 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClusterMine: Robust Label-Free Visual Out-Of-Distribution Detection via Concept Mining from Text Corpora
Nov 10, 2025Large-scale visual out-of-distribution (OOD) detection has witnessed remarkable progress by leveraging vision-language models such as CLIP. However, a significant limitation of current methods is their reliance on a pre-defined set of in-distribution (ID) ground-truth label names (positives). These fixed label names can be unavailable, unreliable at scale, or become less relevant due to in-distribution shifts after deployment. Towards truly unsupervised OOD detection, we utilize widely available text corpora for positive label mining, bypassing the need for positives. In this paper, we utilize widely available text corpora for positive label mining under a general concept mining paradigm. Within this framework, we propose ClusterMine, a novel positive label mining method. ClusterMine is the first method to achieve state-of-the-art OOD detection performance without access to positive labels. It extracts positive concepts from a large text corpus by combining visual-only sample consistency (via clustering) and zero-shot image-text consistency. Our experimental study reveals that ClusterMine is scalable across a plethora of CLIP models and achieves state-of-the-art robustness to covariate in-distribution shifts. The code is available at https://github.com/HHU-MMBS/clustermine_wacv_official.
The Unreasonable Effectiveness of Guidance for Diffusion Models
Nov 15, 2024
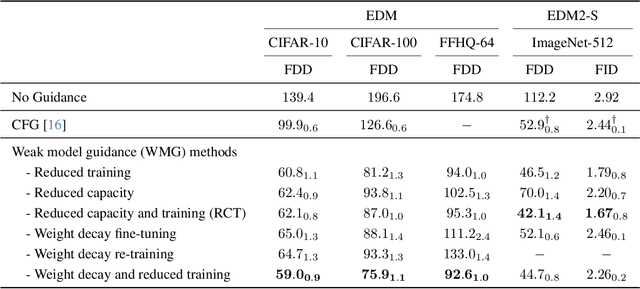
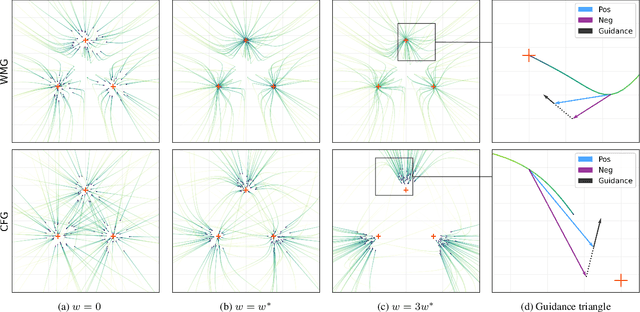
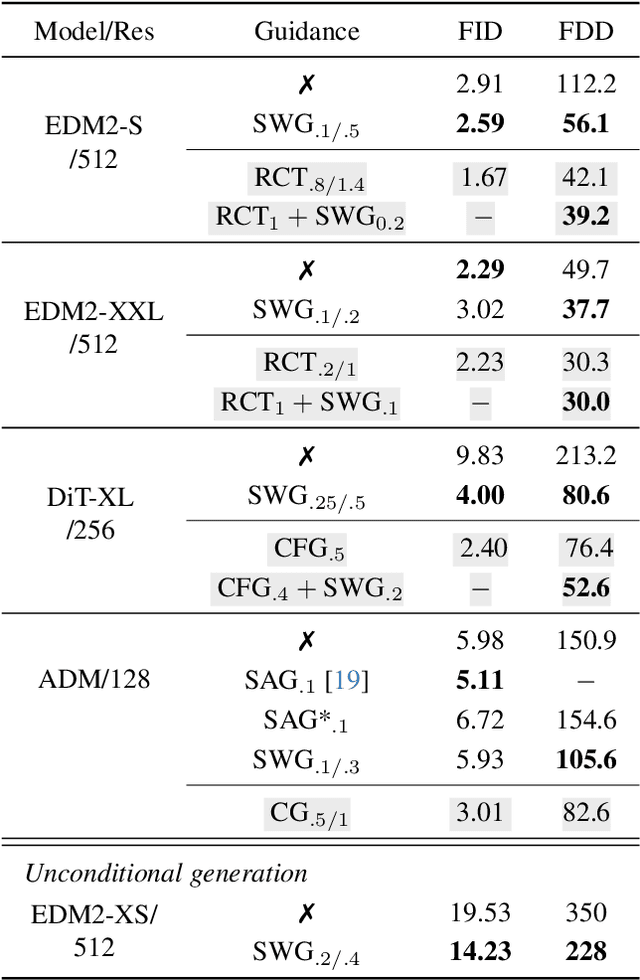
Guidance is an error-correcting technique used to improve the perceptual quality of images generated by diffusion models. Typically, the correction is achieved by linear extrapolation, using an auxiliary diffusion model that has lower performance than the primary model. Using a 2D toy example, we show that it is highly beneficial when the auxiliary model exhibits similar errors as the primary one but stronger. We verify this finding in higher dimensions, where we show that competitive generative performance to state-of-the-art guidance methods can be achieved when the auxiliary model differs from the primary one only by having stronger weight regularization. As an independent contribution, we investigate whether upweighting long-range spatial dependencies improves visual fidelity. The result is a novel guidance method, which we call sliding window guidance (SWG), that guides the primary model with itself by constraining its receptive field. Intriguingly, SWG aligns better with human preferences than state-of-the-art guidance methods while requiring neither training, architectural modifications, nor class conditioning. The code will be released.
