 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehaviour4All: in-the-wild Facial Behaviour Analysis Toolkit
Sep 26, 2024
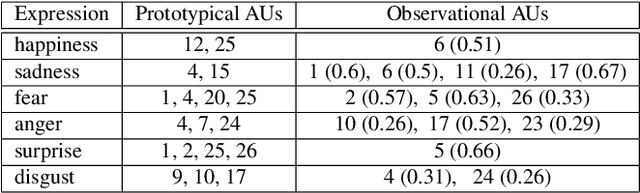
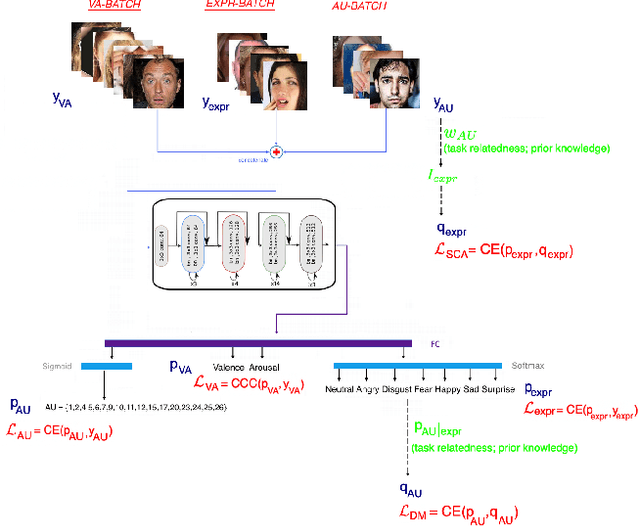
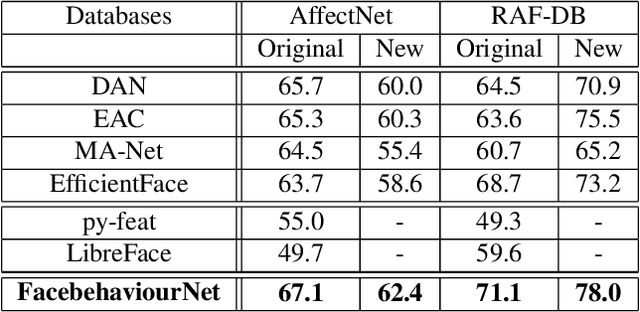
In this paper, we introduce Behavior4All, a comprehensive, open-source toolkit for in-the-wild facial behavior analysis, integrating Face Localization, Valence-Arousal Estimation, Basic Expression Recognition and Action Unit Detection, all within a single framework. Available in both CPU-only and GPU-accelerated versions, Behavior4All leverages 12 large-scale, in-the-wild datasets consisting of over 5 million images from diverse demographic groups. It introduces a novel framework that leverages distribution matching and label co-annotation to address tasks with non-overlapping annotations, encoding prior knowledge of their relatedness. In the largest study of its kind, Behavior4All outperforms both state-of-the-art and toolkits in overall performance as well as fairness across all databases and tasks. It also demonstrates superior generalizability on unseen databases and on compound expression recognition. Finally, Behavior4All is way times faster than other toolkits.
Robust Facial Reactions Generation: An Emotion-Aware Framework with Modality Compensation
Jul 23, 2024The objective of the Multiple Appropriate Facial Reaction Generation (MAFRG) task is to produce contextually appropriate and diverse listener facial behavioural responses based on the multimodal behavioural data of the conversational partner (i.e., the speaker). Current methodologies typically assume continuous availability of speech and facial modality data, neglecting real-world scenarios where these data may be intermittently unavailable, which often results in model failures. Furthermore, despite utilising advanced deep learning models to extract information from the speaker's multimodal inputs, these models fail to adequately leverage the speaker's emotional context, which is vital for eliciting appropriate facial reactions from human listeners. To address these limitations, we propose an Emotion-aware Modality Compensatory (EMC) framework. This versatile solution can be seamlessly integrated into existing models, thereby preserving their advantages while significantly enhancing performance and robustness in scenarios with missing modalities. Our framework ensures resilience when faced with missing modality data through the Compensatory Modality Alignment (CMA) module. It also generates more appropriate emotion-aware reactions via the Emotion-aware Attention (EA) module, which incorporates the speaker's emotional information throughout the entire encoding and decoding process. Experimental results demonstrate that our framework improves the appropriateness metric FRCorr by an average of 57.2\% compared to the original model structure. In scenarios where speech modality data is missing, the performance of appropriate generation shows an improvement, and when facial data is missing, it only exhibits minimal degradation.