 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Smoothing Meets Vision-Language Models
Sep 19, 2025Randomized smoothing (RS) is one of the prominent techniques to ensure the correctness of machine learning models, where point-wise robustness certificates can be derived analytically. While RS is well understood for classification, its application to generative models is unclear, since their outputs are sequences rather than labels. We resolve this by connecting generative outputs to an oracle classification task and showing that RS can still be enabled: the final response can be classified as a discrete action (e.g., service-robot commands in VLAs), as harmful vs. harmless (content moderation or toxicity detection in VLMs), or even applying oracles to cluster answers into semantically equivalent ones. Provided that the error rate for the oracle classifier comparison is bounded, we develop the theory that associates the number of samples with the corresponding robustness radius. We further derive improved scaling laws analytically relating the certified radius and accuracy to the number of samples, showing that the earlier result of 2 to 3 orders of magnitude fewer samples sufficing with minimal loss remains valid even under weaker assumptions. Together, these advances make robustness certification both well-defined and computationally feasible for state-of-the-art VLMs, as validated against recent jailbreak-style adversarial attacks.
SAM2CLIP2SAM: Vision Language Model for Segmentation of 3D CT Scans for Covid-19 Detection
Jul 23, 2024This paper presents a new approach for effective segmentation of images that can be integrated into any model and methodology; the paradigm that we choose is classification of medical images (3-D chest CT scans) for Covid-19 detection. Our approach includes a combination of vision-language models that segment the CT scans, which are then fed to a deep neural architecture, named RACNet, for Covid-19 detection. In particular, a novel framework, named SAM2CLIP2SAM, is introduced for segmentation that leverages the strengths of both Segment Anything Model (SAM) and Contrastive Language-Image Pre-Training (CLIP) to accurately segment the right and left lungs in CT scans, subsequently feeding these segmented outputs into RACNet for classification of COVID-19 and non-COVID-19 cases. At first, SAM produces multiple part-based segmentation masks for each slice in the CT scan; then CLIP selects only the masks that are associated with the regions of interest (ROIs), i.e., the right and left lungs; finally SAM is given these ROIs as prompts and generates the final segmentation mask for the lungs. Experiments are presented across two Covid-19 annotated databases which illustrate the improved performance obtained when our method has been used for segmentation of the CT scans.
Complex Style Image Transformations for Domain Generalization in Medical Images
Jun 01, 2024



The absence of well-structured large datasets in medical computer vision results in decreased performance of automated systems and, especially, of deep learning models. Domain generalization techniques aim to approach unknown domains from a single data source. In this paper we introduce a novel framework, named CompStyle, which leverages style transfer and adversarial training, along with high-level input complexity augmentation to effectively expand the domain space and address unknown distributions. State-of-the-art style transfer methods depend on the existence of subdomains within the source dataset. However, this can lead to an inherent dataset bias in the image creation. Input-level augmentation can provide a solution to this problem by widening the domain space in the source dataset and boost performance on out-of-domain distributions. We provide results from experiments on semantic segmentation on prostate data and corruption robustness on cardiac data which demonstrate the effectiveness of our approach. Our method increases performance in both tasks, without added cost to training time or resources.
Ensuring UAV Safety: A Vision-only and Real-time Framework for Collision Avoidance Through Object Detection, Tracking, and Distance Estimation
May 16, 2024In the last twenty years, unmanned aerial vehicles (UAVs) have garnered growing interest due to their expanding applications in both military and civilian domains. Detecting non-cooperative aerial vehicles with efficiency and estimating collisions accurately are pivotal for achieving fully autonomous aircraft and facilitating Advanced Air Mobility (AAM). This paper presents a deep-learning framework that utilizes optical sensors for the detection, tracking, and distance estimation of non-cooperative aerial vehicles. In implementing this comprehensive sensing framework, the availability of depth information is essential for enabling autonomous aerial vehicles to perceive and navigate around obstacles. In this work, we propose a method for estimating the distance information of a detected aerial object in real time using only the input of a monocular camera. In order to train our deep learning components for the object detection, tracking and depth estimation tasks we utilize the Amazon Airborne Object Tracking (AOT) Dataset. In contrast to previous approaches that integrate the depth estimation module into the object detector, our method formulates the problem as image-to-image translation. We employ a separate lightweight encoder-decoder network for efficient and robust depth estimation. In a nutshell, the object detection module identifies and localizes obstacles, conveying this information to both the tracking module for monitoring obstacle movement and the depth estimation module for calculating distances. Our approach is evaluated on the Airborne Object Tracking (AOT) dataset which is the largest (to the best of our knowledge) air-to-air airborne object dataset.
