 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Uncertainty: Efficient Machine Unlearning for Generative AI
Aug 28, 2025We introduce SAFEMax, a novel method for Machine Unlearning in diffusion models. Grounded in information-theoretic principles, SAFEMax maximizes the entropy in generated images, causing the model to generate Gaussian noise when conditioned on impermissible classes by ultimately halting its denoising process. Also, our method controls the balance between forgetting and retention by selectively focusing on the early diffusion steps, where class-specific information is prominent. Our results demonstrate the effectiveness of SAFEMax and highlight its substantial efficiency gains over state-of-the-art methods.
MC-hands-1M: A glove-wearing hand dataset for pose estimation
Oct 19, 2022

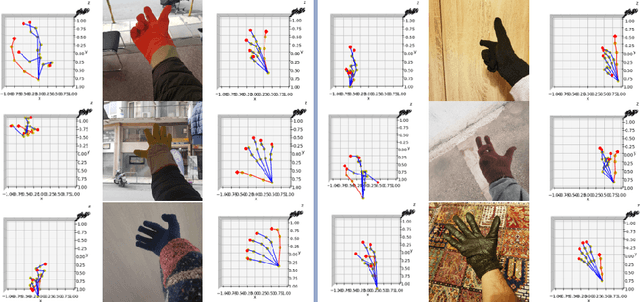
Nowadays, the need for large amounts of carefully and complexly annotated data for the training of computer vision modules continues to grow. Furthermore, although the research community presents state of the art solutions to many problems, there exist special cases, such as the pose estimation and tracking of a glove-wearing hand, where the general approaches tend to be unable to provide an accurate solution or fail completely. In this work, we are presenting a synthetic dataset1 for 3D pose estimation of glove-wearing hands, in order to depict the value of data synthesis in computer vision. The dataset is used to fine-tune a public hand joint detection model, achieving significant performance in both synthetic and real images of glove-wearing hands.
Multi-manifold Attention for Vision Transformers
Jul 18, 2022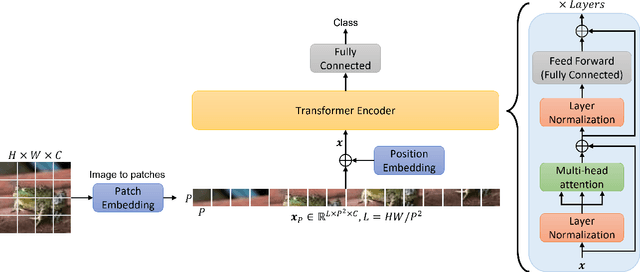

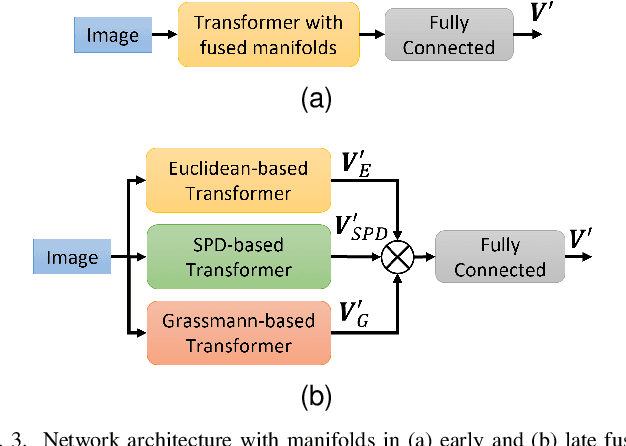

Vision Transformer are very popular nowadays due to their state-of-the-art performance in several computer vision tasks, such as image classification and action recognition. Although the performance of Vision Transformers have been greatly improved by employing Convolutional Neural Networks, hierarchical structures and compact forms, there is limited research on ways to utilize additional data representations to refine the attention map derived from the multi-head attention of a Transformer network. This work proposes a novel attention mechanism, called multi-manifold attention, that can substitute any standard attention mechanism in a Transformer-based network. The proposed attention models the input space in three distinct manifolds, namely Euclidean, Symmetric Positive Definite and Grassmann, with different statistical and geometrical properties, guiding the network to take into consideration a rich set of information that describe the appearance, color and texture of an image, for the computation of a highly descriptive attention map. In this way, a Vision Transformer with the proposed attention is guided to become more attentive towards discriminative features, leading to improved classification results, as shown by the experimental results on several well-known image classification datasets.
Hybrid Skip: A Biologically Inspired Skip Connection for the UNet Architecture
Jul 11, 2022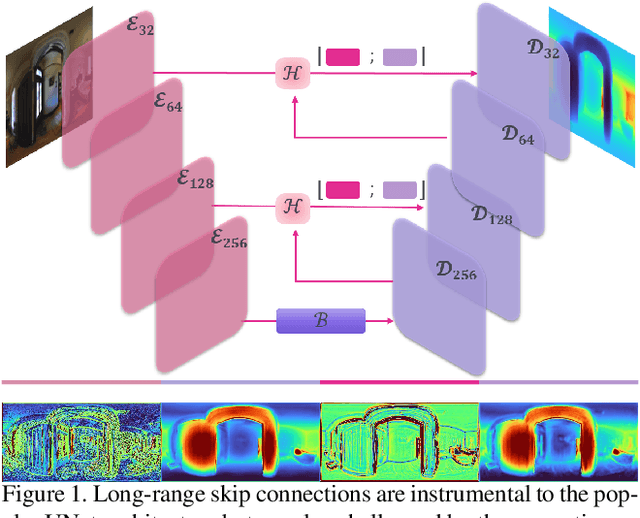