Scaling Up Deep Clustering Methods Beyond ImageNet-1K
Jun 03, 2024Deep image clustering methods are typically evaluated on small-scale balanced classification datasets while feature-based $k$-means has been applied on proprietary billion-scale datasets. In this work, we explore the performance of feature-based deep clustering approaches on large-scale benchmarks whilst disentangling the impact of the following data-related factors: i) class imbalance, ii) class granularity, iii) easy-to-recognize classes, and iv) the ability to capture multiple classes. Consequently, we develop multiple new benchmarks based on ImageNet21K. Our experimental analysis reveals that feature-based $k$-means is often unfairly evaluated on balanced datasets. However, deep clustering methods outperform $k$-means across most large-scale benchmarks. Interestingly, $k$-means underperforms on easy-to-classify benchmarks by large margins. The performance gap, however, diminishes on the highest data regimes such as ImageNet21K. Finally, we find that non-primary cluster predictions capture meaningful classes (i.e. coarser classes).
Rethinking cluster-conditioned diffusion models
Mar 01, 2024We present a comprehensive experimental study on image-level conditioning for diffusion models using cluster assignments. We elucidate how individual components regarding image clustering impact image synthesis across three datasets. By combining recent advancements from image clustering and diffusion models, we show that, given the optimal cluster granularity with respect to image synthesis (visual groups), cluster-conditioning can achieve state-of-the-art FID (i.e. 1.67, 2.17 on CIFAR10 and CIFAR100 respectively), while attaining a strong training sample efficiency. Finally, we propose a novel method to derive an upper cluster bound that reduces the search space of the visual groups using solely feature-based clustering. Unlike existing approaches, we find no significant connection between clustering and cluster-conditional image generation. The code and cluster assignments will be released.
Exploring the Limits of Deep Image Clustering using Pretrained Models
Mar 31, 2023We present a general methodology that learns to classify images without labels by leveraging pretrained feature extractors. Our approach involves self-distillation training of clustering heads, based on the fact that nearest neighbors in the pretrained feature space are likely to share the same label. We propose a novel objective to learn associations between images by introducing a variant of pointwise mutual information together with instance weighting. We demonstrate that the proposed objective is able to attenuate the effect of false positive pairs while efficiently exploiting the structure in the pretrained feature space. As a result, we improve the clustering accuracy over $k$-means on $17$ different pretrained models by $6.1$\% and $12.2$\% on ImageNet and CIFAR100, respectively. Finally, using self-supervised pretrained vision transformers we push the clustering accuracy on ImageNet to $61.6$\%. The code will be open-sourced.
Contrastive Language-Image Pretrained Models are Powerful Out-of-Distribution Detectors
Mar 10, 2023



We present a comprehensive experimental study on pretrained feature extractors for visual out-of-distribution (OOD) detection. We examine several setups, based on the availability of labels or image captions and using different combinations of in- and out-distributions. Intriguingly, we find that (i) contrastive language-image pretrained models achieve state-of-the-art unsupervised out-of-distribution performance using nearest neighbors feature similarity as the OOD detection score, (ii) supervised state-of-the-art OOD detection performance can be obtained without in-distribution fine-tuning, (iii) even top-performing billion-scale vision transformers trained with natural language supervision fail at detecting adversarially manipulated OOD images. Finally, we argue whether new benchmarks for visual anomaly detection are needed based on our experiments. Using the largest publicly available vision transformer, we achieve state-of-the-art performance across all $18$ reported OOD benchmarks, including an AUROC of 87.6\% (9.2\% gain, unsupervised) and 97.4\% (1.2\% gain, supervised) for the challenging task of CIFAR100 $\rightarrow$ CIFAR10 OOD detection. The code will be open-sourced.