Common Corruptions for Enhancing and Evaluating Robustness in Air-to-Air Visual Object Detection
May 16, 2024The main barrier to achieving fully autonomous flights lies in autonomous aircraft navigation. Managing non-cooperative traffic presents the most important challenge in this problem. The most efficient strategy for handling non-cooperative traffic is based on monocular video processing through deep learning models. This study contributes to the vision-based deep learning aircraft detection and tracking literature by investigating the impact of data corruption arising from environmental and hardware conditions on the effectiveness of these methods. More specifically, we designed $7$ types of common corruptions for camera inputs taking into account real-world flight conditions. By applying these corruptions to the Airborne Object Tracking (AOT) dataset we constructed the first robustness benchmark dataset named AOT-C for air-to-air aerial object detection. The corruptions included in this dataset cover a wide range of challenging conditions such as adverse weather and sensor noise. The second main contribution of this letter is to present an extensive experimental evaluation involving $8$ diverse object detectors to explore the degradation in the performance under escalating levels of corruptions (domain shifts). Based on the evaluation results, the key observations that emerge are the following: 1) One-stage detectors of the YOLO family demonstrate better robustness, 2) Transformer-based and multi-stage detectors like Faster R-CNN are extremely vulnerable to corruptions, 3) Robustness against corruptions is related to the generalization ability of models. The third main contribution is to present that finetuning on our augmented synthetic data results in improvements in the generalisation ability of the object detector in real-world flight experiments.
Estimating the Robustness Radius for Randomized Smoothing with 100$\times$ Sample Efficiency
Apr 26, 2024Randomized smoothing (RS) has successfully been used to improve the robustness of predictions for deep neural networks (DNNs) by adding random noise to create multiple variations of an input, followed by deciding the consensus. To understand if an RS-enabled DNN is effective in the sampled input domains, it is mandatory to sample data points within the operational design domain, acquire the point-wise certificate regarding robustness radius, and compare it with pre-defined acceptance criteria. Consequently, ensuring that a point-wise robustness certificate for any given data point is obtained relatively cost-effectively is crucial. This work demonstrates that reducing the number of samples by one or two orders of magnitude can still enable the computation of a slightly smaller robustness radius (commonly ~20% radius reduction) with the same confidence. We provide the mathematical foundation for explaining the phenomenon while experimentally showing promising results on the standard CIFAR-10 and ImageNet datasets.
Uncertainty-guided Contrastive Learning for Single Source Domain Generalisation
Mar 14, 2024In the context of single domain generalisation, the objective is for models that have been exclusively trained on data from a single domain to demonstrate strong performance when confronted with various unfamiliar domains. In this paper, we introduce a novel model referred to as Contrastive Uncertainty Domain Generalisation Network (CUDGNet). The key idea is to augment the source capacity in both input and label spaces through the fictitious domain generator and jointly learn the domain invariant representation of each class through contrastive learning. Extensive experiments on two Single Source Domain Generalisation (SSDG) datasets demonstrate the effectiveness of our approach, which surpasses the state-of-the-art single-DG methods by up to $7.08\%$. Our method also provides efficient uncertainty estimation at inference time from a single forward pass through the generator subnetwork.
COVID-19 Computer-aided Diagnosis through AI-assisted CT Imaging Analysis: Deploying a Medical AI System
Mar 12, 2024



Computer-aided diagnosis (CAD) systems stand out as potent aids for physicians in identifying the novel Coronavirus Disease 2019 (COVID-19) through medical imaging modalities. In this paper, we showcase the integration and reliable and fast deployment of a state-of-the-art AI system designed to automatically analyze CT images, offering infection probability for the swift detection of COVID-19. The suggested system, comprising both classification and segmentation components, is anticipated to reduce physicians' detection time and enhance the overall efficiency of COVID-19 detection. We successfully surmounted various challenges, such as data discrepancy and anonymisation, testing the time-effectiveness of the model, and data security, enabling reliable and scalable deployment of the system on both cloud and edge environments. Additionally, our AI system assigns a probability of infection to each 3D CT scan and enhances explainability through anchor set similarity, facilitating timely confirmation and segregation of infected patients by physicians.
