 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Affect to Complex Behavior: Advancing Multimodal Human-Centered AI at the 10th ABAW Workshop & Competition
May 24, 2026The 10th Affective & Behavior Analysis in-the-Wild (ABAW) Workshop and Competition, held at CVPR 2026, continues to advance research on modelling, analysis, understanding of human affect and behavior in real-world, unconstrained environments. The workshop maintains its dual structure, comprising both a competition and a paper track. The ABAW Competition introduces a diverse set of challenges targeting key aspects of affective and behavioral understanding, including continuous affect (valence-arousal) estimation, discrete affect (expression and action unit) recognition, as well as more complex behavior analysis tasks, such as emotional mimicry intensity estimation, ambivalence/hesitancy recognition and fine-grained violence detection. These challenges are built upon large-scale in-the-wild datasets, providing comprehensive benchmarks for state-of-the-art approaches. In parallel, the paper track presents a wide range of contributions spanning pose, motion & behavior estimation, affect modelling & multimodal learning, benchmarks, datasets & evaluation protocols, fairness, robustness & deployment. Overall, the 10th ABAW Workshop and Competition continues to serve as a key platform for benchmarking, collaboration and innovation, shaping the development of next-generation multimodal, human-centered AI systems.
CoLoRSMamba: Conditional LoRA-Steered Mamba for Supervised Multimodal Violence Detection
Apr 02, 2026Violence detection benefits from audio, but real-world soundscapes can be noisy or weakly related to the visible scene. We present CoLoRSMamba, a directional Video to Audio multimodal architecture that couples VideoMamba and AudioMamba through CLS-guided conditional LoRA. At each layer, the VideoMamba CLS token produces a channel-wise modulation vector and a stabilization gate that adapt the AudioMamba projections responsible for the selective state-space parameters (Delta, B, C), including the step-size pathway, yielding scene-aware audio dynamics without token-level cross-attention. Training combines binary classification with a symmetric AV-InfoNCE objective that aligns clip-level audio and video embeddings. To support fair multimodal evaluation, we curate audio-filtered clip level subsets of the NTU-CCTV and DVD datasets from temporal annotations, retaining only clips with available audio. On these subsets, CoLoRSMamba outperforms representative audio-only, video-only, and multimodal baselines, achieving 88.63% accuracy / 86.24% F1-V on NTU-CCTV and 75.77% accuracy / 72.94% F1-V on DVD. It further offers a favorable accuracy-efficiency tradeoff, surpassing several larger models with fewer parameters and FLOPs.
A Closed-Form Solution for Debiasing Vision-Language Models with Utility Guarantees Across Modalities and Tasks
Mar 13, 2026While Vision-Language Models (VLMs) have achieved remarkable performance across diverse downstream tasks, recent studies have shown that they can inherit social biases from the training data and further propagate them into downstream applications. To address this issue, various debiasing approaches have been proposed, yet most of them aim to improve fairness without having a theoretical guarantee that the utility of the model is preserved. In this paper, we introduce a debiasing method that yields a \textbf{closed-form} solution in the cross-modal space, achieving Pareto-optimal fairness with \textbf{bounded utility losses}. Our method is \textbf{training-free}, requires \textbf{no annotated data}, and can jointly debias both visual and textual modalities across downstream tasks. Extensive experiments show that our method outperforms existing methods in debiasing VLMs across diverse fairness metrics and datasets for both group and \textbf{intersectional} fairness in downstream tasks such as zero-shot image classification, text-to-image retrieval, and text-to-image generation while preserving task performance.