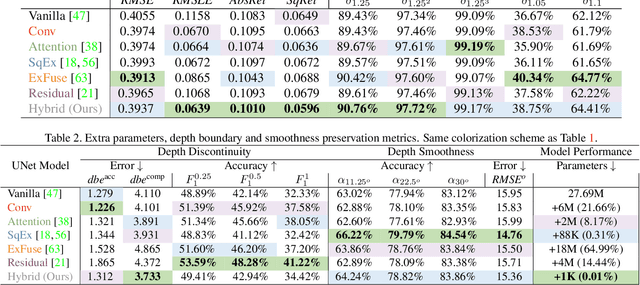
In this work we introduce a biologically inspired long-range skip connection for the UNet architecture that relies on the perceptual illusion of hybrid images, being images that simultaneously encode two images. The fusion of early encoder features with deeper decoder ones allows UNet models to produce finer-grained dense predictions. While proven in segmentation tasks, the network's benefits are down-weighted for dense regression tasks as these long-range skip connections additionally result in texture transfer artifacts. Specifically for depth estimation, this hurts smoothness and introduces false positive edges which are detrimental to the task due to the depth maps' piece-wise smooth nature. The proposed HybridSkip connections show improved performance in balancing the trade-off between edge preservation, and the minimization of texture transfer artifacts that hurt smoothness. This is achieved by the proper and balanced exchange of information that Hybrid-Skip connections offer between the high and low frequency, encoder and decoder features, respectively.
* Project page at https://vcl3d.github.io/HybridSkip/
Monocular Spherical Depth Estimation with Explicitly Connected Weak Layout Cues
Jun 22, 2022
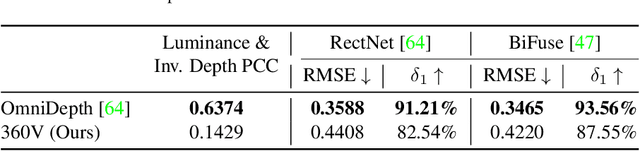
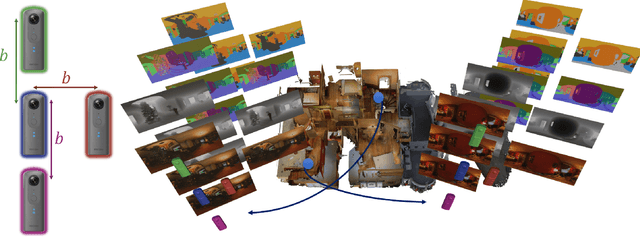

Spherical cameras capture scenes in a holistic manner and have been used for room layout estimation. Recently, with the availability of appropriate datasets, there has also been progress in depth estimation from a single omnidirectional image. While these two tasks are complementary, few works have been able to explore them in parallel to advance indoor geometric perception, and those that have done so either relied on synthetic data, or used small scale datasets, as few options are available that include both layout annotations and dense depth maps in real scenes. This is partly due to the necessity of manual annotations for room layouts. In this work, we move beyond this limitation and generate a 360 geometric vision (360V) dataset that includes multiple modalities, multi-view stereo data and automatically generated weak layout cues. We also explore an explicit coupling between the two tasks to integrate them into a singleshot trained model. We rely on depth-based layout reconstruction and layout-based depth attention, demonstrating increased performance across both tasks. By using single 360 cameras to scan rooms, the opportunity for facile and quick building-scale 3D scanning arises.
* Project page at https://vcl3d.github.io/ExplicitLayoutDepth/
A benchmark with decomposed distribution shifts for 360 monocular depth estimation
Dec 01, 2021