Domain adaptation, Explainability & Fairness in AI for Medical Image Analysis: Diagnosis of COVID-19 based on 3-D Chest CT-scans
Mar 10, 2024



The paper presents the DEF-AI-MIA COV19D Competition, which is organized in the framework of the 'Domain adaptation, Explainability, Fairness in AI for Medical Image Analysis (DEF-AI-MIA)' Workshop of the 2024 Computer Vision and Pattern Recognition (CVPR) Conference. The Competition is the 4th in the series, following the first three Competitions held in the framework of ICCV 2021, ECCV 2022 and ICASSP 2023 International Conferences respectively. It includes two Challenges on: i) Covid-19 Detection and ii) Covid-19 Domain Adaptation. The Competition use data from COV19-CT-DB database, which is described in the paper and includes a large number of chest CT scan series. Each chest CT scan series consists of a sequence of 2-D CT slices, the number of which is between 50 and 700. Training, validation and test datasets have been extracted from COV19-CT-DB and provided to the participants in both Challenges. The paper presents the baseline models used in the Challenges and the performance which was obtained respectively.
Self-Supervised Learning for Visual Relationship Detection through Masked Bounding Box Reconstruction
Nov 08, 2023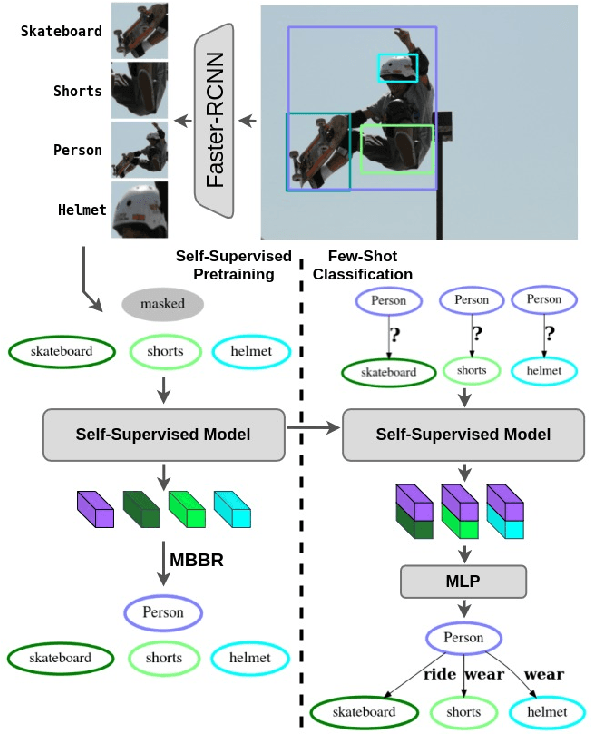
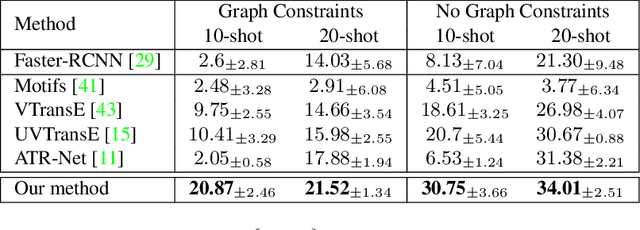
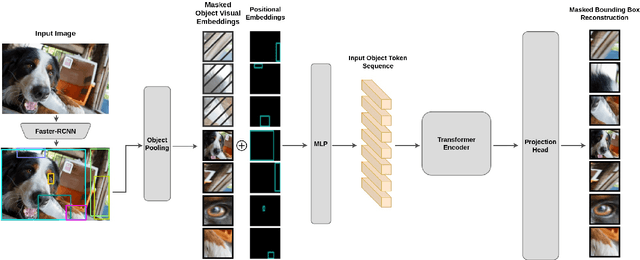
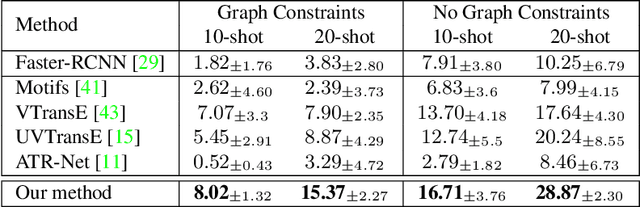
We present a novel self-supervised approach for representation learning, particularly for the task of Visual Relationship Detection (VRD). Motivated by the effectiveness of Masked Image Modeling (MIM), we propose Masked Bounding Box Reconstruction (MBBR), a variation of MIM where a percentage of the entities/objects within a scene are masked and subsequently reconstructed based on the unmasked objects. The core idea is that, through object-level masked modeling, the network learns context-aware representations that capture the interaction of objects within a scene and thus are highly predictive of visual object relationships. We extensively evaluate learned representations, both qualitatively and quantitatively, in a few-shot setting and demonstrate the efficacy of MBBR for learning robust visual representations, particularly tailored for VRD. The proposed method is able to surpass state-of-the-art VRD methods on the Predicate Detection (PredDet) evaluation setting, using only a few annotated samples. We make our code available at https://github.com/deeplab-ai/SelfSupervisedVRD.