 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepFace: Refining Closed-Set Noise with Progressive Label Correction for Face Recognition
Dec 16, 2024Face recognition has made remarkable strides, driven by the expanding scale of datasets, advancements in various backbone and discriminative losses. However, face recognition performance is heavily affected by the label noise, especially closed-set noise. While numerous studies have focused on handling label noise, addressing closed-set noise still poses challenges. This paper identifies this challenge as training isn't robust to noise at the early-stage training, and necessitating an appropriate learning strategy for samples with low confidence, which are often misclassified as closed-set noise in later training phases. To address these issues, we propose a new framework to stabilize the training at early stages and split the samples into clean, ambiguous and noisy groups which are devised with separate training strategies. Initially, we employ generated auxiliary closed-set noisy samples to enable the model to identify noisy data at the early stages of training. Subsequently, we introduce how samples are split into clean, ambiguous and noisy groups by their similarity to the positive and nearest negative centers. Then we perform label fusion for ambiguous samples by incorporating accumulated model predictions. Finally, we apply label smoothing within the closed set, adjusting the label to a point between the nearest negative class and the initially assigned label. Extensive experiments validate the effectiveness of our method on mainstream face datasets, achieving state-of-the-art results. The code will be released upon acceptance.
CemiFace: Center-based Semi-hard Synthetic Face Generation for Face Recognition
Sep 27, 2024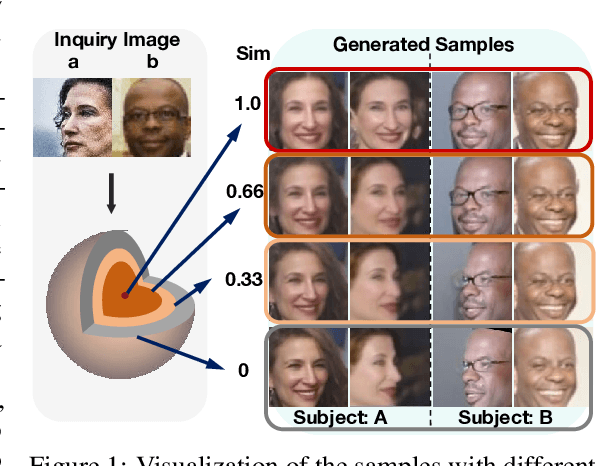
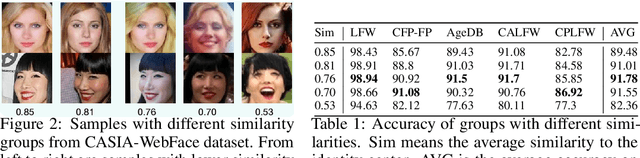
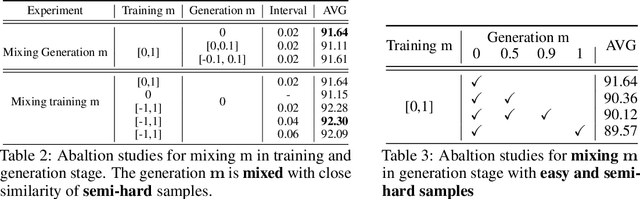
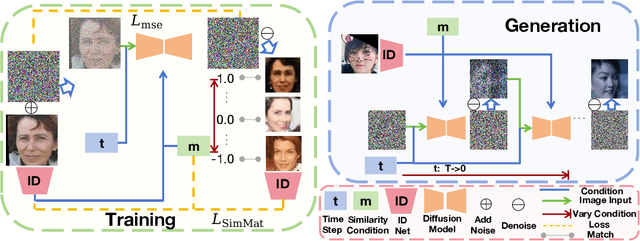
Privacy issue is a main concern in developing face recognition techniques. Although synthetic face images can partially mitigate potential legal risks while maintaining effective face recognition (FR) performance, FR models trained by face images synthesized by existing generative approaches frequently suffer from performance degradation problems due to the insufficient discriminative quality of these synthesized samples. In this paper, we systematically investigate what contributes to solid face recognition model training, and reveal that face images with certain degree of similarities to their identity centers show great effectiveness in the performance of trained FR models. Inspired by this, we propose a novel diffusion-based approach (namely Center-based Semi-hard Synthetic Face Generation (CemiFace)) which produces facial samples with various levels of similarity to the subject center, thus allowing to generate face datasets containing effective discriminative samples for training face recognition. Experimental results show that with a modest degree of similarity, training on the generated dataset can produce competitive performance compared to previous generation methods.