Behaviour4All: in-the-wild Facial Behaviour Analysis Toolkit
Sep 26, 2024
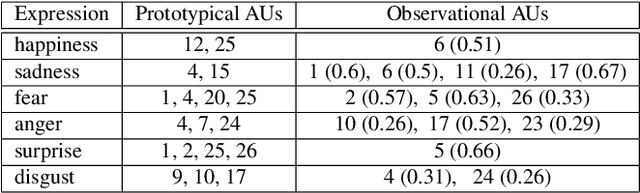
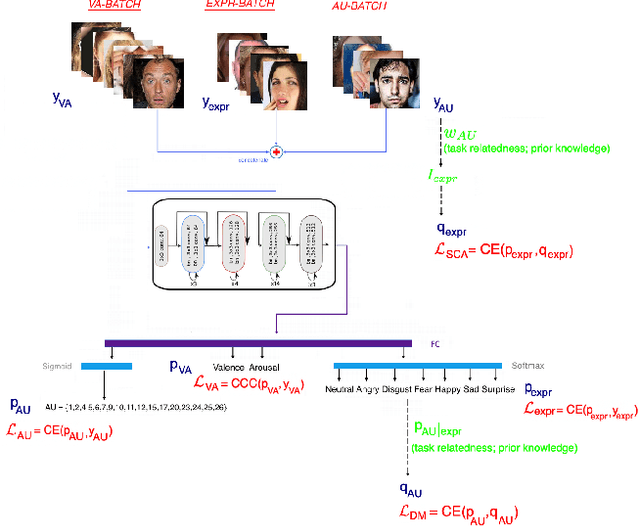
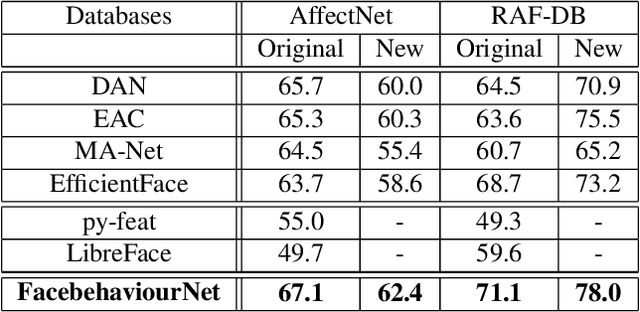
In this paper, we introduce Behavior4All, a comprehensive, open-source toolkit for in-the-wild facial behavior analysis, integrating Face Localization, Valence-Arousal Estimation, Basic Expression Recognition and Action Unit Detection, all within a single framework. Available in both CPU-only and GPU-accelerated versions, Behavior4All leverages 12 large-scale, in-the-wild datasets consisting of over 5 million images from diverse demographic groups. It introduces a novel framework that leverages distribution matching and label co-annotation to address tasks with non-overlapping annotations, encoding prior knowledge of their relatedness. In the largest study of its kind, Behavior4All outperforms both state-of-the-art and toolkits in overall performance as well as fairness across all databases and tasks. It also demonstrates superior generalizability on unseen databases and on compound expression recognition. Finally, Behavior4All is way times faster than other toolkits.
MRAC Track 1: 2nd Workshop on Multimodal, Generative and Responsible Affective Computing
Sep 11, 2024With the rapid advancements in multimodal generative technology, Affective Computing research has provoked discussion about the potential consequences of AI systems equipped with emotional intelligence. Affective Computing involves the design, evaluation, and implementation of Emotion AI and related technologies aimed at improving people's lives. Designing a computational model in affective computing requires vast amounts of multimodal data, including RGB images, video, audio, text, and physiological signals. Moreover, Affective Computing research is deeply engaged with ethical considerations at various stages-from training emotionally intelligent models on large-scale human data to deploying these models in specific applications. Fundamentally, the development of any AI system must prioritize its impact on humans, aiming to augment and enhance human abilities rather than replace them, while drawing inspiration from human intelligence in a safe and responsible manner. The MRAC 2024 Track 1 workshop seeks to extend these principles from controlled, small-scale lab environments to real-world, large-scale contexts, emphasizing responsible development. The workshop also aims to highlight the potential implications of generative technology, along with the ethical consequences of its use, to researchers and industry professionals. To the best of our knowledge, this is the first workshop series to comprehensively address the full spectrum of multimodal, generative affective computing from a responsible AI perspective, and this is the second iteration of this workshop. Webpage: https://react-ws.github.io/2024/
1M-Deepfakes Detection Challenge
Sep 11, 2024



The detection and localization of deepfake content, particularly when small fake segments are seamlessly mixed with real videos, remains a significant challenge in the field of digital media security. Based on the recently released AV-Deepfake1M dataset, which contains more than 1 million manipulated videos across more than 2,000 subjects, we introduce the 1M-Deepfakes Detection Challenge. This challenge is designed to engage the research community in developing advanced methods for detecting and localizing deepfake manipulations within the large-scale high-realistic audio-visual dataset. The participants can access the AV-Deepfake1M dataset and are required to submit their inference results for evaluation across the metrics for detection or localization tasks. The methodologies developed through the challenge will contribute to the development of next-generation deepfake detection and localization systems. Evaluation scripts, baseline models, and accompanying code will be available on https://github.com/ControlNet/AV-Deepfake1M.
