 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestore, Assess, Repeat: A Unified Framework for Iterative Image Restoration
Mar 27, 2026Image restoration aims to recover high quality images from inputs degraded by various factors, such as adverse weather, blur, or low light. While recent studies have shown remarkable progress across individual or unified restoration tasks, they still suffer from limited generalization and inefficiency when handling unknown or composite degradations. To address these limitations, we propose RAR, a Restore, Assess and Repeat process, that integrates Image Quality Assessment (IQA) and Image Restoration (IR) into a unified framework to iteratively and efficiently achieve high quality image restoration. Specifically, we introduce a restoration process that operates entirely in the latent domain to jointly perform degradation identification, image restoration, and quality verification. The resulting model is fully trainable end to end and allows for an all-in-one assess and restore approach that dynamically adapts the restoration process. Also, the tight integration of IQA and IR into a unified model minimizes the latency and information loss that typically arises from keeping the two modules disjoint, (e.g. during image and/or text decoding). Extensive experiments show that our approach consistent improvements under single, unknown and composite degradations, thereby establishing a new state-of-the-art.
VISion On Request: Enhanced VLLM efficiency with sparse, dynamically selected, vision-language interactions
Mar 24, 2026Existing approaches for improving the efficiency of Large Vision-Language Models (LVLMs) are largely based on the concept of visual token reduction. This approach, however, creates an information bottleneck that impairs performance, especially on challenging tasks that require fine-grained understanding and reasoning. In this work, we challenge this paradigm by introducing VISion On Request (VISOR), a method that reduces inference cost without discarding visual information. Instead of compressing the image, VISOR improves efficiency by sparsifying the interaction between image and text tokens. Specifically, the language model attends to the full set of high-resolution visual tokens through a small, strategically placed set of attention layers: general visual context is provided by efficient cross-attention between text-image, while a few well-placed and dynamically selected self-attention layers refine the visual representations themselves, enabling complex, high-resolution reasoning when needed. Based on this principle, we first train a single universal network on a range of computational budgets by varying the number of self-attention layers, and then introduce a lightweight policy mechanism that dynamically allocates visual computation based on per-sample complexity. Extensive experiments show that VISOR drastically reduces computational cost while matching or exceeding state-of-the-art results across a diverse suite of benchmarks, and excels in challenging tasks that require detailed visual understanding.
CycleCap: Improving VLMs Captioning Performance via Self-Supervised Cycle Consistency Fine-Tuning
Mar 18, 2026Visual-Language Models (VLMs) have achieved remarkable progress in image captioning, visual question answering, and visual reasoning. Yet they remain prone to vision-language misalignment, often producing overly generic or hallucinated descriptions. Existing approaches address this via instruction tuning-requiring costly, large-scale annotated datasets or via complex test-time frameworks for caption refinement. In this work, we revisit image-text alignment through the lens of cycle consistency: given an image and a caption generated by an image-to-text model, the backward mapping through a text-to-image model should reconstruct an image that closely matches the original. In our setup, a VLM serves as the image-to-text component, while a pre-trained text-to-image model closes the loop by reconstructing the image from the generated caption. Building on this, we introduce CycleCap, a fine-tuning scheme to improve image captioning using Group Relative Policy Optimization (GRPO) with a reward based on the similarity between the original and reconstructed images, computed on-the-fly. Unlike previous work that uses cycle consistency loss for preference dataset construction, our method leverages cycle consistency directly as a self-supervised training signal. This enables the use of raw images alone, eliminating the need for curated image-text datasets, while steering the VLM to produce more accurate and grounded text descriptions. Applied to four VLMs ranging from 1B to 7B parameters, CycleCap yields consistent improvements across captioning and hallucination benchmarks, surpassing state-of-the-art methods that rely on supervised cycle consistency training.
Deconstructing the Failure of Ideal Noise Correction: A Three-Pillar Diagnosis
Mar 13, 2026Statistically consistent methods based on the noise transition matrix ($T$) offer a theoretically grounded solution to Learning with Noisy Labels (LNL), with guarantees of convergence to the optimal clean-data classifier. In practice, however, these methods are often outperformed by empirical approaches such as sample selection, and this gap is usually attributed to the difficulty of accurately estimating $T$. The common assumption is that, given a perfect $T$, noise-correction methods would recover their theoretical advantage. In this work, we put this longstanding hypothesis to a decisive test. We conduct experiments under idealized conditions, providing correction methods with a perfect, oracle transition matrix. Even under these ideal conditions, we observe that these methods still suffer from performance collapse during training. This compellingly demonstrates that the failure is not fundamentally a $T$-estimation problem, but stems from a more deeply rooted flaw. To explain this behaviour, we provide a unified analysis that links three levels: macroscopic convergence states, microscopic optimisation dynamics, and information-theoretic limits on what can be learned from noisy labels. Together, these results give a formal account of why ideal noise correction fails and offer concrete guidance for designing more reliable methods for learning with noisy labels.
