 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse-designed nanophotonic neural network accelerators for ultra-compact optical computing
Jun 06, 2025Inverse-designed nanophotonic devices offer promising solutions for analog optical computation. High-density photonic integration is critical for scaling such architectures toward more complex computational tasks and large-scale applications. Here, we present an inverse-designed photonic neural network (PNN) accelerator on a high-index contrast material platform, enabling ultra-compact and energy-efficient optical computing. Our approach introduces a wave-based inverse-design method based on three dimensional finite-difference time-domain (3D-FDTD) simulations, exploiting the linearity of Maxwell's equations to reconstruct arbitrary spatial fields through optical coherence. By decoupling the forward-pass process into linearly separable simulations, our approach is highly amenable to computational parallelism, making it particularly well suited for acceleration using graphics processing units (GPUs) and other parallel computing platforms, thereby enhancing scalability across large problem domains. We fabricate and experimentally validate two inverse-designed PNN accelerators on the silicon-on-insulator platform, achieving on-chip MNIST and MedNIST classification accuracies of 89% and 90% respectively, within ultra-compact footprints of just 20 $\times$ 20 $\mu$m$^{2}$ and 30 $\times$ 20 $\mu$m$^{2}$. Our results establish a scalable and energy-efficient platform for analog photonic computing, effectively bridging inverse nanophotonic design with high-performance optical information processing.
MM2Latent: Text-to-facial image generation and editing in GANs with multimodal assistance
Sep 17, 2024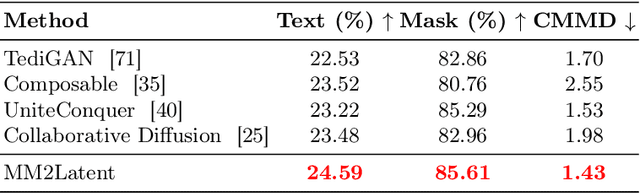
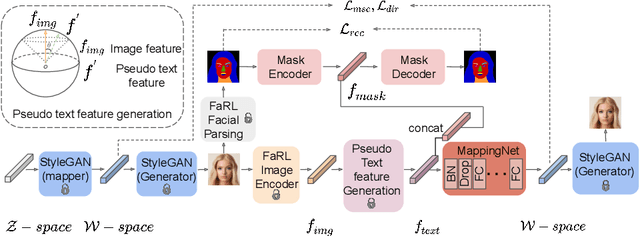
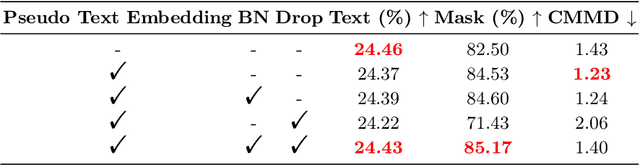

Generating human portraits is a hot topic in the image generation area, e.g. mask-to-face generation and text-to-face generation. However, these unimodal generation methods lack controllability in image generation. Controllability can be enhanced by exploring the advantages and complementarities of various modalities. For instance, we can utilize the advantages of text in controlling diverse attributes and masks in controlling spatial