In this work we contribute a distribution shift benchmark for a computer vision task; monocular depth estimation. Our differentiation is the decomposition of the wider distribution shift of uncontrolled testing on in-the-wild data, to three distinct distribution shifts. Specifically, we generate data via synthesis and analyze them to produce covariate (color input), prior (depth output) and concept (their relationship) distribution shifts. We also synthesize combinations and show how each one is indeed a different challenge to address, as stacking them produces increased performance drops and cannot be addressed horizontally using standard approaches.
On Coordinate Decoding for Keypoint Estimation Tasks
Oct 19, 2021
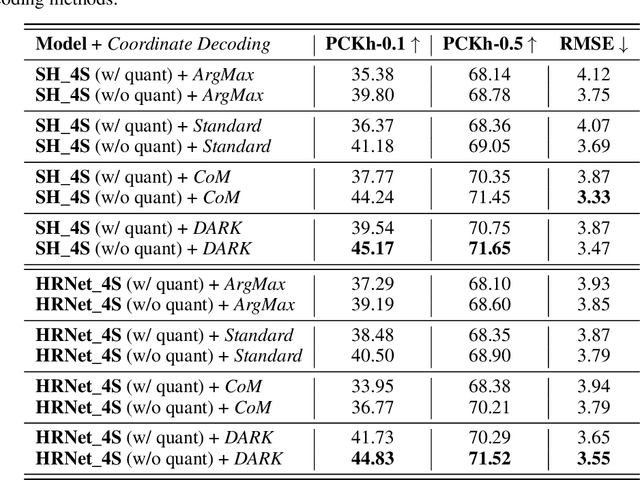


A series of 2D (and 3D) keypoint estimation tasks are built upon heatmap coordinate representation, i.e. a probability map that allows for learnable and spatially aware encoding and decoding of keypoint coordinates on grids, even allowing for sub-pixel coordinate accuracy. In this report, we aim to reproduce the findings of DARK that investigated the 2D heatmap representation by highlighting the importance of the encoding of the ground truth heatmap and the decoding of the predicted heatmap to keypoint coordinates. The authors claim that a) a more principled distribution-aware coordinate decoding method overcomes the limitations of the standard techniques widely used in the literature, and b), that the reconstruction of heatmaps from ground-truth coordinates by generating accurate and continuous heatmap distributions lead to unbiased model training, contrary to the standard coordinate encoding process that quantizes the keypoint coordinates on the resolution of the input image grid.
HUMAN4D: A Human-Centric Multimodal Dataset for Motions and Immersive Media
Oct 19, 2021

