 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Anomaly Detection by Self-Distillation and Negative Sampling
Jan 17, 2022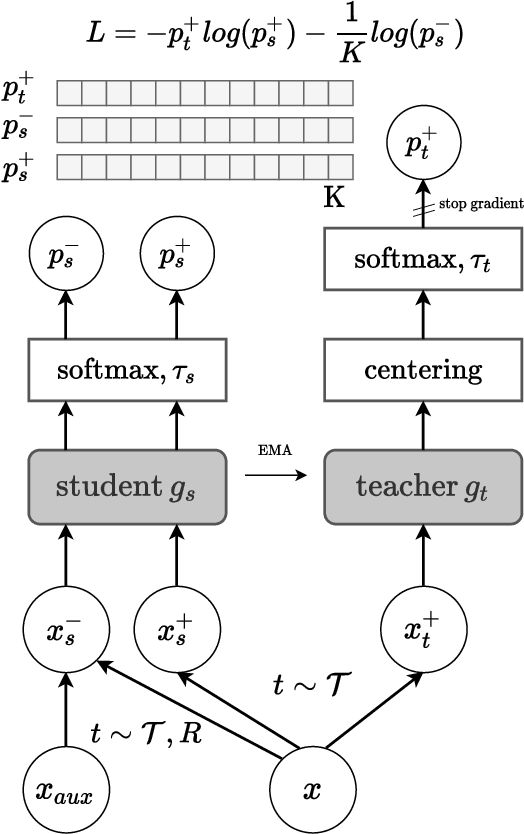
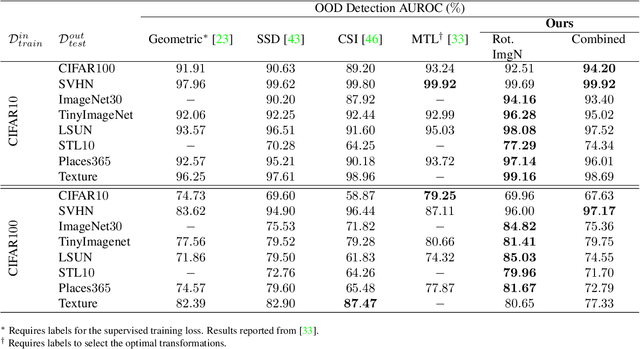
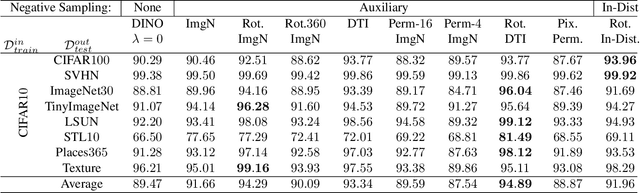
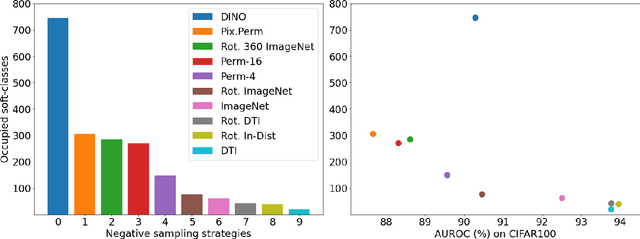
Detecting whether examples belong to a given in-distribution or are Out-Of-Distribution (OOD) requires identifying features specific to the in-distribution. In the absence of labels, these features can be learned by self-supervised techniques under the generic assumption that the most abstract features are those which are statistically most over-represented in comparison to other distributions from the same domain. In this work, we show that self-distillation of the in-distribution training set together with contrasting against negative examples derived from shifting transformation of auxiliary data strongly improves OOD detection. We find that this improvement depends on how the negative samples are generated. In particular, we observe that by leveraging negative samples, which keep the statistics of low-level features while changing the high-level semantics, higher average detection performance is obtained. Furthermore, good negative sampling strategies can be identified from the sensitivity of the OOD detection score. The efficiency of our approach is demonstrated across a diverse range of OOD detection problems, setting new benchmarks for unsupervised OOD detection in the visual domain.