Self-Supervised Anomaly Detection by Self-Distillation and Negative Sampling
Jan 17, 2022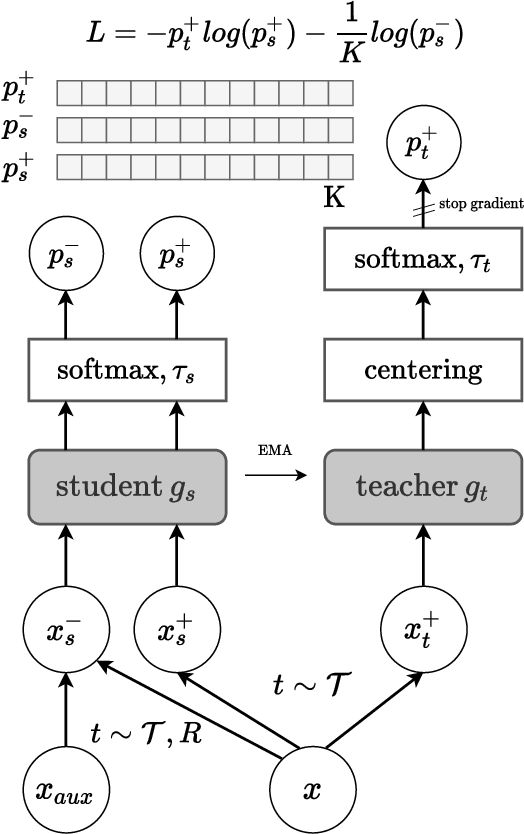
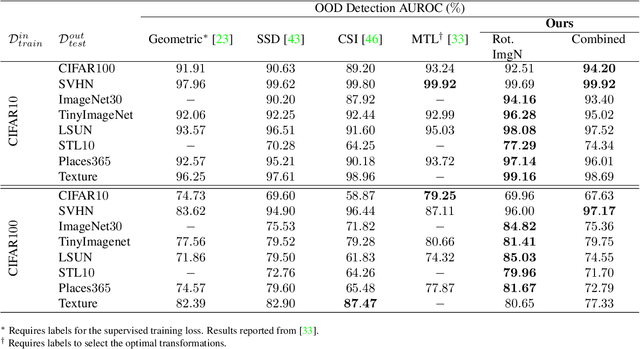
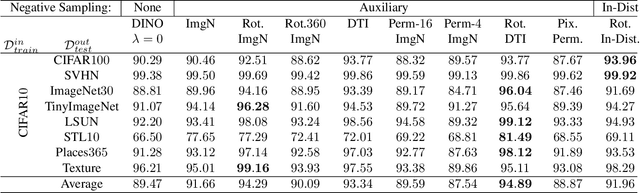
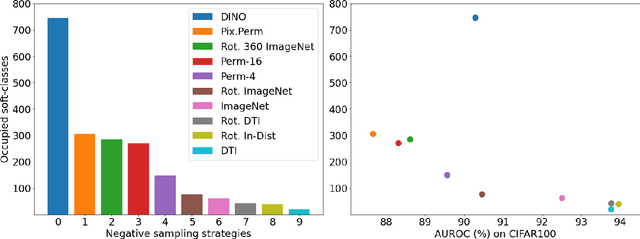
Detecting whether examples belong to a given in-distribution or are Out-Of-Distribution (OOD) requires identifying features specific to the in-distribution. In the absence of labels, these features can be learned by self-supervised techniques under the generic assumption that the most abstract features are those which are statistically most over-represented in comparison to other distributions from the same domain. In this work, we show that self-distillation of the in-distribution training set together with contrasting against negative examples derived from shifting transformation of auxiliary data strongly improves OOD detection. We find that this improvement depends on how the negative samples are generated. In particular, we observe that by leveraging negative samples, which keep the statistics of low-level features while changing the high-level semantics, higher average detection performance is obtained. Furthermore, good negative sampling strategies can be identified from the sensitivity of the OOD detection score. The efficiency of our approach is demonstrated across a diverse range of OOD detection problems, setting new benchmarks for unsupervised OOD detection in the visual domain.