More Images, More Problems? A Controlled Analysis of VLM Failure Modes
Jan 12, 2026Large Vision Language Models (LVLMs) have demonstrated remarkable capabilities, yet their proficiency in understanding and reasoning over multiple images remains largely unexplored. While existing benchmarks have initiated the evaluation of multi-image models, a comprehensive analysis of their core weaknesses and their causes is still lacking. In this work, we introduce MIMIC (Multi-Image Model Insights and Challenges), a new benchmark designed to rigorously evaluate the multi-image capabilities of LVLMs. Using MIMIC, we conduct a series of diagnostic experiments that reveal pervasive issues: LVLMs often fail to aggregate information across images and struggle to track or attend to multiple concepts simultaneously. To address these failures, we propose two novel complementary remedies. On the data side, we present a procedural data-generation strategy that composes single-image annotations into rich, targeted multi-image training examples. On the optimization side, we analyze layer-wise attention patterns and derive an attention-masking scheme tailored for multi-image inputs. Experiments substantially improved cross-image aggregation, while also enhancing performance on existing multi-image benchmarks, outperforming prior state of the art across tasks. Data and code will be made available at https://github.com/anurag-198/MIMIC.
Multi-scale Image Super Resolution with a Single Auto-Regressive Model
Jun 05, 2025In this paper we tackle Image Super Resolution (ISR), using recent advances in Visual Auto-Regressive (VAR) modeling. VAR iteratively estimates the residual in latent space between gradually increasing image scales, a process referred to as next-scale prediction. Thus, the strong priors learned during pre-training align well with the downstream task (ISR). To our knowledge, only VARSR has exploited this synergy so far, showing promising results. However, due to the limitations of existing residual quantizers, VARSR works only at a fixed resolution, i.e. it fails to map intermediate outputs to the corresponding image scales. Additionally, it relies on a 1B transformer architecture (VAR-d24), and leverages a large-scale private dataset to achieve state-of-the-art results. We address these limitations through two novel components: a) a Hierarchical Image Tokenization approach with a multi-scale image tokenizer that progressively represents images at different scales while simultaneously enforcing token overlap across scales, and b) a Direct Preference Optimization (DPO) regularization term that, relying solely on the LR and HR tokenizations, encourages the transformer to produce the latter over the former. To the best of our knowledge, this is the first time a quantizer is trained to force semantically consistent residuals at different scales, and the first time that preference-based optimization is used to train a VAR. Using these two components, our model can denoise the LR image and super-resolve at half and full target upscale factors in a single forward pass. Additionally, we achieve \textit{state-of-the-art results on ISR}, while using a small model (300M params vs ~1B params of VARSR), and without using external training data.
Fwd2Bot: LVLM Visual Token Compression with Double Forward Bottleneck
Mar 27, 2025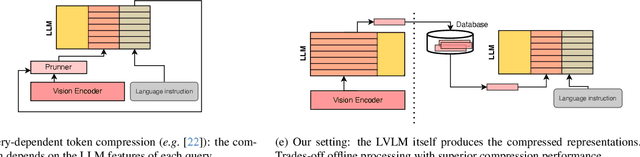
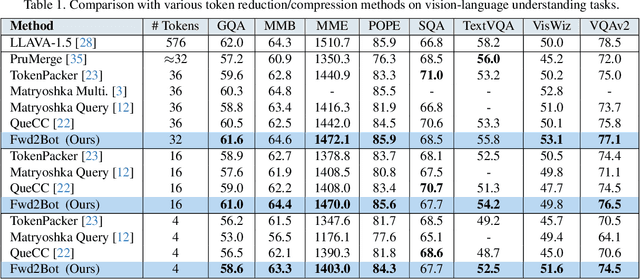
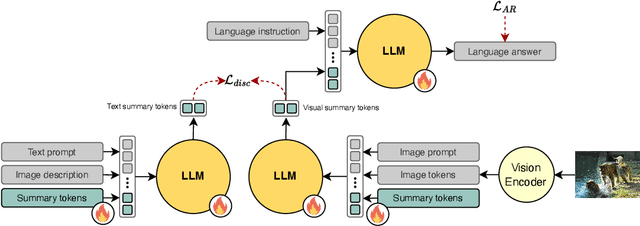
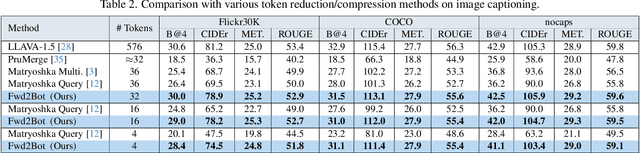
In this work, we aim to compress the vision tokens of a Large Vision Language Model (LVLM) into a representation that is simultaneously suitable for (a) generative and (b) discriminative tasks, (c) is nearly lossless, and (d) is storage-efficient. We propose a novel compression approach, called Fwd2Bot, that uses the LVLM itself to compress the visual information in a task-agnostic manner. At the core of Fwd2bot there exists a "double-forward pass" training strategy, whereby, during the first forward pass, the LLM (of the LVLM) creates a bottleneck by condensing the visual information into a small number of summary tokens. Then, using the same LLM, the second forward pass processes the language instruction(s) alongside the summary tokens, used as a direct replacement for the image ones. The training signal is provided by two losses: an autoregressive one applied after the second pass that provides a direct optimization objective for compression, and a contrastive loss, applied after the first pass, that further boosts the representation strength, especially for discriminative tasks. The training is further enhanced by stage-specific adapters. We accompany the proposed method by an in-depth ablation study. Overall, Fwd2Bot results in highly-informative compressed representations suitable for both generative and discriminative tasks. For generative tasks, we offer a 2x higher compression rate without compromising the generative capabilities, setting a new state-of-the-art result. For discriminative tasks, we set a new state-of-the-art on image retrieval and compositionality.
