 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuo Vadis, Visual In-Context Learning? A Unified Benchmark Across Domains and Tasks
Jun 09, 2026Visual in-context learning has been proposed as a pathway towards dynamic models that can generate predictions based on a provided context and thereby can adapt to new vision tasks at test-time. Yet, the evaluation of the adaptation capabilities of these models has been limited to narrow setups that mainly mirror tasks or image domains from pre-training for which real adaptation is not required. We address this gap by constructing a broad Visual In-Context BEnchmark (VIBE) with a focus on diverse imaging domains and a wide range of tasks. With this, we are able to get a much clearer picture of the adaptive capabilities of visual in-context models when faced with new image- and task distributions. We stress test six models on $14$ datasets and $12$ tasks (in total, we explore $106$ dataset-task combinations) and compare them under a unified, reproducible evaluation protocol, in an one-shot setting. Our evaluation uncovers key insights on the state of visual in-context learning, including limitations, systematic failure modes and promising directions. To foster broader evaluation, we will openly release our VIBE toolkit.
Beyond Model Size: Probing the Gaps in Visual in-Context Learning by Training a Tiny Model
Jun 09, 2026Visual in-Context Learning (VICL) aims at making progress towards adaptive vision models, that can -- based on a few examples -- adapt to a new task at test-time. With the history of in-context learning in natural language processing research, where large, parameter-heavy models are in use, one pathway that current VICL methods take is model- and data-scaling as key ingredients. Yet, it is not clear, whether these ingredients are the key for in-context learning to take shape in vision models. To stress-test such large models, we challenge them with an extreme counterexample: we train a tiny visual in-context model with merely $1$ million parameters and a modest amount of $70,000$ images. We compare the results of this severely capacity capped tiny model to $7,000\times$ larger VICL models in different adaptive settings, (1) on image data with small distribution shifts, (2) on unseen task encodings and (3) on a completely new task, i.e., the setting VICL envisions. With the chasm of training resources between the tiny- and large models, our experiments showcase a lack in how adaptive capabilities are measured, with respect to how tasks are encoded, which tasks were used in pre-training and the choice of metrics. These gaps in current VICL benchmarking underscore a need for innovation in evaluation of adaptive capabilities.
From Static to Interactive: Adapting Visual in-Context Learners for User-Driven Tasks
Apr 08, 2026Visual in-context learning models are designed to adapt to new tasks by leveraging a set of example input-output pairs, enabling rapid generalization without task-specific fine-tuning. However, these models operate in a fundamentally static paradigm: while they can adapt to new tasks, they lack any mechanism to incorporate user-provided guidance signals such as scribbles, clicks, or bounding boxes to steer or refine the prediction process. This limitation is particularly restrictive in real-world applications, where users want to actively guide model predictions, e.g., by highlighting the target object for segmentation, indicating a region which should be visually altered, or isolating a specific person in a complex scene to run targeted pose estimation. In this work, we propose a simple method to transform static visual in-context learners, particularly the DeLVM approach, into highly controllable, user-driven systems, i.e., Interactive DeLVM, enabling seamless interaction through natural visual cues such as scribbles, clicks, or drawing boxes. Specifically, by encoding interactions directly into the example input-output pairs, we keep the philosophy of visual in-context learning intact: enabling users to prompt models with unseen interactions without fine-tuning and empowering them to dynamically steer model predictions with personalized interactions. Our experiments demonstrate that SOTA visual in-context learning models fail to effectively leverage interaction cues, often ignoring user guidance entirely. In contrast, our method excels in controllable, user-guided scenarios, achieving improvements of $+7.95%$ IoU for interactive segmentation, $+2.46$ PSNR for directed super-resolution, and $-3.14%$ LPIPS for interactive object removal. With this, our work bridges the gap between rigid static task adaptation and fluid interactivity for user-centric visual in-context learning.