A Comprehensive Study on Sign Language Recognition Methods
Jul 24, 2020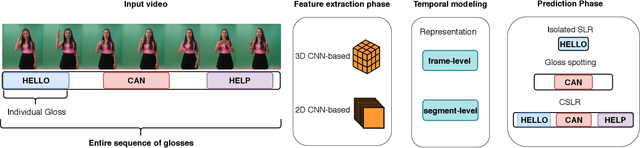



In this paper, a comparative experimental assessment of computer vision-based methods for sign language recognition is conducted. By implementing the most recent deep neural network methods in this field, a thorough evaluation on multiple publicly available datasets is performed. The aim of the present study is to provide insights on sign language recognition, focusing on mapping non-segmented video streams to glosses. For this task, two new sequence training criteria, known from the fields of speech and scene text recognition, are introduced. Furthermore, a plethora of pretraining schemes is thoroughly discussed. Finally, a new RGB+D dataset for the Greek sign language is created. To the best of our knowledge, this is the first sign language dataset where sentence and gloss level annotations are provided for a video capture.
Multi-view adaptive graph convolutions for graph classification
Jul 24, 2020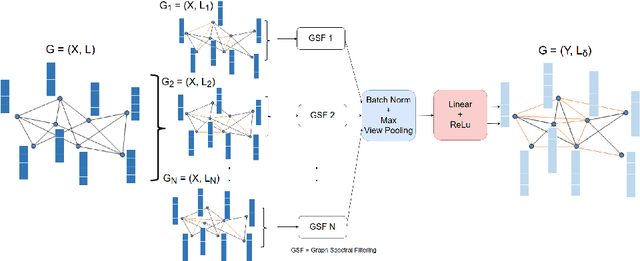
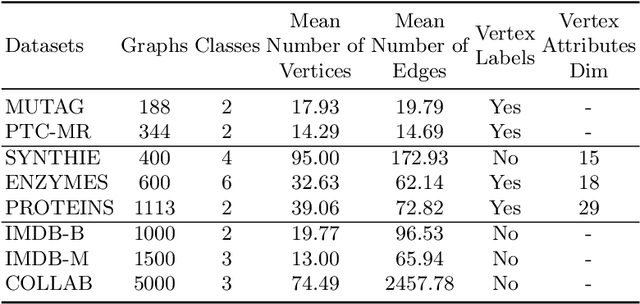
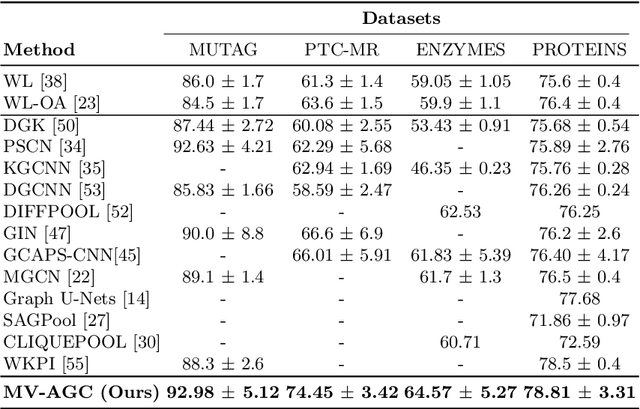
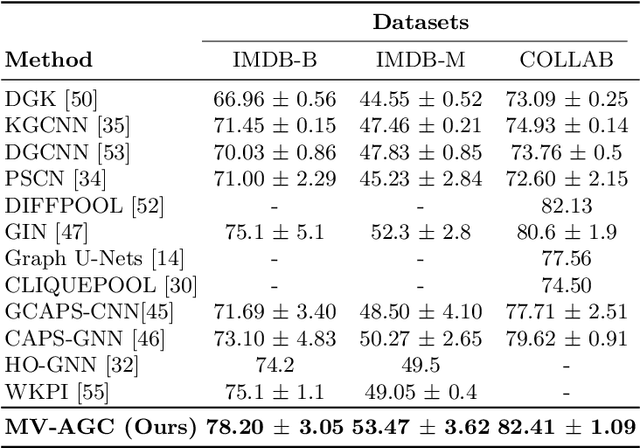
In this paper, a novel multi-view methodology for graph-based neural networks is proposed. A systematic and methodological adaptation of the key concepts of classical deep learning methods such as convolution, pooling and multi-view architectures is developed for the context of non-Euclidean manifolds. The aim of the proposed work is to present a novel multi-view graph convolution layer, as well as a new view pooling layer making use of: a) a new hybrid Laplacian that is adjusted based on feature distance metric learning, b) multiple trainable representations of a feature matrix of a graph, using trainable distance matrices, adapting the notion of views to graphs and c) a multi-view graph aggregation scheme called graph view pooling, in order to synthesise information from the multiple generated views. The aforementioned layers are used in an end-to-end graph neural network architecture for graph classification and show competitive results to other state-of-the-art methods.