locations. Current state-of-the-art methods in multimodal generation face limitations due to their reliance on extensive hyperparameters, manual operations during the inference stage, substantial computational demands during training and inference, or inability to edit real images. In this paper, we propose a practical framework - MM2Latent - for multimodal image generation and editing. We use StyleGAN2 as our image generator, FaRL for text encoding, and train an autoencoders for spatial modalities like mask, sketch and 3DMM. We propose a strategy that involves training a mapping network to map the multimodal input into the w latent space of StyleGAN. The proposed framework 1) eliminates hyperparameters and manual operations in the inference stage, 2) ensures fast inference speeds, and 3) enables the editing of real images. Extensive experiments demonstrate that our method exhibits superior performance in multimodal image generation, surpassing recent GAN- and diffusion-based methods. Also, it proves effective in multimodal image editing and is faster than GAN- and diffusion-based methods. We make the code publicly available at: https://github.com/Open-Debin/MM2Latent
Shallow Bayesian Meta Learning for Real-World Few-Shot Recognition
Jan 08, 2021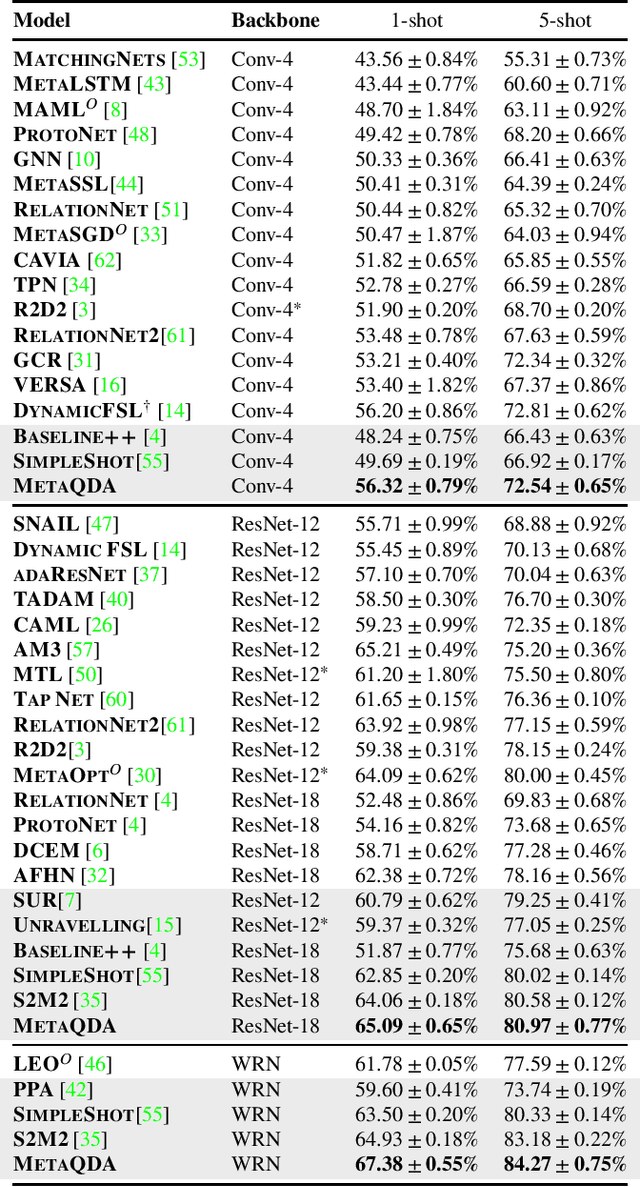
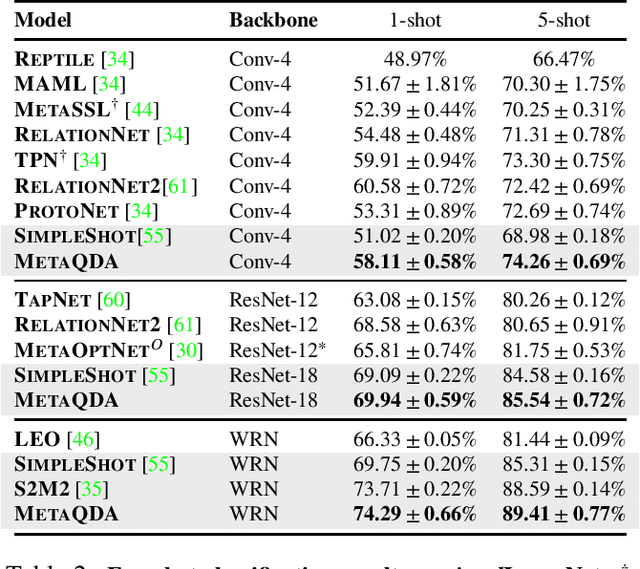
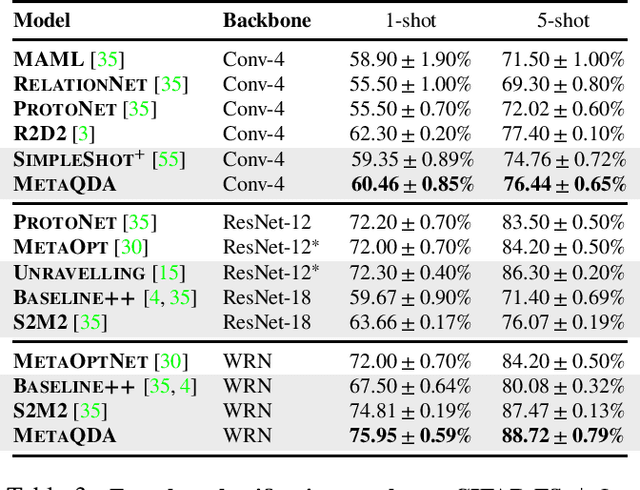
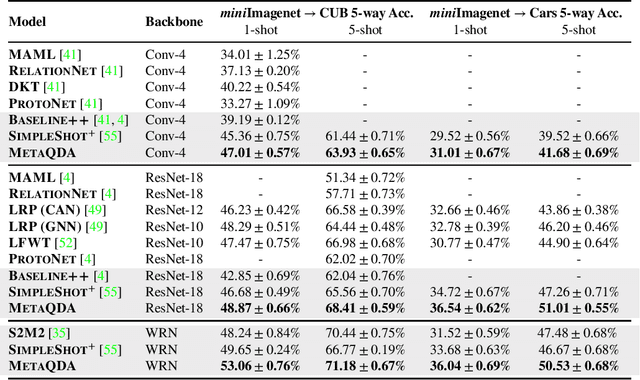
Current state-of-the-art few-shot learners focus on developing effective training procedures for feature representations, before using simple, e.g. nearest centroid, classifiers. In this paper we take an orthogonal approach that is agnostic to the features used, and focus exclusively on meta-learning the actual classifier layer. Specifically, we introduce MetaQDA, a Bayesian meta-learning generalisation of the classic quadratic discriminant analysis. This setup has several benefits of interest to practitioners: meta-learning is fast and memory efficient, without the need to fine-tune features. It is agnostic to the off-the-shelf features chosen, and thus will continue to benefit from advances in feature representations. Empirically, it leads to robust performance in cross-domain few-shot learning and, crucially for real-world applications, it leads to better uncertainty calibration in predictions.