Teaching a Machine to Diagnose a Heart Disease; Beginning from digitizing scanned ECGs to detecting the Brugada Syndrome
Aug 27, 2020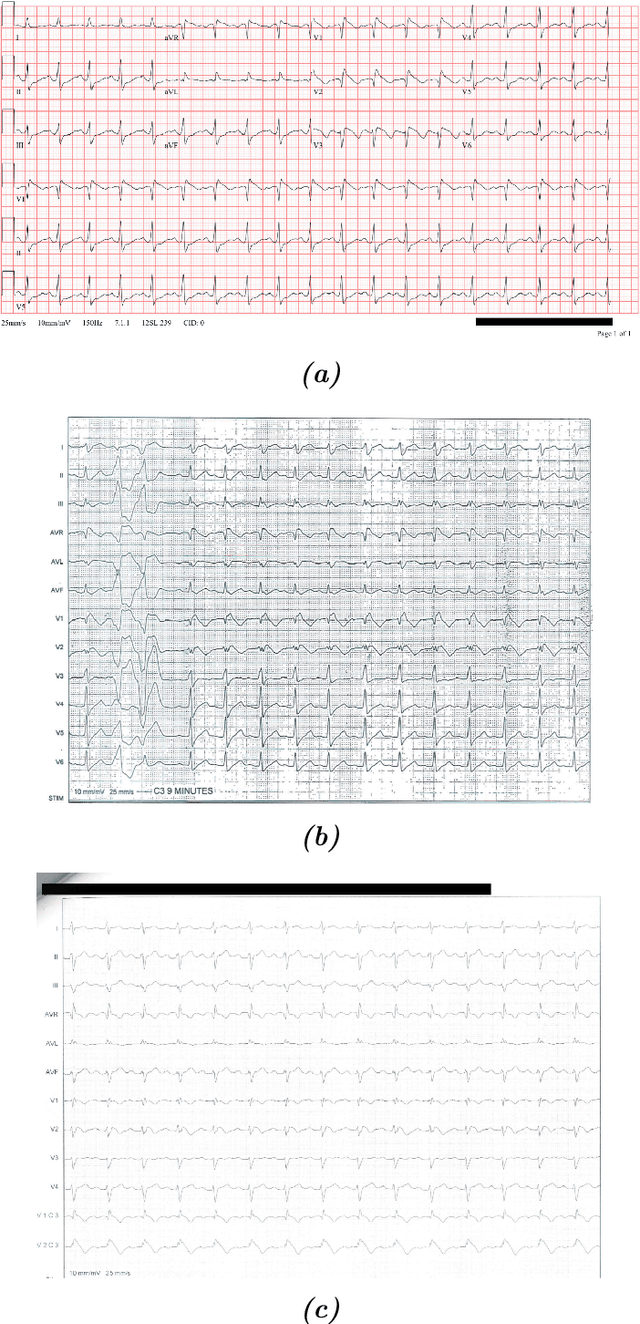
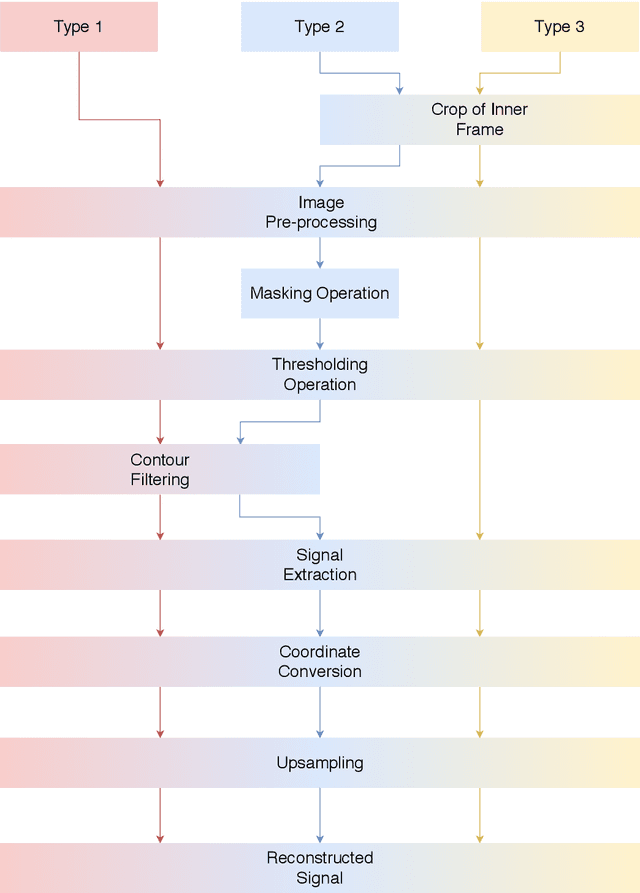


Medical diagnoses can shape and change the life of a person drastically. Therefore, it is always best advised to collect as much evidence as possible to be certain about the diagnosis. Unfortunately, in the case of the Brugada Syndrome (BrS), a rare and inherited heart disease, only one diagnostic criterion exists, namely, a typical pattern in the Electrocardiogram (ECG). In the following treatise, we question whether the investigation of ECG strips by the means of machine learning methods improves the detection of BrS positive cases and hence, the diagnostic process. We propose a pipeline that reads in scanned images of ECGs, and transforms the encaptured signals to digital time-voltage data after several processing steps. Then, we present a long short-term memory (LSTM) classifier that is built based on the previously extracted data and that makes the diagnosis. The proposed pipeline distinguishes between three major types of ECG images and recreates each recorded lead signal. Features and quality are retained during the digitization of the data, albeit some encountered issues are not fully removed (Part I). Nevertheless, the results of the aforesaid program are suitable for further investigation of the ECG by a computational method such as the proposed classifier which proves the concept and could be the architectural basis for future research (Part II). This thesis is divided into two parts as they are part of the same process but conceptually different. It is hoped that this work builds a new foundation for computational investigations in the case of the BrS and its diagnosis.