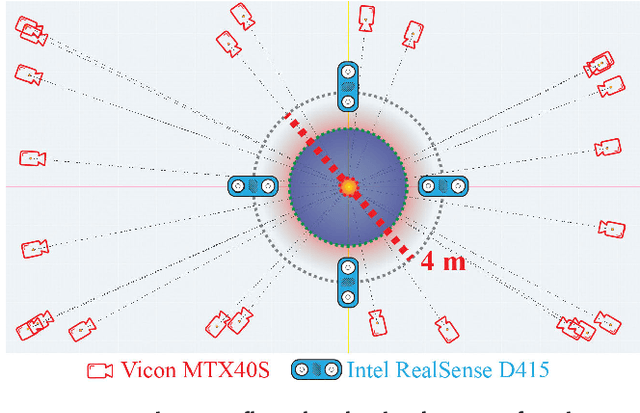
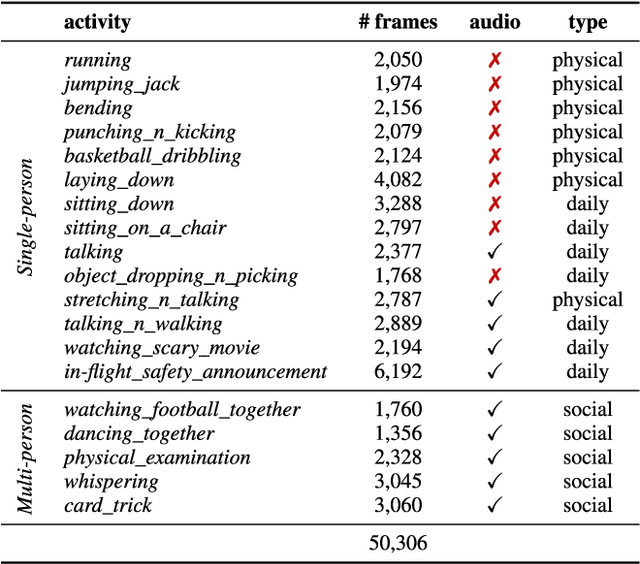
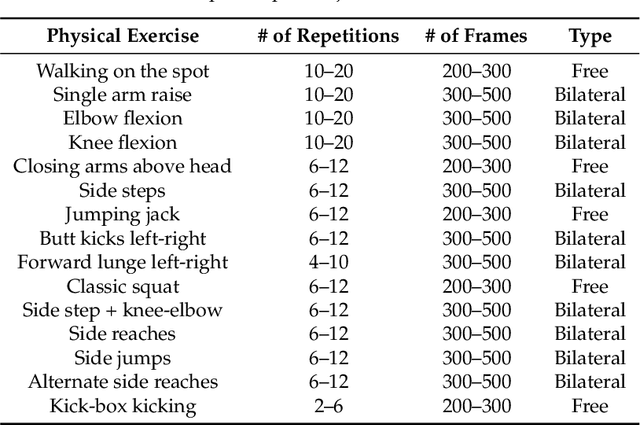
We introduce HUMAN4D, a large and multimodal 4D dataset that contains a variety of human activities simultaneously captured by a professional marker-based MoCap, a volumetric capture and an audio recording system. By capturing 2 female and $2$ male professional actors performing various full-body movements and expressions, HUMAN4D provides a diverse set of motions and poses encountered as part of single- and multi-person daily, physical and social activities (jumping, dancing, etc.), along with multi-RGBD (mRGBD), volumetric and audio data. Despite the existence of multi-view color datasets captured with the use of hardware (HW) synchronization, to the best of our knowledge, HUMAN4D is the first and only public resource that provides volumetric depth maps with high synchronization precision due to the use of intra- and inter-sensor HW-SYNC. Moreover, a spatio-temporally aligned scanned and rigged 3D character complements HUMAN4D to enable joint research on time-varying and high-quality dynamic meshes. We provide evaluation baselines by benchmarking HUMAN4D with state-of-the-art human pose estimation and 3D compression methods. For the former, we apply 2D and 3D pose estimation algorithms both on single- and multi-view data cues. For the latter, we benchmark open-source 3D codecs on volumetric data respecting online volumetric video encoding and steady bit-rates. Furthermore, qualitative and quantitative visual comparison between mesh-based volumetric data reconstructed in different qualities showcases the available options with respect to 4D representations. HUMAN4D is introduced to the computer vision and graphics research communities to enable joint research on spatio-temporally aligned pose, volumetric, mRGBD and audio data cues. The dataset and its code are available https://tofis.github.io/myurls/human4d.
DeepMoCap: Deep Optical Motion Capture Using Multiple Depth Sensors and Retro-Reflectors
Oct 14, 2021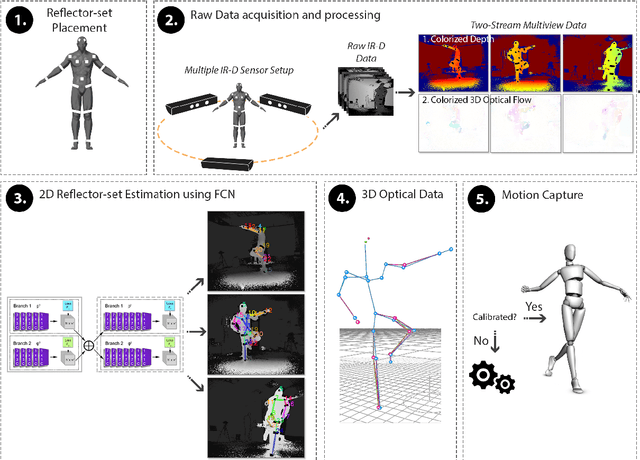
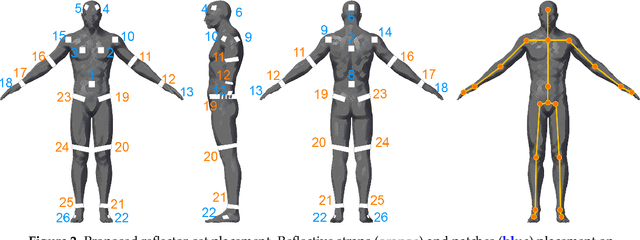
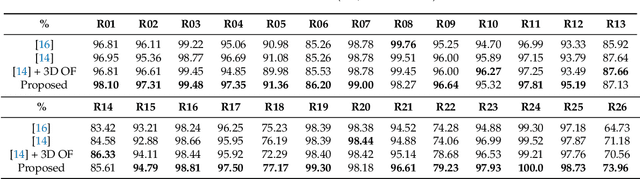