Probing Intrinsic Medical Task Relationships: A Contrastive Learning Perspective
Apr 07, 2026While much of the medical computer vision community has focused on advancing performance for specific tasks, the underlying relationships between tasks, i.e., how they relate, overlap, or differ on a representational level, remain largely unexplored. Our work explores these intrinsic relationships between medical vision tasks, specifically, we investigate 30 tasks, such as semantic tasks (e.g., segmentation and detection), image generative tasks (e.g., denoising, inpainting, or colorization), and image transformation tasks (e.g., geometric transformations). Our goal is to probe whether a data-driven representation space can capture an underlying structure of tasks across a variety of 39 datasets from wildly different medical imaging modalities, including computed tomography, magnetic resonance, electron microscopy, X-ray ultrasound and more. By revealing how tasks relate to one another, we aim to provide insights into their fundamental properties and interconnectedness. To this end, we introduce Task-Contrastive Learning (TaCo), a contrastive learning framework designed to embed tasks into a shared representation space. Through TaCo, we map these heterogeneous tasks from different modalities into a joint space and analyze their properties: identifying which tasks are distinctly represented, which blend together, and how iterative alterations to tasks are reflected in the embedding space. Our work provides a foundation for understanding the intrinsic structure of medical vision tasks, offering a deeper understanding of task similarities and their interconnected properties in embedding spaces.
Semantic Segmentation for Preoperative Planning in Transcatheter Aortic Valve Replacement
Jul 22, 2025When preoperative planning for surgeries is conducted on the basis of medical images, artificial intelligence methods can support medical doctors during assessment. In this work, we consider medical guidelines for preoperative planning of the transcatheter aortic valve replacement (TAVR) and identify tasks, that may be supported via semantic segmentation models by making relevant anatomical structures measurable in computed tomography scans. We first derive fine-grained TAVR-relevant pseudo-labels from coarse-grained anatomical information, in order to train segmentation models and quantify how well they are able to find these structures in the scans. Furthermore, we propose an adaptation to the loss function in training these segmentation models and through this achieve a +1.27% Dice increase in performance. Our fine-grained TAVR-relevant pseudo-labels and the computed tomography scans we build upon are available at https://doi.org/10.5281/zenodo.16274176.
