 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Anomaly Detection by Self-Distillation and Negative Sampling
Jan 17, 2022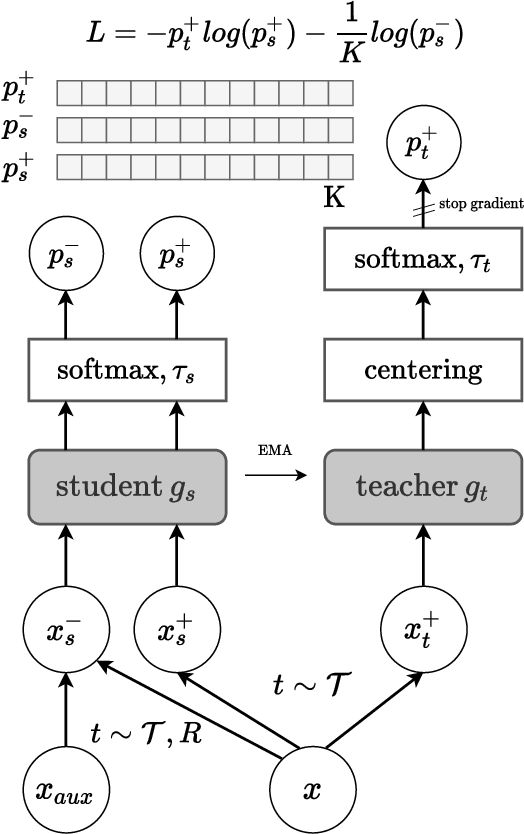
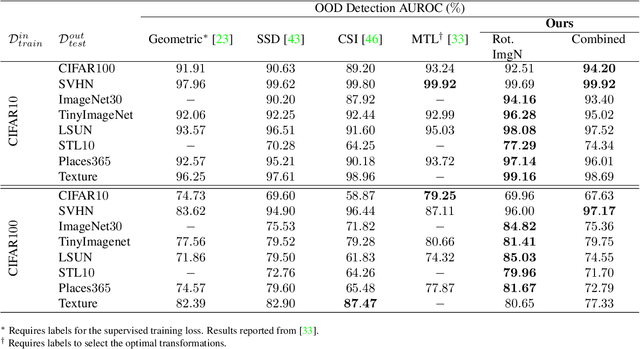
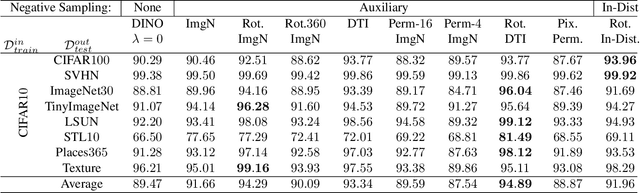
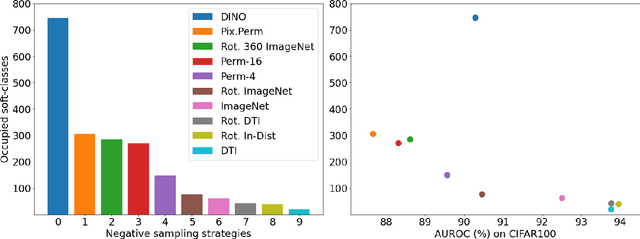
Detecting whether examples belong to a given in-distribution or are Out-Of-Distribution (OOD) requires identifying features specific to the in-distribution. In the absence of labels, these features can be learned by self-supervised techniques under the generic assumption that the most abstract features are those which are statistically most over-represented in comparison to other distributions from the same domain. In this work, we show that self-distillation of the in-distribution training set together with contrasting against negative examples derived from shifting transformation of auxiliary data strongly improves OOD detection. We find that this improvement depends on how the negative samples are generated. In particular, we observe that by leveraging negative samples, which keep the statistics of low-level features while changing the high-level semantics, higher average detection performance is obtained. Furthermore, good negative sampling strategies can be identified from the sensitivity of the OOD detection score. The efficiency of our approach is demonstrated across a diverse range of OOD detection problems, setting new benchmarks for unsupervised OOD detection in the visual domain.