 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe autoPET3 Challenge -- Automated Lesion Segmentation in Whole-Body PET/CT - Multitracer Multicenter Generalization
May 07, 2026We report the design and results of the third autoPET challenge (MICCAI 2024), which benchmarked automated lesion segmentation in whole-body PET/CT under a compositional generalization setting. Training data comprised 1,014 [18F]-FDG PET/CT studies from the University Hospital Tübingen and 597 [18F]/[68Ga]-PSMA PET/CT studies from the LMU University Hospital Munich, constituting the largest publicly available annotated PSMA PET/CT dataset to date. The held-out test set of 200 studies covered four tracer-center combinations, two of which represented unseen compositional pairings. A complementary data-centric award category isolated the contribution of data handling strategies by restricting participants to a fixed baseline model. Seventeen teams submitted 27 algorithms, predominantly nnU-Net-based 3D networks with PET/CT channel concatenation. The top-ranked algorithm achieved a mean DSC of 0.66, FNV of 3.18 mL, and FPV of 2.78 mL across all four test conditions, improving DSC by 8% and reducing the false-negative volume by 5 mL relative to the provided baseline. Ranking was stable across bootstrap resampling and alternative ranking schemes for the top tier. Beyond the benchmark, we provide an in-depth analysis of segmentation performance at the patient and lesion level. Three main conclusions can be drawn: (1) in-domain multitracer PET/CT segmentation is sufficient and probably approaching reader agreement; (2) compositional generalization to unseen tracer-center combinations remains an open problem mainly driven by systematic volume overestimation; (3) heterogeneity and case difficulty drive performance variation substantially more than the choice of algorithm among top-ranked teams.
Region-Normalized DPO for Medical Image Segmentation under Noisy Judges
Jan 30, 2026While dense pixel-wise annotations remain the gold standard for medical image segmentation, they are costly to obtain and limit scalability. In contrast, many deployed systems already produce inexpensive automatic quality-control (QC) signals like model agreement, uncertainty measures, or learned mask-quality scores which can be used for further model training without additional ground-truth annotation. However, these signals can be noisy and biased, making preference-based fine-tuning susceptible to harmful updates. We study Direct Preference Optimization (DPO) for segmentation from such noisy judges using proposals generated by a supervised base segmenter trained on a small labeled set. We find that outcomes depend strongly on how preference pairs are mined: selecting the judge's top-ranked proposal can improve peak performance when the judge is reliable, but can amplify harmful errors under weaker judges. We propose Region-Normalized DPO (RN-DPO), a segmentation-aware objective which normalizes preference updates by the size of the disagreement region between masks, reducing the leverage of harmful comparisons and improving optimization stability. Across two medical datasets and multiple regimes, RN-DPO improves sustained performance and stabilizes preference-based fine-tuning, outperforming standard DPO and strong baselines without requiring additional pixel annotations.
CT-GRAPH: Hierarchical Graph Attention Network for Anatomy-Guided CT Report Generation
Aug 07, 2025As medical imaging is central to diagnostic processes, automating the generation of radiology reports has become increasingly relevant to assist radiologists with their heavy workloads. Most current methods rely solely on global image features, failing to capture fine-grained organ relationships crucial for accurate reporting. To this end, we propose CT-GRAPH, a hierarchical graph attention network that explicitly models radiological knowledge by structuring anatomical regions into a graph, linking fine-grained organ features to coarser anatomical systems and a global patient context. Our method leverages pretrained 3D medical feature encoders to obtain global and organ-level features by utilizing anatomical masks. These features are further refined within the graph and then integrated into a large language model to generate detailed medical reports. We evaluate our approach for the task of report generation on the large-scale chest CT dataset CT-RATE. We provide an in-depth analysis of pretrained feature encoders for CT report generation and show that our method achieves a substantial improvement of absolute 7.9\% in F1 score over current state-of-the-art methods. The code is publicly available at https://github.com/hakal104/CT-GRAPH.