Is Visual in-Context Learning for Compositional Medical Tasks within Reach?
Jul 02, 2025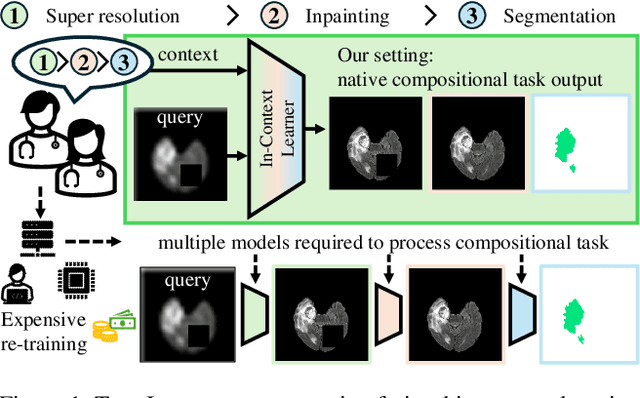
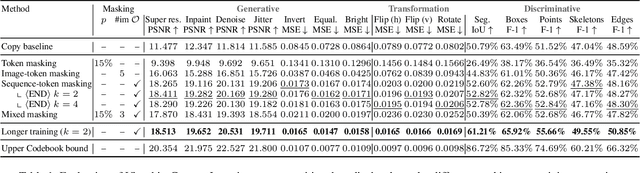
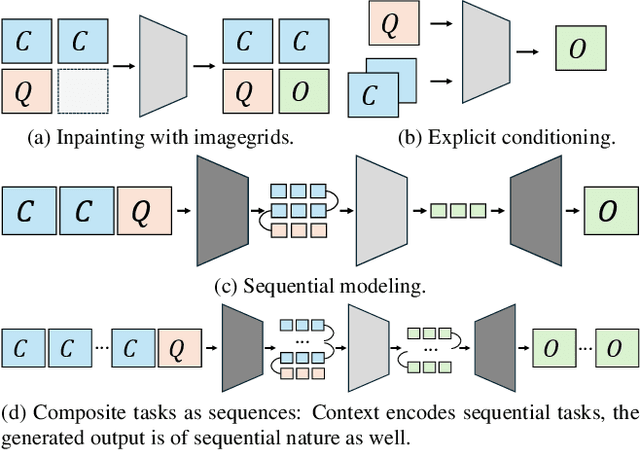
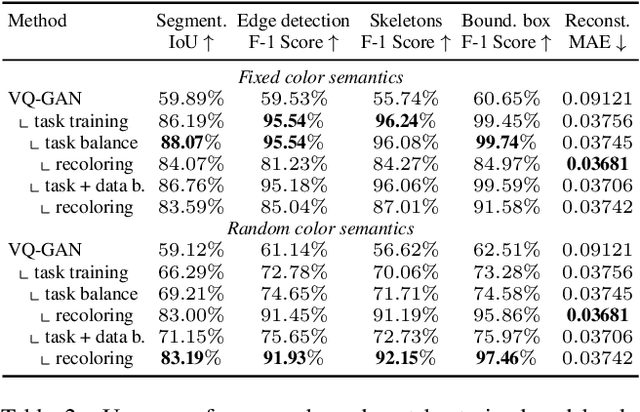
In this paper, we explore the potential of visual in-context learning to enable a single model to handle multiple tasks and adapt to new tasks during test time without re-training. Unlike previous approaches, our focus is on training in-context learners to adapt to sequences of tasks, rather than individual tasks. Our goal is to solve complex tasks that involve multiple intermediate steps using a single model, allowing users to define entire vision pipelines flexibly at test time. To achieve this, we first examine the properties and limitations of visual in-context learning architectures, with a particular focus on the role of codebooks. We then introduce a novel method for training in-context learners using a synthetic compositional task generation engine. This engine bootstraps task sequences from arbitrary segmentation datasets, enabling the training of visual in-context learners for compositional tasks. Additionally, we investigate different masking-based training objectives to gather insights into how to train models better for solving complex, compositional tasks. Our exploration not only provides important insights especially for multi-modal medical task sequences but also highlights challenges that need to be addressed.
Conquering the Retina: Bringing Visual in-Context Learning to OCT
Jun 18, 2025Recent advancements in medical image analysis have led to the development of highly specialized models tailored to specific clinical tasks. These models have demonstrated exceptional performance and remain a crucial research direction. Yet, their applicability is limited to predefined tasks, requiring expertise and extensive resources for development and adaptation. In contrast, generalist models offer a different form of utility: allowing medical practitioners to define tasks on the fly without the need for task-specific model development. In this work, we explore how to train generalist models for the domain of retinal optical coherence tomography using visual in-context learning (VICL), i.e., training models to generalize across tasks based on a few examples provided at inference time. To facilitate rigorous assessment, we propose a broad evaluation protocol tailored to VICL in OCT. We extensively evaluate a state-of-the-art medical VICL approach on multiple retinal OCT datasets, establishing a first baseline to highlight the potential and current limitations of in-context learning for OCT. To foster further research and practical adoption, we openly release our code.
Good Enough: Is it Worth Improving your Label Quality?