Edge-SD-SR: Low Latency and Parameter Efficient On-device Super-Resolution with Stable Diffusion via Bidirectional Conditioning
Dec 09, 2024



There has been immense progress recently in the visual quality of Stable Diffusion-based Super Resolution (SD-SR). However, deploying large diffusion models on computationally restricted devices such as mobile phones remains impractical due to the large model size and high latency. This is compounded for SR as it often operates at high res (e.g. 4Kx3K). In this work, we introduce Edge-SD-SR, the first parameter efficient and low latency diffusion model for image super-resolution. Edge-SD-SR consists of ~169M parameters, including UNet, encoder and decoder, and has a complexity of only ~142 GFLOPs. To maintain a high visual quality on such low compute budget, we introduce a number of training strategies: (i) A novel conditioning mechanism on the low resolution input, coined bidirectional conditioning, which tailors the SD model for the SR task. (ii) Joint training of the UNet and encoder, while decoupling the encodings of the HR and LR images and using a dedicated schedule. (iii) Finetuning the decoder using the UNet's output to directly tailor the decoder to the latents obtained at inference time. Edge-SD-SR runs efficiently on device, e.g. it can upscale a 128x128 patch to 512x512 in 38 msec while running on a Samsung S24 DSP, and of a 512x512 to 2048x2048 (requiring 25 model evaluations) in just ~1.1 sec. Furthermore, we show that Edge-SD-SR matches or even outperforms state-of-the-art SR approaches on the most established SR benchmarks.
Discriminative Fine-tuning of LVLMs
Dec 05, 2024



Contrastively-trained Vision-Language Models (VLMs) like CLIP have become the de facto approach for discriminative vision-language representation learning. However, these models have limited language understanding, often exhibiting a "bag of words" behavior. At the same time, Large Vision-Language Models (LVLMs), which combine vision encoders with LLMs, have been shown capable of detailed vision-language reasoning, yet their autoregressive nature renders them less suitable for discriminative tasks. In this work, we propose to combine "the best of both worlds": a new training approach for discriminative fine-tuning of LVLMs that results in strong discriminative and compositional capabilities. Essentially, our approach converts a generative LVLM into a discriminative one, unlocking its capability for powerful image-text discrimination combined with enhanced language understanding. Our contributions include: (1) A carefully designed training/optimization framework that utilizes image-text pairs of variable length and granularity for training the model with both contrastive and next-token prediction losses. This is accompanied by ablation studies that justify the necessity of our framework's components. (2) A parameter-efficient adaptation method using a combination of soft prompting and LoRA adapters. (3) Significant improvements over state-of-the-art CLIP-like models of similar size, including standard image-text retrieval benchmarks and notable gains in compositionality.
FAM Diffusion: Frequency and Attention Modulation for High-Resolution Image Generation with Stable Diffusion
Nov 27, 2024



Diffusion models are proficient at generating high-quality images. They are however effective only when operating at the resolution used during training. Inference at a scaled resolution leads to repetitive patterns and structural distortions. Retraining at higher resolutions quickly becomes prohibitive. Thus, methods enabling pre-existing diffusion models to operate at flexible test-time resolutions are highly desirable. Previous works suffer from frequent artifacts and often introduce large latency overheads. We propose two simple modules that combine to solve these issues. We introduce a Frequency Modulation (FM) module that leverages the Fourier domain to improve the global structure consistency, and an Attention Modulation (AM) module which improves the consistency of local texture patterns, a problem largely ignored in prior works. Our method, coined Fam diffusion, can seamlessly integrate into any latent diffusion model and requires no additional training. Extensive qualitative results highlight the effectiveness of our method in addressing structural and local artifacts, while quantitative results show state-of-the-art performance. Also, our method avoids redundant inference tricks for improved consistency such as patch-based or progressive generation, leading to negligible latency overheads.