Automatic Fine-grained Segmentation-assisted Report Generation
Jul 22, 2025Reliable end-to-end clinical report generation has been a longstanding goal of medical ML research. The end goal for this process is to alleviate radiologists' workloads and provide second opinions to clinicians or patients. Thus, a necessary prerequisite for report generation models is a strong general performance and some type of innate grounding capability, to convince clinicians or patients of the veracity of the generated reports. In this paper, we present ASaRG (\textbf{A}utomatic \textbf{S}egmentation-\textbf{a}ssisted \textbf{R}eport \textbf{G}eneration), an extension of the popular LLaVA architecture that aims to tackle both of these problems. ASaRG proposes to fuse intermediate features and fine-grained segmentation maps created by specialist radiological models into LLaVA's multi-modal projection layer via simple concatenation. With a small number of added parameters, our approach achieves a +0.89\% performance gain ($p=0.012$) in CE F1 score compared to the LLaVA baseline when using only intermediate features, and +2.77\% performance gain ($p<0.001$) when adding a combination of intermediate features and fine-grained segmentation maps. Compared with COMG and ORID, two other report generation methods that utilize segmentations, the performance gain amounts to 6.98\% and 6.28\% in F1 score, respectively. ASaRG is not mutually exclusive with other changes made to the LLaVA architecture, potentially allowing our method to be combined with other advances in the field. Finally, the use of an arbitrary number of segmentations as part of the input demonstrably allows tracing elements of the report to the corresponding segmentation maps and verifying the groundedness of assessments. Our code will be made publicly available at a later date.
Foreign object segmentation in chest x-rays through anatomy-guided shape insertion
Jan 21, 2025



In this paper, we tackle the challenge of instance segmentation for foreign objects in chest radiographs, commonly seen in postoperative follow-ups with stents, pacemakers, or ingested objects in children. The diversity of foreign objects complicates dense annotation, as shown in insufficient existing datasets. To address this, we propose the simple generation of synthetic data through (1) insertion of arbitrary shapes (lines, polygons, ellipses) with varying contrasts and opacities, and (2) cut-paste augmentations from a small set of semi-automatically extracted labels. These insertions are guided by anatomy labels to ensure realistic placements, such as stents appearing only in relevant vessels. Our approach enables networks to segment complex structures with minimal manually labeled data. Notably, it achieves performance comparable to fully supervised models while using 93\% fewer manual annotations.
Autopet III challenge: Incorporating anatomical knowledge into nnUNet for lesion segmentation in PET/CT
Sep 18, 2024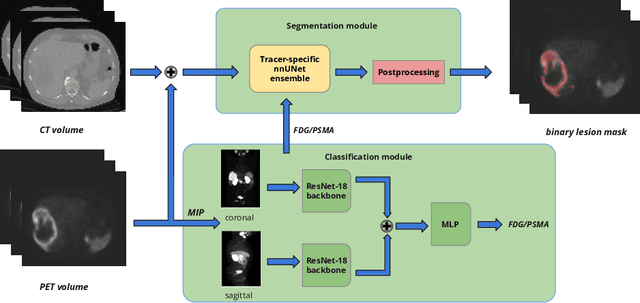


Lesion segmentation in PET/CT imaging is essential for precise tumor characterization, which supports personalized treatment planning and enhances diagnostic precision in oncology. However, accurate manual segmentation of lesions is time-consuming and prone to inter-observer variability. Given the rising demand and clinical use of PET/CT, automated segmentation methods, particularly deep-learning-based approaches, have become increasingly more relevant. The autoPET III Challenge focuses on advancing automated segmentation of tumor lesions in PET/CT images in a multitracer multicenter setting, addressing the clinical need for quantitative, robust, and generalizable solutions. Building on previous challenges, the third iteration of the autoPET challenge introduces a more diverse dataset featuring two different tracers (FDG and PSMA) from two clinical centers. To this extent, we developed a classifier that identifies the tracer of the given PET/CT based on the Maximum Intensity Projection of the PET scan. We trained two individual nnUNet-ensembles for each tracer where anatomical labels are included as a multi-label task to enhance the model's performance. Our final submission achieves cross-validation Dice scores of 76.90% and 61.33% for the publicly available FDG and PSMA datasets, respectively. The code is available at https://github.com/hakal104/autoPETIII/ .
Exploring the Limits of Deep Image Clustering using Pretrained Models
Mar 31, 2023We present a general methodology that learns to classify images without labels by leveraging pretrained feature extractors. Our approach involves self-distillation training of clustering heads, based on the fact that nearest neighbors in the pretrained feature space are likely to share the same label. We propose a novel objective to learn associations between images by introducing a variant of pointwise mutual information together with instance weighting. We demonstrate that the proposed objective is able to attenuate the effect of false positive pairs while efficiently exploiting the structure in the pretrained feature space. As a result, we improve the clustering accuracy over $k$-means on $17$ different pretrained models by $6.1$\% and $12.2$\% on ImageNet and CIFAR100, respectively. Finally, using self-supervised pretrained vision transformers we push the clustering accuracy on ImageNet to $61.6$\%. The code will be open-sourced.