Exploring Emotion Features and Fusion Strategies for Audio-Video Emotion Recognition
Dec 27, 2020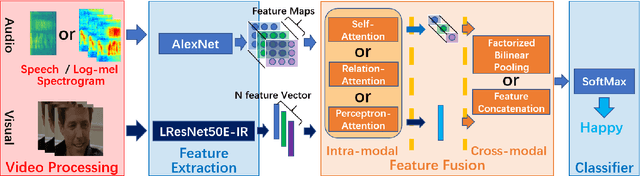
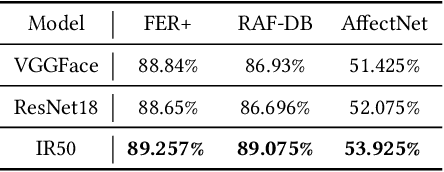
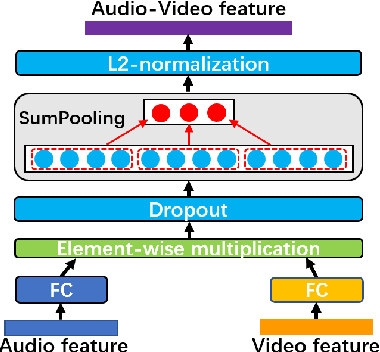
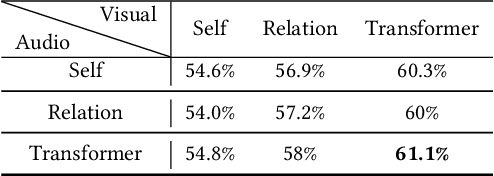
The audio-video based emotion recognition aims to classify a given video into basic emotions. In this paper, we describe our approaches in EmotiW 2019, which mainly explores emotion features and feature fusion strategies for audio and visual modality. For emotion features, we explore audio feature with both speech-spectrogram and Log Mel-spectrogram and evaluate several facial features with different CNN models and different emotion pretrained strategies. For fusion strategies, we explore intra-modal and cross-modal fusion methods, such as designing attention mechanisms to highlights important emotion feature, exploring feature concatenation and factorized bilinear pooling (FBP) for cross-modal feature fusion. With careful evaluation, we obtain 65.5% on the AFEW validation set and 62.48% on the test set and rank third in the challenge.
frame attention networks for facial expression recognition in videos
Jun 29, 2019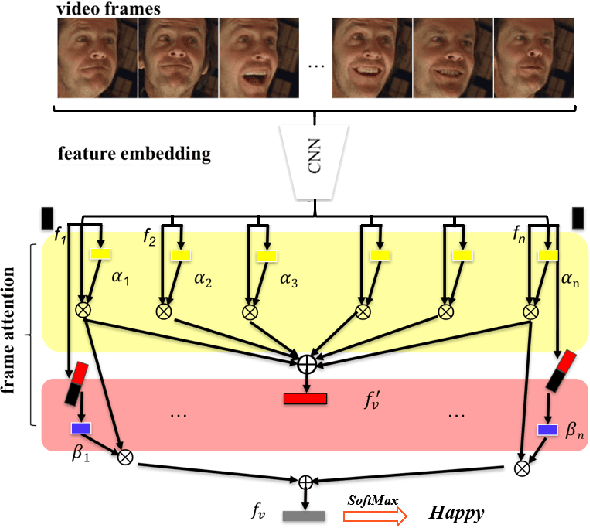

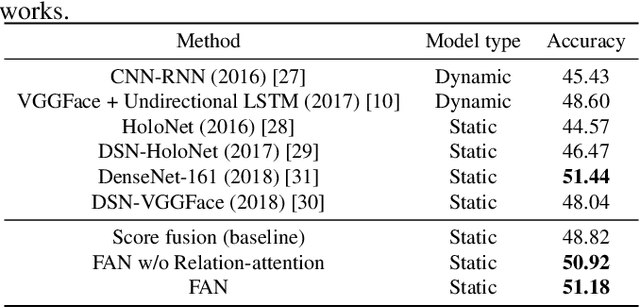
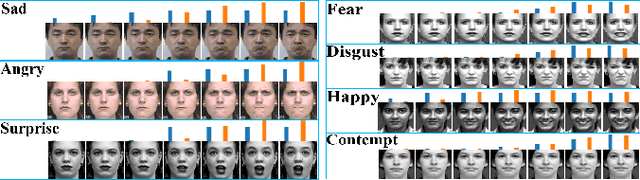
The video-based facial expression recognition aims to classify a given video into several basic emotions. How to integrate facial features of individual frames is crucial for this task. In this paper, we propose the Frame Attention Networks (FAN), to automatically highlight some discriminative frames in an end-to-end framework. The network takes a video with a variable number of face images as its input and produces a fixed-dimension representation. The whole network is composed of two modules. The feature embedding module is a deep Convolutional Neural Network (CNN) which embeds face images into feature vectors. The frame attention module learns multiple attention weights which are used to adaptively aggregate the feature vectors to form a single discriminative video representation. We conduct extensive experiments on CK+ and AFEW8.0 datasets. Our proposed FAN shows superior performance compared to other CNN based methods and achieves state-of-the-art performance on CK+.
Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition
May 10, 2019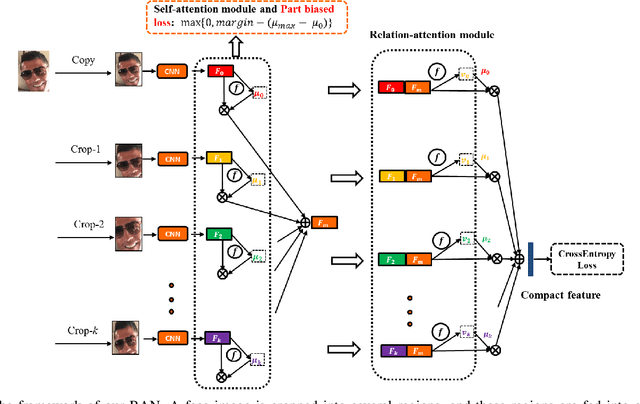
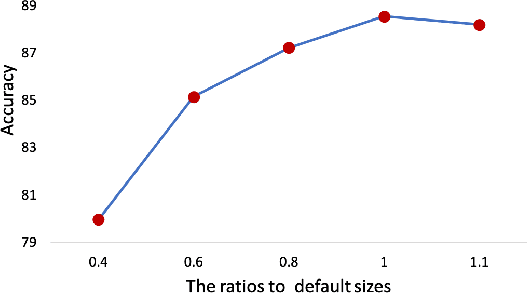
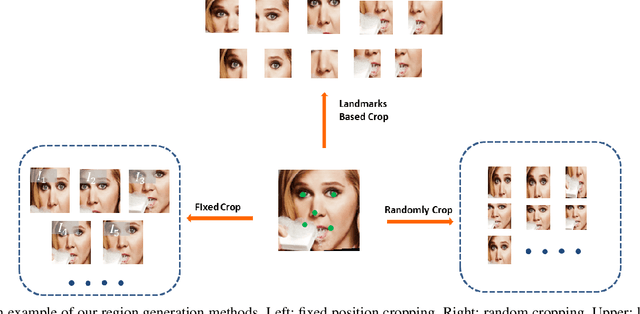

Occlusion and pose variations, which can change facial appearance significantly, are two major obstacles for automatic Facial Expression Recognition (FER). Though automatic FER has made substantial progresses in the past few decades, occlusion-robust and pose-invariant issues of FER have received relatively less attention, especially in real-world scenarios. This paper addresses the real-world pose and occlusion robust FER problem with three-fold contributions. First, to stimulate the research of FER under real-world occlusions and variant poses, we build several in-the-wild facial expression datasets with manual annotations for the community. Second, we propose a novel Region Attention Network (RAN), to adaptively capture the importance of facial regions for occlusion and pose variant FER. The RAN aggregates and embeds varied number of region features produced by a backbone convolutional neural network into a compact fixed-length representation. Last, inspired by the fact that facial expressions are mainly defined by facial action units, we propose a region biased loss to encourage high attention weights for the most important regions. We validate our RAN and region biased loss on both our built test datasets and four popular datasets: FERPlus, AffectNet, RAF-DB, and SFEW. Extensive experiments show that our RAN and region biased loss largely improve the performance of FER with occlusion and variant pose. Our method also achieves state-of-the-art results on FERPlus, AffectNet, RAF-DB, and SFEW. Code and the collected test data will be publicly available.