May 27, 2025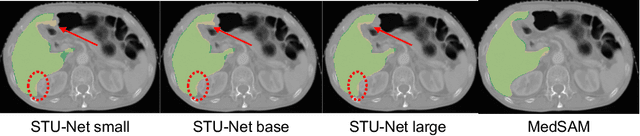
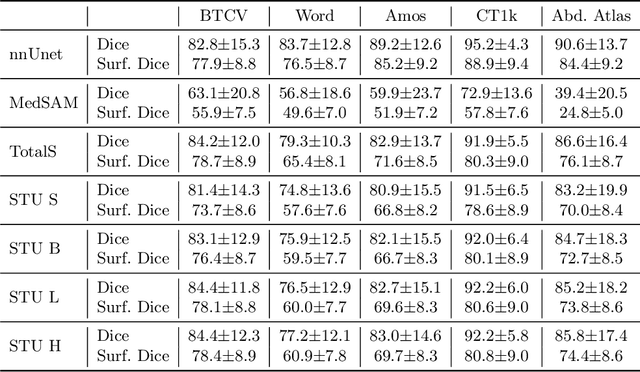
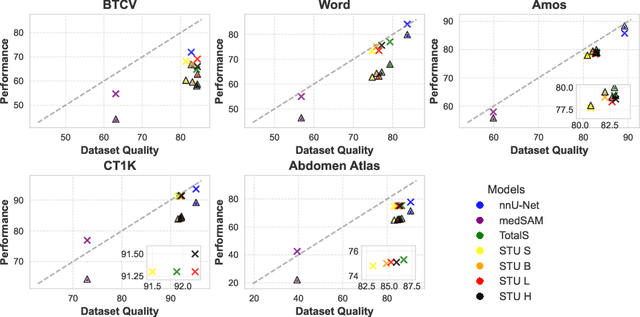
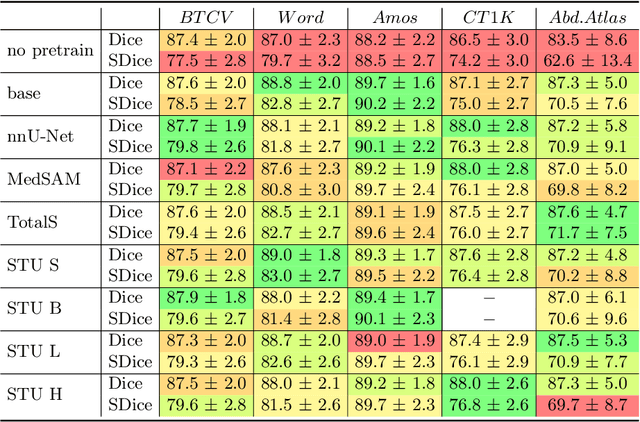
Improving label quality in medical image segmentation is costly, but its benefits remain unclear. We systematically evaluate its impact using multiple pseudo-labeled versions of CT datasets, generated by models like nnU-Net, TotalSegmentator, and MedSAM. Our results show that while higher-quality labels improve in-domain performance, gains remain unclear if below a small threshold. For pre-training, label quality has minimal impact, suggesting that models rather transfer general concepts than detailed annotations. These findings provide guidance on when improving label quality is worth the effort.
CHAOS: Chart Analysis with Outlier Samples
May 22, 2025Charts play a critical role in data analysis and visualization, yet real-world applications often present charts with challenging or noisy features. However, "outlier charts" pose a substantial challenge even for Multimodal Large Language Models (MLLMs), which can struggle to interpret perturbed charts. In this work, we introduce CHAOS (CHart Analysis with Outlier Samples), a robustness benchmark to systematically evaluate MLLMs against chart perturbations. CHAOS encompasses five types of textual and ten types of visual perturbations, each presented at three levels of severity (easy, mid, hard) inspired by the study result of human evaluation. The benchmark includes 13 state-of-the-art MLLMs divided into three groups (i.e., general-, document-, and chart-specific models) according to the training scope and data. Comprehensive analysis involves two downstream tasks (ChartQA and Chart-to-Text). Extensive experiments and case studies highlight critical insights into robustness of models across chart perturbations, aiming to guide future research in chart understanding domain. Data and code are publicly available at: http://huggingface.co/datasets/omoured/CHAOS.
Foreign object segmentation in chest x-rays through anatomy-guided shape insertion
Jan 21, 2025



In this paper, we tackle the challenge of instance segmentation for foreign objects in chest radiographs, commonly seen in postoperative follow-ups with stents, pacemakers, or ingested objects in children. The diversity of foreign objects complicates dense annotation, as shown in insufficient existing datasets. To address this, we propose the simple generation of synthetic data through (1) insertion of arbitrary shapes (lines, polygons, ellipses) with varying contrasts and opacities, and (2) cut-paste augmentations from a small set of semi-automatically extracted labels. These insertions are guided by anatomy labels to ensure realistic placements, such as stents appearing only in relevant vessels. Our approach enables networks to segment complex structures with minimal manually labeled data. Notably, it achieves performance comparable to fully supervised models while using 93\% fewer manual annotations.