed comparisons between LLM performance and student performance on SciEx. To enable future evaluation of new LLMs, we propose using LLM-as-a-judge to grade the LLM answers on SciEx. Our experiments show that, although they do not perform perfectly on solving the exams, LLMs are decent as graders, achieving 0.948 Pearson correlation with expert grading.