Robust Facial Reactions Generation: An Emotion-Aware Framework with Modality Compensation
Jul 23, 2024The objective of the Multiple Appropriate Facial Reaction Generation (MAFRG) task is to produce contextually appropriate and diverse listener facial behavioural responses based on the multimodal behavioural data of the conversational partner (i.e., the speaker). Current methodologies typically assume continuous availability of speech and facial modality data, neglecting real-world scenarios where these data may be intermittently unavailable, which often results in model failures. Furthermore, despite utilising advanced deep learning models to extract information from the speaker's multimodal inputs, these models fail to adequately leverage the speaker's emotional context, which is vital for eliciting appropriate facial reactions from human listeners. To address these limitations, we propose an Emotion-aware Modality Compensatory (EMC) framework. This versatile solution can be seamlessly integrated into existing models, thereby preserving their advantages while significantly enhancing performance and robustness in scenarios with missing modalities. Our framework ensures resilience when faced with missing modality data through the Compensatory Modality Alignment (CMA) module. It also generates more appropriate emotion-aware reactions via the Emotion-aware Attention (EA) module, which incorporates the speaker's emotional information throughout the entire encoding and decoding process. Experimental results demonstrate that our framework improves the appropriateness metric FRCorr by an average of 57.2\% compared to the original model structure. In scenarios where speech modality data is missing, the performance of appropriate generation shows an improvement, and when facial data is missing, it only exhibits minimal degradation.
LAFS: Landmark-based Facial Self-supervised Learning for Face Recognition
Mar 13, 2024In this work we focus on learning facial representations that can be adapted to train effective face recognition models, particularly in the absence of labels. Firstly, compared with existing labelled face datasets, a vastly larger magnitude of unlabeled faces exists in the real world. We explore the learning strategy of these unlabeled facial images through self-supervised pretraining to transfer generalized face recognition performance. Moreover, motivated by one recent finding, that is, the face saliency area is critical for face recognition, in contrast to utilizing random cropped blocks of images for constructing augmentations in pretraining, we utilize patches localized by extracted facial landmarks. This enables our method - namely LAndmark-based Facial Self-supervised learning LAFS), to learn key representation that is more critical for face recognition. We also incorporate two landmark-specific augmentations which introduce more diversity of landmark information to further regularize the learning. With learned landmark-based facial representations, we further adapt the representation for face recognition with regularization mitigating variations in landmark positions. Our method achieves significant improvement over the state-of-the-art on multiple face recognition benchmarks, especially on more challenging few-shot scenarios.
Part-based Face Recognition with Vision Transformers
Nov 30, 2022Holistic methods using CNNs and margin-based losses have dominated research on face recognition. In this work, we depart from this setting in two ways: (a) we employ the Vision Transformer as an architecture for training a very strong baseline for face recognition, simply called fViT, which already surpasses most state-of-the-art face recognition methods. (b) Secondly, we capitalize on the Transformer's inherent property to process information (visual tokens) extracted from irregular grids to devise a pipeline for face recognition which is reminiscent of part-based face recognition methods. Our pipeline, called part fViT, simply comprises a lightweight network to predict the coordinates of facial landmarks followed by the Vision Transformer operating on patches extracted from the predicted landmarks, and it is trained end-to-end with no landmark supervision. By learning to extract discriminative patches, our part-based Transformer further boosts the accuracy of our Vision Transformer baseline achieving state-of-the-art accuracy on several face recognition benchmarks.