Rethinking Affect Analysis: A Protocol for Ensuring Fairness and Consistency
Aug 07, 2024



Evaluating affect analysis methods presents challenges due to inconsistencies in database partitioning and evaluation protocols, leading to unfair and biased results. Previous studies claim continuous performance improvements, but our findings challenge such assertions. Using these insights, we propose a unified protocol for database partitioning that ensures fairness and comparability. We provide detailed demographic annotations (in terms of race, gender and age), evaluation metrics, and a common framework for expression recognition, action unit detection and valence-arousal estimation. We also rerun the methods with the new protocol and introduce a new leaderboards to encourage future research in affect recognition with a fairer comparison. Our annotations, code, and pre-trained models are available on \hyperlink{https://github.com/dkollias/Fair-Consistent-Affect-Analysis}{Github}.
SAM2CLIP2SAM: Vision Language Model for Segmentation of 3D CT Scans for Covid-19 Detection
Jul 23, 2024This paper presents a new approach for effective segmentation of images that can be integrated into any model and methodology; the paradigm that we choose is classification of medical images (3-D chest CT scans) for Covid-19 detection. Our approach includes a combination of vision-language models that segment the CT scans, which are then fed to a deep neural architecture, named RACNet, for Covid-19 detection. In particular, a novel framework, named SAM2CLIP2SAM, is introduced for segmentation that leverages the strengths of both Segment Anything Model (SAM) and Contrastive Language-Image Pre-Training (CLIP) to accurately segment the right and left lungs in CT scans, subsequently feeding these segmented outputs into RACNet for classification of COVID-19 and non-COVID-19 cases. At first, SAM produces multiple part-based segmentation masks for each slice in the CT scan; then CLIP selects only the masks that are associated with the regions of interest (ROIs), i.e., the right and left lungs; finally SAM is given these ROIs as prompts and generates the final segmentation mask for the lungs. Experiments are presented across two Covid-19 annotated databases which illustrate the improved performance obtained when our method has been used for segmentation of the CT scans.
Robust Facial Reactions Generation: An Emotion-Aware Framework with Modality Compensation
Jul 23, 2024The objective of the Multiple Appropriate Facial Reaction Generation (MAFRG) task is to produce contextually appropriate and diverse listener facial behavioural responses based on the multimodal behavioural data of the conversational partner (i.e., the speaker). Current methodologies typically assume continuous availability of speech and facial modality data, neglecting real-world scenarios where these data may be intermittently unavailable, which often results in model failures. Furthermore, despite utilising advanced deep learning models to extract information from the speaker's multimodal inputs, these models fail to adequately leverage the speaker's emotional context, which is vital for eliciting appropriate facial reactions from human listeners. To address these limitations, we propose an Emotion-aware Modality Compensatory (EMC) framework. This versatile solution can be seamlessly integrated into existing models, thereby preserving their advantages while significantly enhancing performance and robustness in scenarios with missing modalities. Our framework ensures resilience when faced with missing modality data through the Compensatory Modality Alignment (CMA) module. It also generates more appropriate emotion-aware reactions via the Emotion-aware Attention (EA) module, which incorporates the speaker's emotional information throughout the entire encoding and decoding process. Experimental results demonstrate that our framework improves the appropriateness metric FRCorr by an average of 57.2\% compared to the original model structure. In scenarios where speech modality data is missing, the performance of appropriate generation shows an improvement, and when facial data is missing, it only exhibits minimal degradation.
7th ABAW Competition: Multi-Task Learning and Compound Expression Recognition
Jul 04, 2024



This paper describes the 7th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with ECCV 2024. The 7th ABAW Competition addresses novel challenges in understanding human expressions and behaviors, crucial for the development of human-centered technologies. The Competition comprises of two sub-challenges: i) Multi-Task Learning (the goal is to learn at the same time, in a multi-task learning setting, to estimate two continuous affect dimensions, valence and arousal, to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), and to detect 12 Action Units); and ii) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes). s-Aff-Wild2, which is a static version of the A/V Aff-Wild2 database and contains annotations for valence-arousal, expressions and Action Units, is utilized for the purposes of the Multi-Task Learning Challenge; a part of C-EXPR-DB, which is an A/V in-the-wild database with compound expression annotations, is utilized for the purposes of the Compound Expression Recognition Challenge. In this paper, we introduce the two challenges, detailing their datasets and the protocols followed for each. We also outline the evaluation metrics, and highlight the baseline systems and their results. Additional information about the competition can be found at \url{https://affective-behavior-analysis-in-the-wild.github.io/7th}.