In this paper, a marker-based, single-person optical motion capture method (DeepMoCap) is proposed using multiple spatio-temporally aligned infrared-depth sensors and retro-reflective straps and patches (reflectors). DeepMoCap explores motion capture by automatically localizing and labeling reflectors on depth images and, subsequently, on 3D space. Introducing a non-parametric representation to encode the temporal correlation among pairs of colorized depthmaps and 3D optical flow frames, a multi-stage Fully Convolutional Network (FCN) architecture is proposed to jointly learn reflector locations and their temporal dependency among sequential frames. The extracted reflector 2D locations are spatially mapped in 3D space, resulting in robust 3D optical data extraction. The subject's motion is efficiently captured by applying a template-based fitting technique on the extracted optical data. Two datasets have been created and made publicly available for evaluation purposes; one comprising multi-view depth and 3D optical flow annotated images (DMC2.5D), and a second, consisting of spatio-temporally aligned multi-view depth images along with skeleton, inertial and ground truth MoCap data (DMC3D). The FCN model outperforms its competitors on the DMC2.5D dataset using 2D Percentage of Correct Keypoints (PCK) metric, while the motion capture outcome is evaluated against RGB-D and inertial data fusion approaches on DMC3D, outperforming the next best method by 4.5% in total 3D PCK accuracy.
Pano3D: A Holistic Benchmark and a Solid Baseline for $360^o$ Depth Estimation
Sep 06, 2021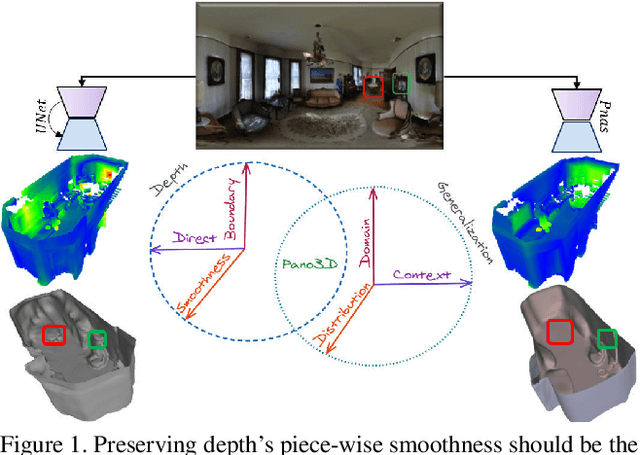
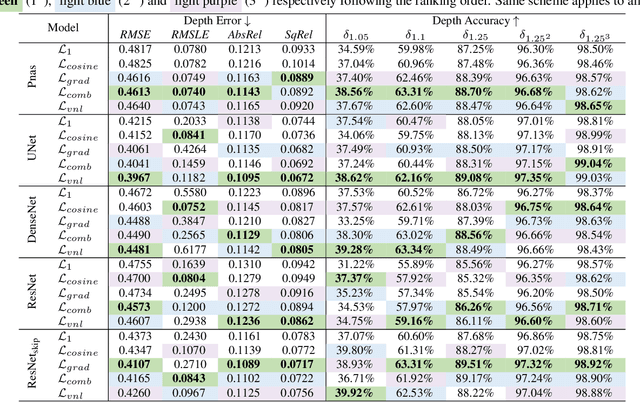

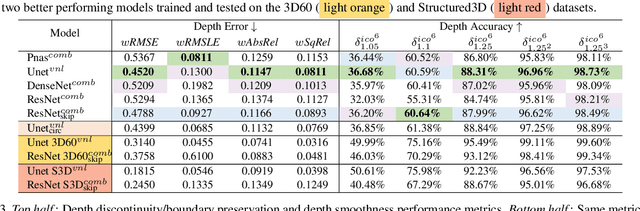
Pano3D is a new benchmark for depth estimation from spherical panoramas. It aims to assess performance across all depth estimation traits, the primary direct depth estimation performance targeting precision and accuracy, and also the secondary traits, boundary preservation, and smoothness. Moreover, Pano3D moves beyond typical intra-dataset evaluation to inter-dataset performance assessment. By disentangling the capacity to generalize to unseen data into different test splits, Pano3D represents a holistic benchmark for $360^o$ depth estimation. We use it as a basis for an extended analysis seeking to offer insights into classical choices for depth estimation. This results in a solid baseline for panoramic depth that follow-up works can build upon to steer future progress.